开门见山
最近吧,迷上了看电影。(事先声明,我并不是拖更去看的电影,emmm我自己都不信)

所以今儿我们来抓取猫眼电影 Top 100 榜单中所有的电影信息。
工具篇:
依旧是我们的老伙伴,PyCharm 和 Google 浏览器,同时python 版本为3.6.6
新手村村长发布的任务:
· 抓取 Top 100 榜单

· 输入爬取的起始页:2
· 输入爬取的终止页:7
· 获取 Top 100 榜单里指定范围内的全部电影的电影名称,主演信息,上映时间,并存储到 csv 文件当中
预期运行结果:
工程目录下会出现一个 csv 文件
努力刷电影,勤勉做鸽子
教学开始:
第一步:打开 PyCharm
第二步,打开 猫眼电影
第三步,泡壶茶看会电影,低俗小说 是真的好看
第四步,回到正题
抓取猫眼榜单,我们要分 4步走:
1、抓取 Top 100 榜单
2、进行翻页操作
3、获取所有电影的电影名称,主演信息,上映时间
4、将上述三个信息存储到 csv 文件当中
此次项目,依然用面向对象来完成。面向对象有些忘记的小伙伴可以看看复习一下哟
友好的基础教学环节 双 开始了,本次是正则表达式,源代码在最后哟!加油加油,我是最胖的,给自己打个气。
一、Python 中的 re 模块
正则表达式的规则~
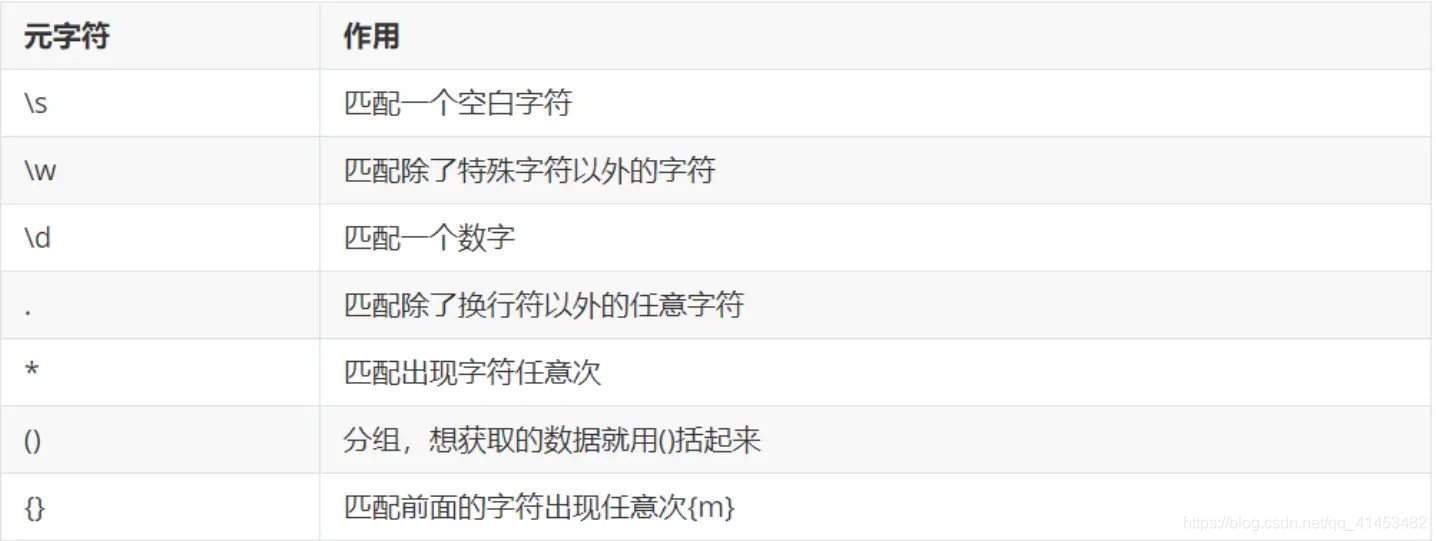
1)match()
match():尝试从字符串的开头进行正则表达式的匹配。如果匹配成功,返回结果;如果匹配失败,则返回 None.
可以说,match() 函数中放的是你所制定的规则,你要它匹配啥样的,它就乖乖匹配啥样的。当然前提是你规则对了【小声哔哔】
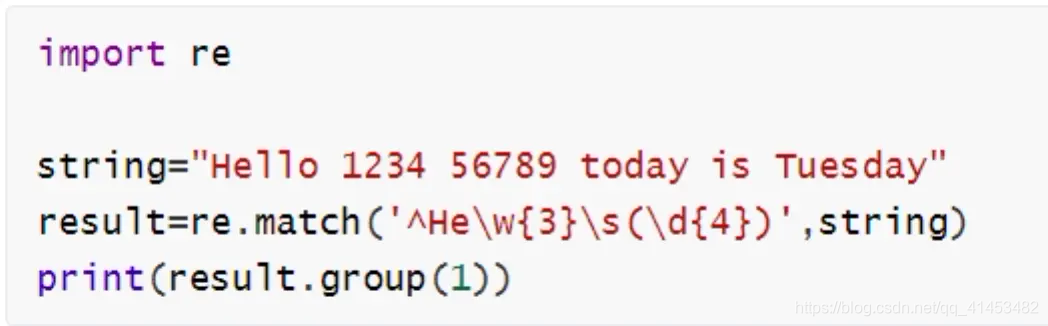
示例代码:
运行结果:
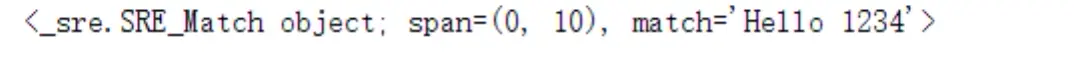
最好对照上面的表看哟
2).* 方法
“.” :匹配除换行符外的任意字符
“*“ :匹配出现任意次
所以组合起来,“.*”就可以代表匹配任意字符
懒癌晚期患者最喜欢的方法没有之一
示例代码:

