Temporal Generative Adversarial Nets with Singular Value Clipping
本篇论文中作者提出了一种新的生成对抗网络——TGAN,它可以学习无标签视频数据集中的语义表示并产生新的视频,不同于已有的用3D反卷积生成器生成视频的视频生成器,TGAN由两个生成器构成:temporal generator 

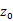
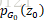

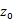
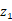
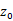
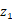
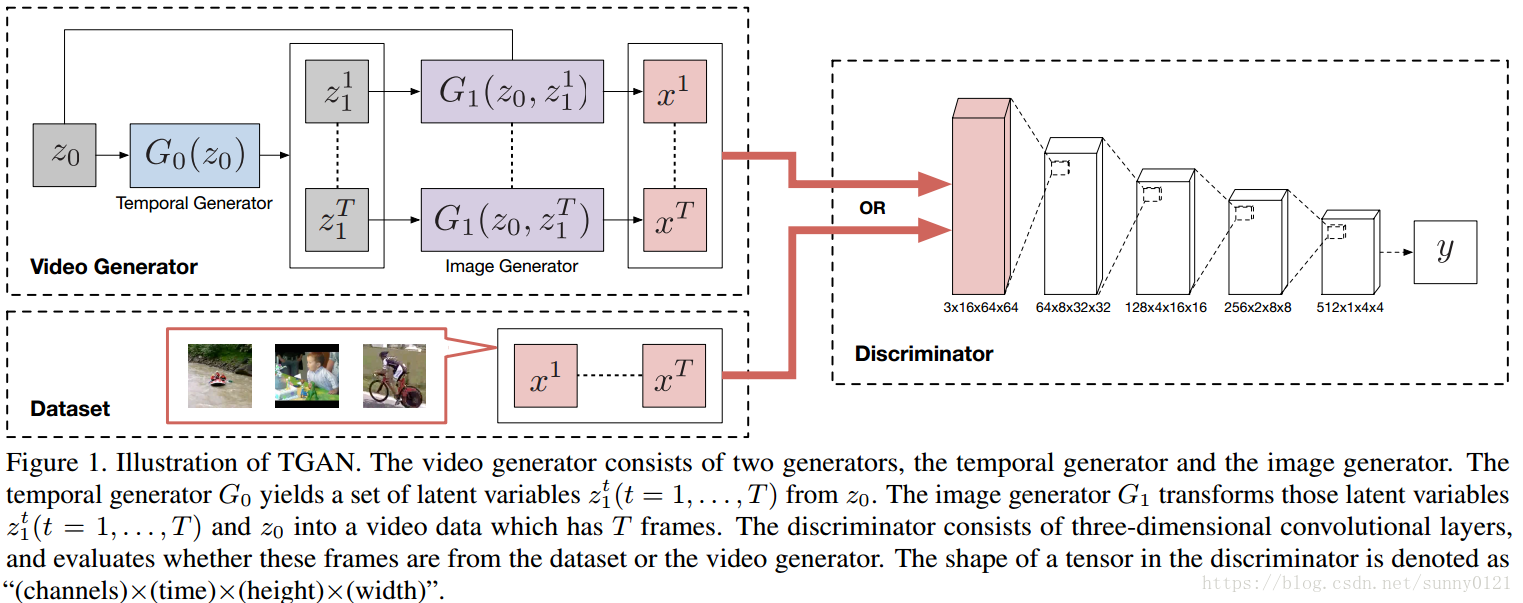
生成器的网络配置如下,判别器的网络配置见上图:

损失函数:

其中
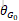


因为WGAN中,判别器要满足K-Lipschitz约束,原则上说提出的模型应该满足所有的K,但是在K=1时,不管判别器的层数有多少,求导操作都是不变的,所以论文将目光集中在K=1上。为了满足1-Lipschtz约束,需要在判别器上的线性层添加约束,使得权值矩阵的奇异值小于等于1,为了达到这个目的,需要在参数更新后执行奇异值分解,并对于大于等于1的用1代替。同样的方法
在卷积层也需要应用。但是有个缺点,就是计算花销会增大,但可以通过减少执行SVC的频率缓解。算法如下:

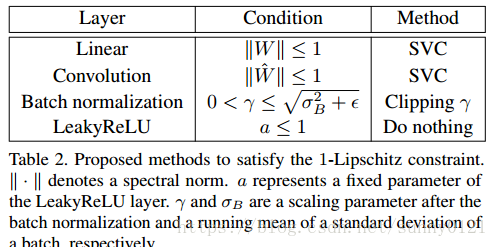
上图是各层的分割方法。需要注意的是ReLU以及LeakyReLu层不执行任何的分割操作,是因为总是满足条件a<=1,除非LeakyReLu中的a小于1.
应用:帧插值(frame interpolation)以及条件TGAN(CTGAN)
introduction summary:
在计算机视觉任务中有两大目标:图像和视频,其中用GAN已经能生成逼真的图像,但是无标签视频的videos生成仍是一个巨大的挑战,虽然有些研究将视频数据分解成前景生成和背景生成来解决这个问题,但是因为假设背景是静态的,因而无法生成动态的背景。也有一些简单的方法使用3D反卷积表示视频的生成,但是却没有用到视频中重要的时间维度,因而也存在生成问题。作者提出了TGAN来解决这个问题,为解决训练不稳定问题,在TGAN中使用了WGAN,因TGAN对WGAN的参数敏感,将权值分割方法用SVC方法代替。
实验结果:
1、定性评估
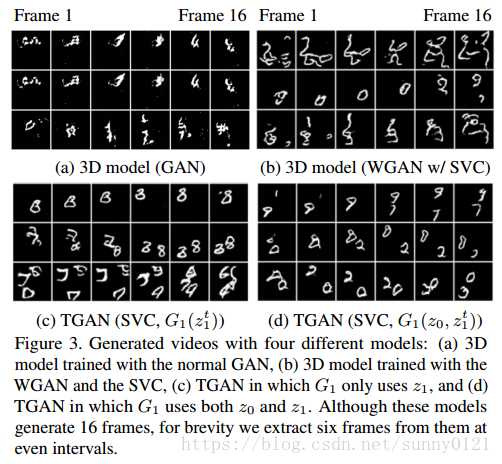

应用实验:

从图6中可以看到,简单的插值算法没有生成中间帧,但是在语义上插入了相邻帧。从图7看到CTGAN生成的视频之类从语义上来说要高于无监督。
2、定量评估
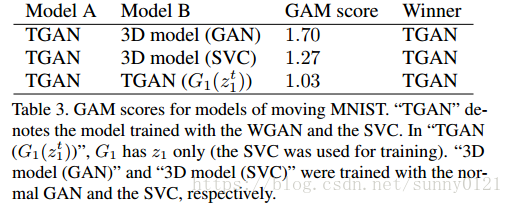
GAM(Generative adveradversarial metric)分数高于后者,表示前面的模型要优于后者。可以看到TGA模型相比来说要优。
