目录
一、Generative Adversarial Nets
1. GAN简介
对抗生成网络(GAN)同时训练两个模型:能够得到数据分布的生成模型(generative model G)和能判够区别数据是生成的还是真实的判别模型 (discriminative model D)。训练过程使得G生成的数据尽可能真实,同时又使得D尽可能能够区分生成的数据和真实的数据,最终G生成数据足以以假乱真,而D输出数据的概率均为0.5 。 参考论文:Bengio大神的 Generative Adversarial Networks
2. GAN训练过程

注意:这里的loss在更新D梯度是上升方向,在caffe具体实现时,为了使得D模型梯度更新为梯度的下降方向,loss等价改为:
二、Deep Convolutional GANs (DCGAN)
1. DCGAN 网络结构
DCGAN 用卷积神经(CNN)代替GAN中用多层感知器(MLP)实现D和G,后生成图片效果显著提升。参考论文Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Neworks
- DCGAN网络结构图
- DCGAN结构内容
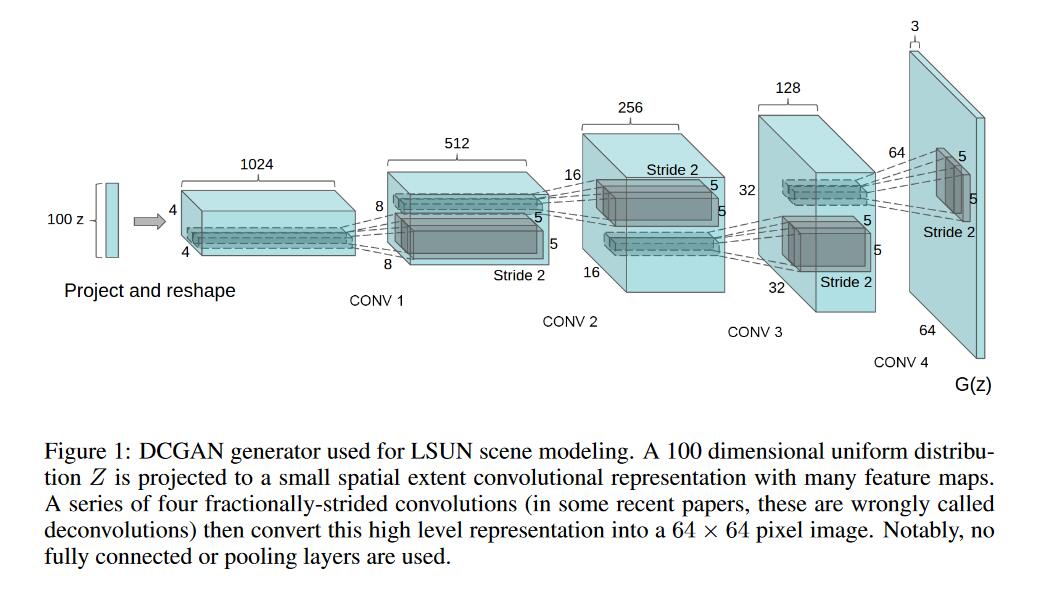

2. DCGAN caffe prototxt
1.train.prototxt
# Create on: 2016/10/22 ShanghaiTech
# Author: Yingying Zhang
name: "gan_newface"
layer {
name: "images"
type: "ImageData"
top: "face_images"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: [127.5]
scale: 0.00784314
}
image_data_param {
source: "data/face_data.txt"
root_folder: "data/"
batch_size: 128
new_height: 64
new_width: 64
is_color: true
shuffle: true
}
}
layer {
name: "rand_vec"
type: "RandVec"
top: "rand_vec"
rand_vec_param {
batch_size: 128
dim: 100
lower: -1.0
upper: 1.0
repeat: 3
}
}
layer {
name: "silence"
type: "Silence"
bottom: "label"
}
#----------- generative -----------
layer {
name: "ip1"
type: "InnerProduct"
bottom: "rand_vec"
top: "ip1"
param {
name: "ip_w_g"
lr_mult: 1
}
param {
name: "ip_b_g"
lr_mult: 2
}
inner_product_param{
num_output: 16384
gen_mode: true
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "ip1_reshape"
type: "Reshape"
bottom: "ip1"
top: "ip1_reshape"
reshape_param {
shape {
dim: 0
dim: 1024
dim: 4
dim: 4
}
}
}
layer {
name: "batch_norm_g1"
type: "BatchNorm"
bottom: "ip1_reshape"
top: "ip1_reshape"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_g1"
type: "Scale"
bottom: "ip1_reshape"
top: "ip1_reshape"
param {
name: "gen_s1"
lr_mult: 1
decay_mult: 1
}
param {
name: "gen_b1"
lr_mult: 1
decay_mult: 1
}
scale_param {
bias_term: true
gen_mode: true
}
}
layer {
name: "relu_g1"
type: "ReLU"
bottom: "ip1_reshape"
top: "ip1_reshape"
}
layer {
name: "gen_conv2"
type: "Deconvolution"
bottom: "ip1_reshape"
top: "gen_conv2"
param {
name: "gen_w_2"
lr_mult: 1
}
param {
name: "gen_b_2"
lr_mult: 2
}
convolution_param {
num_output: 512
pad: 2
kernel_size: 5
stride: 2
gen_mode: true
shape_offset: [1, 1]
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_g2"
type: "BatchNorm"
bottom: "gen_conv2"
top: "gen_conv2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_g2"
type: "Scale"
bottom: "gen_conv2"
top: "gen_conv2"
param {
name: "gen_s2"
lr_mult: 1
decay_mult: 1
}
param {
name: "gen_b2"
lr_mult: 1
decay_mult: 1
}
scale_param {
gen_mode: true
bias_term: true
}
}
layer {
name: "relu_g2"
type: "ReLU"
bottom: "gen_conv2"
top: "gen_conv2"
}
layer {
name: "gen_conv3"
type: "Deconvolution"
bottom: "gen_conv2"
top: "gen_conv3"
param {
name: "gen_w_3"