运行结果:

3)贪婪匹配与非贪婪匹配
贪婪匹配(.*):在正则表达式匹配成功的前提下,尽可能多的匹配
非贪婪匹配(.*?):在正则表达式匹配成功的前提下,尽可能少的匹配
一个是勤快的人,另一个是我。能少干点就少干点bia~
示例代码:

运行结果:
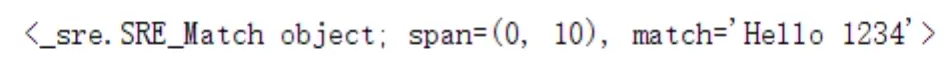
4)search()
search():扫描整个字符串,找到符合正在表达式的第一个字符,并返回结果。
示例代码:

运行结果:

在这里提一嘴,在正则表达式中,group() 是用来提出分组截获的字符串的,group() 就是匹配正则表达式整体结果
5)findall()
findall():扫描整个字符串,返回符合正则表达式的字符串列表
示例代码:
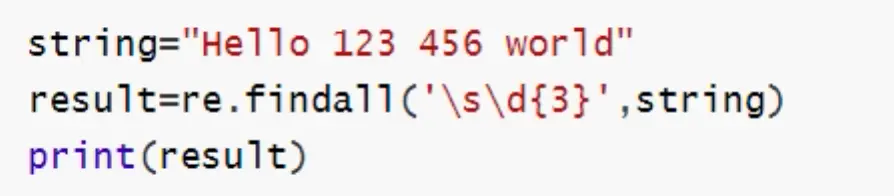
运行结果:

6)compile()
compile():将字符串编译为正则表达式对象
示例代码:
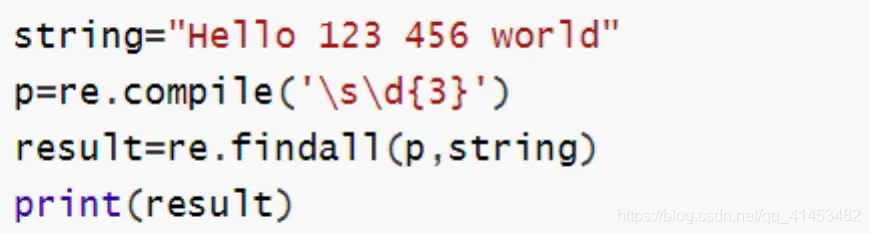
运行结果:
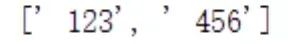
二、正则表达式在网页中使用
刚刚说了那么多 re模块里的东西,这个正则表达式到底怎么在网页中使用呢。
别急,我们来举个栗子!
首先,我们打开了猫眼网页

在右上角的

这里面,找到开发者工具,快捷键是 Ctrl + Shift + I
使用后,会发现你的页面变成了这样。

是的,没有错!这里就是我们网站的源代码,而我们的信息也都是从这上面爬取的。
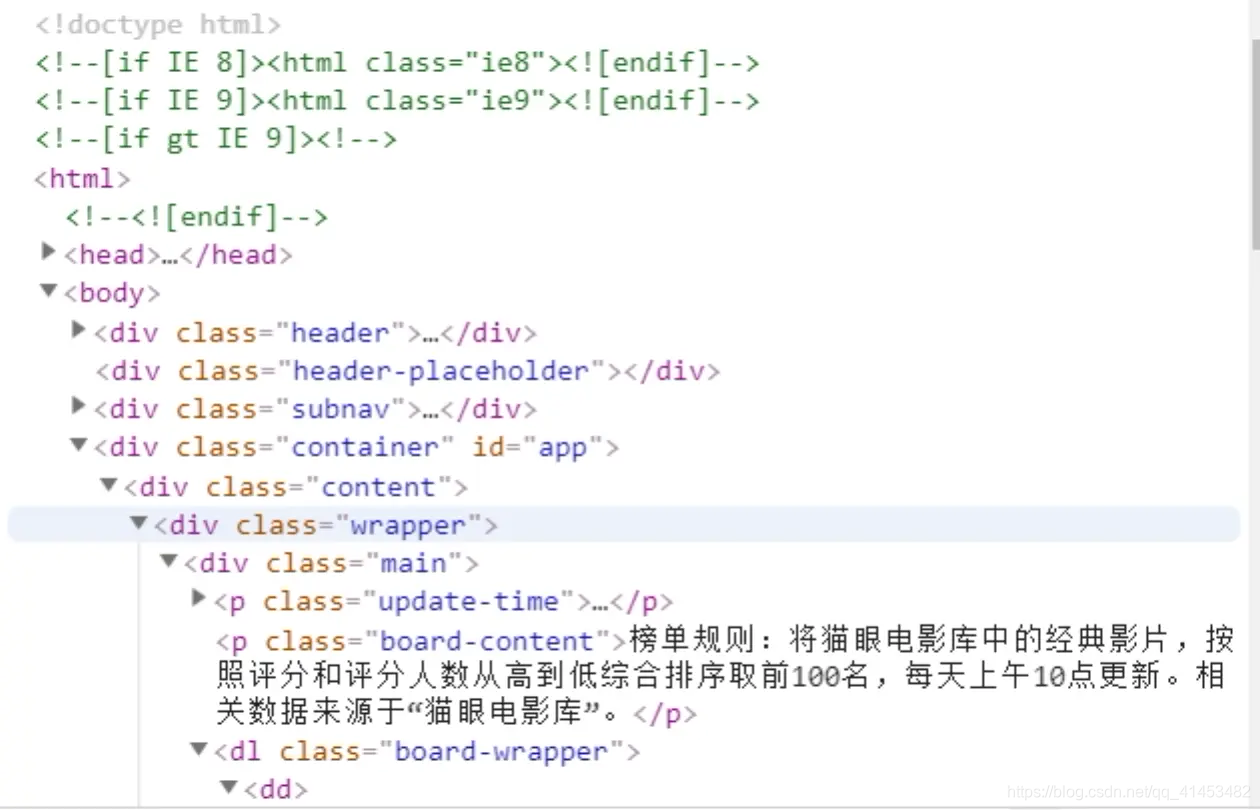
Question:

倘若我想找到这个信息的源代码,去哪里找呢?
Answer:
1)点击你源代码页面左上角的鼠标图案

2)选中你要查看的信息
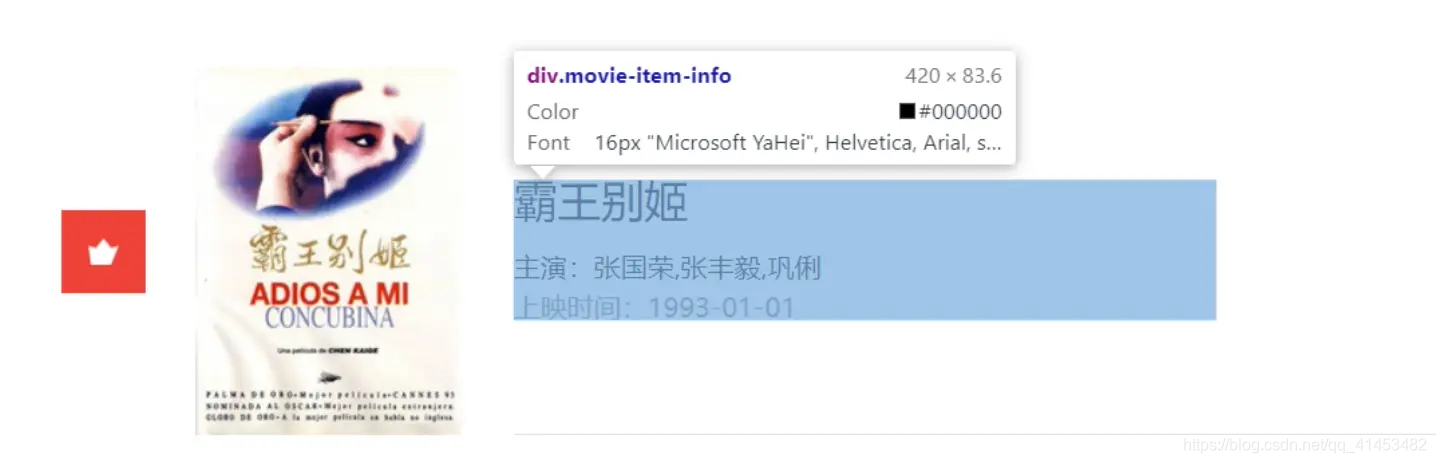
3)在源代码中,有一个区域变成了蓝色,是的!它就是你苦苦找寻的代码,大明湖畔的夏雨荷

我们把这段代码 复制 粘贴下来,做个分析。
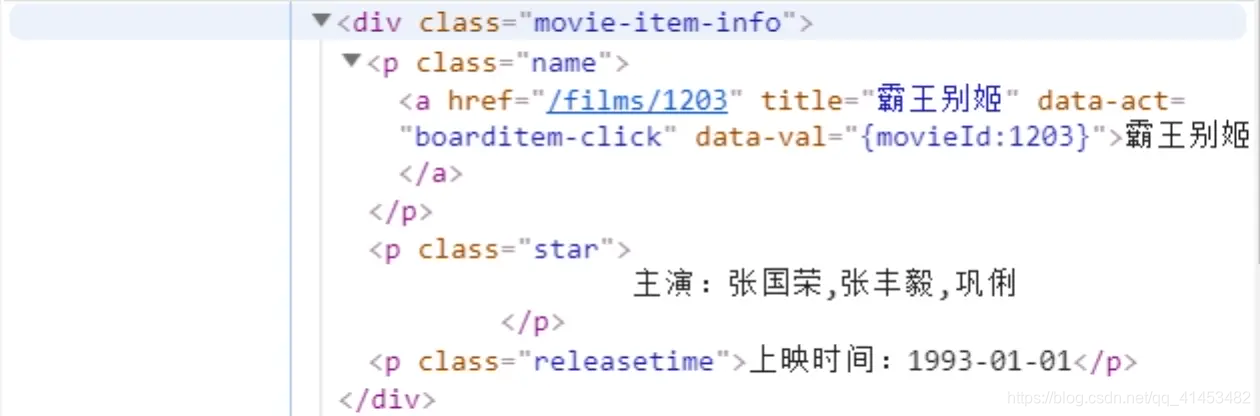
你会发现,我们所要的信息都在这里
【示例代码】