lr_mult: 1
}
param {
name: "gen_b_3"
lr_mult: 2
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
stride: 2
gen_mode: true
shape_offset: [1, 1]
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_g3"
type: "BatchNorm"
bottom: "gen_conv3"
top: "gen_conv3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_g3"
type: "Scale"
bottom: "gen_conv3"
top: "gen_conv3"
param {
name: "gen_s3"
lr_mult: 1
decay_mult: 1
}
param {
name: "gen_b3"
lr_mult: 1
decay_mult: 1
}
scale_param {
gen_mode: true
bias_term: true
}
}
layer {
name: "relu_g3"
type: "ReLU"
bottom: "gen_conv3"
top: "gen_conv3"
}
layer {
name: "gen_conv4"
type: "Deconvolution"
bottom: "gen_conv3"
top: "gen_conv4"
param {
name: "gen_w_4"
lr_mult: 1
}
param {
name: "gen_b_4"
lr_mult: 2
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
stride: 2
gen_mode: true
shape_offset: [1, 1]
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_g4"
type: "BatchNorm"
bottom: "gen_conv4"
top: "gen_conv4"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_g4"
type: "Scale"
bottom: "gen_conv4"
top: "gen_conv4"
param {
name: "gen_s4"
lr_mult: 1
decay_mult: 1
}
param {
name: "gen_b4"
lr_mult: 1
decay_mult: 1
}
scale_param {
gen_mode: true
bias_term: true
}
}
layer {
name: "relu_g4"
type: "ReLU"
bottom: "gen_conv4"
top: "gen_conv4"
}
layer {
name: "gen_conv5"
type: "Deconvolution"
bottom: "gen_conv4"
top: "gen_conv5"
param {
name: "gen_w_5"
lr_mult: 1
}
param {
name: "gen_b_5"
lr_mult: 2
}
convolution_param {
num_output: 3
pad: 2
kernel_size: 5
stride: 2
gen_mode: true
shape_offset: [1, 1]
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "tanh_g5"
type: "TanH"
bottom: "gen_conv5"
top: "gen_conv5"
}
#----------- gan gate ------------
layer {
name: "gan_gate"
type: "GANGate"
bottom: "face_images"
bottom: "gen_conv5"
top: "dis_input"
}
#----------- discrimitive -----------
layer {
name: "dis_conv_d1"
type: "Convolution"
bottom: "dis_input"
top: "dis_conv_d1"
param {
name: "dis_w_1"
lr_mult: 1
}
param {
name: "dis_b_1"
lr_mult: 2
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
stride: 2
dis_mode: true
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_d1"
type: "BatchNorm"
bottom: "dis_conv_d1"
top: "dis_conv_d1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_d1"
type: "Scale"
bottom: "dis_conv_d1"
top: "dis_conv_d1"
param {
name: "dis_s1"
lr_mult: 1
decay_mult: 1
}
param {
name: "dis_b1"
lr_mult: 1
decay_mult: 1
}
scale_param {
dis_mode: true
bias_term: true
}
}
layer {
name: "relu_d1"
type: "ReLU"
bottom: "dis_conv_d1"
top: "dis_conv_d1"
relu_param {
negative_slope: 0.2
}
}
layer {
name: "dis_conv_d2"
type: "Convolution"
bottom: "dis_conv_d1"
top: "dis_conv_d2"
param {
name: "dis_w_2"
lr_mult: 1
}
param {
name: "dis_b_2"
lr_mult: 2
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
stride: 2
dis_mode: true