【运行结果】

三、csv 模块的使用
1)普通文本文件操作
【示例代码】

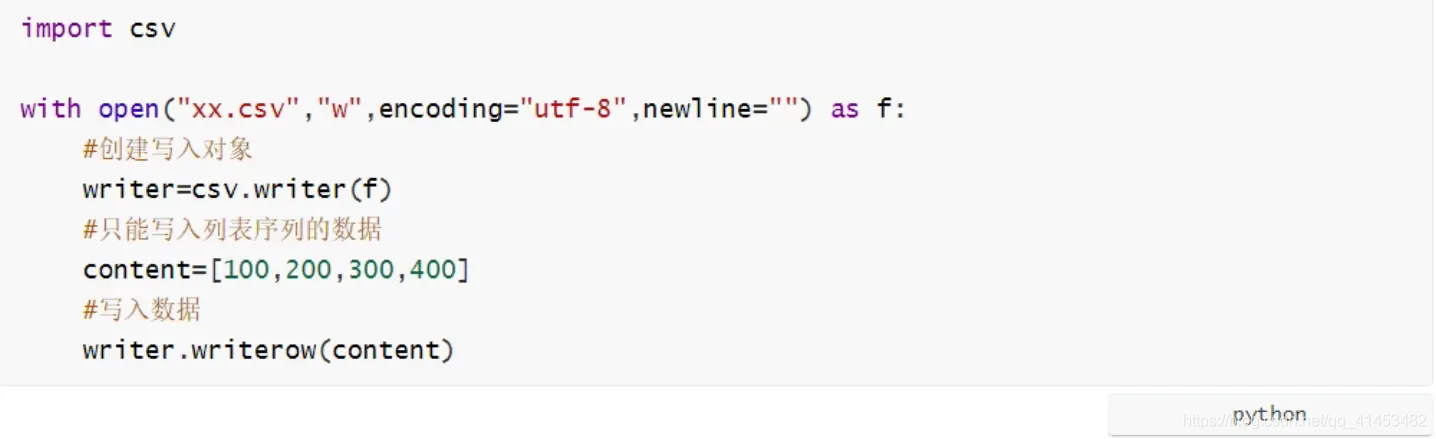
2)csv 文件的操作
【示例代码】
四、爬取猫眼电影榜单
【示例代码】


【教学分析】
1)__init__():构造函数

确立基本 url 路线和爬虫头:https://maoyan.com/board/4
4 指的是 Top 100 榜
2)get_html():获取网页源代码

3)change_page():翻页

offset 用于控制页面,在爬取百度贴吧时说过
4)get_info():提取我们要的信息

5)save_info():保存为csv文件

【运行结果】

好了,到这里教学也就结束了。
接下来,我说几句批话。
首先,我先道个歉,各种事情纠缠拖了这么久,挺对不起各位读者的。
没多少人看,先给自己定个小目标吧。点赞过百,我周更,以民族起誓卓某人说到做到。
源代码奉上:
import urllib.request
import re
import csv
class Maoyan_movie():
def __init__(self):
self.base_url="https://maoyan.com/board/4?"
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
def get_html(self,url): #获取网页源代码的函数
req=urllib.request.Request(url,headers=self.headers)
res=urllib.request.urlopen(req)
html=res.read().decode("utf-8")
self.get_info(html) #调用解析函数获取数据
def change_page(self):
begin=int(input("请输入爬取的起始页:"))
end=int(input("请输入爬取的终止页:"))
for page in range(begin,end+1):
offset=(page-1)*10 #得到控制页数的参数
url=self.base_url+"offset="+str(offset)
self.get_html(url) #调用上层函数获取网页源代码
def get_info(self,html): #解析网页中数据的函数
p = re.compile('<div class="movie-item-info">.*?title="(.*?)".*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>',re.S)
result = re.findall(p,html)
self.save_info(result) #调用保存数据函数
def save_info(self,result):#保存数据的函数
for i in result:
name=i[0].strip() #strip()可以去掉字符串两边的空白字符以及换行符
star=i[1].strip()
time=i[2].strip()
content=[name,star,time] #将三条数据合并为一个列表,以便写入csv文件
with open("movie.csv","a",encoding="utf-8",newline="") as f:
writer=csv.writer(f)
writer.writerow(content)
maoyan=Maoyan_movie()
maoyan.change_page()