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_d2"
type: "BatchNorm"
bottom: "dis_conv_d2"
top: "dis_conv_d2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_d2"
type: "Scale"
bottom: "dis_conv_d2"
top: "dis_conv_d2"
param {
name: "dis_s2"
lr_mult: 1
decay_mult: 1
}
param {
name: "dis_b2"
lr_mult: 1
decay_mult: 1
}
scale_param {
dis_mode: true
bias_term: true
}
}
layer {
name: "relu_d2"
type: "ReLU"
bottom: "dis_conv_d2"
top: "dis_conv_d2"
relu_param {
negative_slope: 0.2
}
}
layer {
name: "dis_conv_d3"
type: "Convolution"
bottom: "dis_conv_d2"
top: "dis_conv_d3"
param {
name: "dis_w_3"
lr_mult: 1
}
param {
name: "dis_b_3"
lr_mult: 2
}
convolution_param {
num_output: 512
pad: 2
kernel_size: 5
stride: 2
dis_mode: true
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_d3"
type: "BatchNorm"
bottom: "dis_conv_d3"
top: "dis_conv_d3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_d3"
type: "Scale"
bottom: "dis_conv_d3"
top: "dis_conv_d3"
param {
name: "dis_s3"
lr_mult: 1
decay_mult: 1
}
param {
name: "dis_b3"
lr_mult: 1
decay_mult: 1
}
scale_param {
dis_mode: true
bias_term: true
}
}
layer {
name: "relu_d3"
type: "ReLU"
bottom: "dis_conv_d3"
top: "dis_conv_d3"
relu_param {
negative_slope: 0.2
}
}
layer {
name: "dis_conv_d4"
type: "Convolution"
bottom: "dis_conv_d3"
top: "dis_conv_d4"
param {
name: "dis_w_4"
lr_mult: 1
}
param {
name: "dis_b_4"
lr_mult: 2
}
convolution_param {
num_output: 1024
pad: 2
kernel_size: 5
stride: 2
dis_mode: true
weight_filler {
type: "gaussian"
std: 0.02
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "batch_norm_d4"
type: "BatchNorm"
bottom: "dis_conv_d4"
top: "dis_conv_d4"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "scale_batch_d4"
type: "Scale"
bottom: "dis_conv_d4"
top: "dis_conv_d4"
param {
name: "dis_s4"
lr_mult: 1
decay_mult: 1
}
param {
name: "dis_b4"
lr_mult: 1
decay_mult: 1
}
scale_param {
dis_mode: true
bias_term: true
}
}
layer {
name: "relu_d4"
type: "ReLU"
bottom: "dis_conv_d4"
top: "dis_conv_d4"
relu_param {
negative_slope: 0.2
}
}
layer {
name: "score"
type: "InnerProduct"
bottom: "dis_conv_d4"
top: "score"
param {
name: "score_w"
lr_mult: 1
}
param {
name: "score_b"
lr_mult: 2
}
inner_product_param{
num_output: 1
dis_mode: true
weight_filler {
type: "gaussian"
std: 0.0002
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "sigmoid"
type: "Sigmoid"
bottom: "score"
top: "score"
}
layer {
name: "gan_loss"
type: "GANDGLoss"
bottom: "score"
top: "gan_loss"
gan_loss_param {
dis_iter: 1
gen_iter: 2
}
}2.solver.prototxt
# Create on: 2016/10/22 ShanghaiTech
# Author: Yingying Zhang
net: "gan_configs/train.prototxt"
debug_info: false
display: 10
solver_type: ADAM
average_loss: 100
base_lr: 2e-4
lr_policy: "fixed"
max_iter: 15000
momentum: 0.5
snapshot: 100
gan_solver: true
snapshot_prefix: "models/gan_"
3.生成结果

未完待续!!!第二部分为caffe具体源码!