版权声明:如需转载,请与我联系。WX:reborn0502 https://blog.csdn.net/gaifuxi9518/article/details/80828999
本篇博文是自己在学习崔庆才的《Python3网络爬虫开发实战教程》的学习笔记系列,如果你也要这套视频教程的话,加我WX吧:reborn0502,然后我私信给你百度云链接,公然放出来不太好~
1.前言
本次练习的一个实战项目是抓取猫眼电影官网的一个TOP100电影榜单,获取每部电影的片名,主演,上映日期,评分和封面等内容,并将这些信息写入Excel文件。
与书中所举的例子有些不同,写入Excel是我自己加入的一个步骤,另外还有一点,书中解析信息用的是正则表达式,而我用的是BeautifulSoup,虽然我觉得自己的代码有些冗余了,但也同样能达到相同的效果。
2.思路步骤
- 分析链接结构(因为有分页),页面结构
- 用requests进行页面信息的抓取
- 用BeautifulSoup进行页面信息的解析提取
- 用openpyxl将信息整理到Excel表格
3.源码分享
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests,openpyxl,pprint
#1.分析链接结构(因为有分页),页面结构
'''
1.此榜单共分为10页,每页展示10部电影,每部电影有6部分信息(排名,片名,主演,时间,封面,评分)
2.链接结构为http://maoyan.com/board/4?offset=0,只需要更改offset的值就可以,第一页是0,第二页是10,....以此类推第10页为90
'''
#2.用requests进行页面信息的抓取
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
res = requests.get(url,headers=headers)
if res.status_code == 200:
return res.text
else:
return None
except RequestException:
return None
movies = {}
movie = {}
#3.用BeautifulSoup进行页面信息的解析提取
for num in range(0,100,10):
text = get_one_page('http://maoyan.com/board/4?offset='+str(num))
beau = BeautifulSoup(text,'lxml')
for i in range(0,10):
#获取排名
elemsIndex = beau.select('.board-index')[i]
movieIndex = elemsIndex.getText()
#获取电影名
elemsName = beau.select('.board-img')[i]
movieName = elemsName.attrs['alt']
#获取主演
elemsStar = beau.select('.star')[i]
movieStar = elemsStar.getText().strip().lstrip('主演:')
#获取上映日期及地点
elemsDate = beau.select('.releasetime')[i]
movieDate = elemsDate.getText().strip().lstrip('上映时间:')
#获取评分
elemsScoreInteger = beau.select('.integer')[i]
elemsScoreFraction = beau.select('.fraction')[i]
movieScore = str(elemsScoreInteger.getText())+str(elemsScoreFraction.getText())
#获取封面图
elemsCover = beau.select('.board-img')[i]
movieCover = elemsCover.attrs['data-src'].rstrip('@160w_220h_1e_1c')
movie = {
'name':movieName,
'star':movieStar,
'date':movieDate,
'score':movieScore,
'cover':movieCover
}
movies[movieIndex] = movie
#4.用openpyxl将信息整理到Excel表格
wb = openpyxl.load_workbook('movies.xlsx')
sheet = wb.get_sheet_by_name('Sheet1')
for i in range(2,len(movies)+2):
sheet['A'+str(i)] = i-1
sheet['B'+str(i)] = movies[str(i-1)]['name']
sheet['C'+str(i)] = movies[str(i-1)]['date']
sheet['D'+str(i)] = movies[str(i-1)]['star']
sheet['E'+str(i)] = movies[str(i-1)]['score']
sheet['F'+str(i)] = movies[str(i-1)]['cover']
wb.save('new.xlsx') 1.此榜单共分为10页,每页展示10部电影,每部电影有6部分信息(排名,片名,主演,时间,封面,评分)
2.链接结构为http://maoyan.com/board/4?offset=0,只需要更改offset的值就可以,第一页是0,第二页是10,....以此类推第10页为90
'''
#2.用requests进行页面信息的抓取
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
res = requests.get(url,headers=headers)
if res.status_code == 200:
return res.text
else:
return None
except RequestException:
return None
movies = {}
movie = {}
#3.用BeautifulSoup进行页面信息的解析提取
for num in range(0,100,10):
text = get_one_page('http://maoyan.com/board/4?offset='+str(num))
beau = BeautifulSoup(text,'lxml')
for i in range(0,10):
#获取排名
elemsIndex = beau.select('.board-index')[i]
movieIndex = elemsIndex.getText()
#获取电影名
elemsName = beau.select('.board-img')[i]
movieName = elemsName.attrs['alt']
#获取主演
elemsStar = beau.select('.star')[i]
movieStar = elemsStar.getText().strip().lstrip('主演:')
#获取上映日期及地点
elemsDate = beau.select('.releasetime')[i]
movieDate = elemsDate.getText().strip().lstrip('上映时间:')
#获取评分
elemsScoreInteger = beau.select('.integer')[i]
elemsScoreFraction = beau.select('.fraction')[i]
movieScore = str(elemsScoreInteger.getText())+str(elemsScoreFraction.getText())
#获取封面图
elemsCover = beau.select('.board-img')[i]
movieCover = elemsCover.attrs['data-src'].rstrip('@160w_220h_1e_1c')
movie = {
'name':movieName,
'star':movieStar,
'date':movieDate,
'score':movieScore,
'cover':movieCover
}
movies[movieIndex] = movie
#4.用openpyxl将信息整理到Excel表格
wb = openpyxl.load_workbook('movies.xlsx')
sheet = wb.get_sheet_by_name('Sheet1')
for i in range(2,len(movies)+2):
sheet['A'+str(i)] = i-1
sheet['B'+str(i)] = movies[str(i-1)]['name']
sheet['C'+str(i)] = movies[str(i-1)]['date']
sheet['D'+str(i)] = movies[str(i-1)]['star']
sheet['E'+str(i)] = movies[str(i-1)]['score']
sheet['F'+str(i)] = movies[str(i-1)]['cover']
wb.save('new.xlsx')4.抓取效果
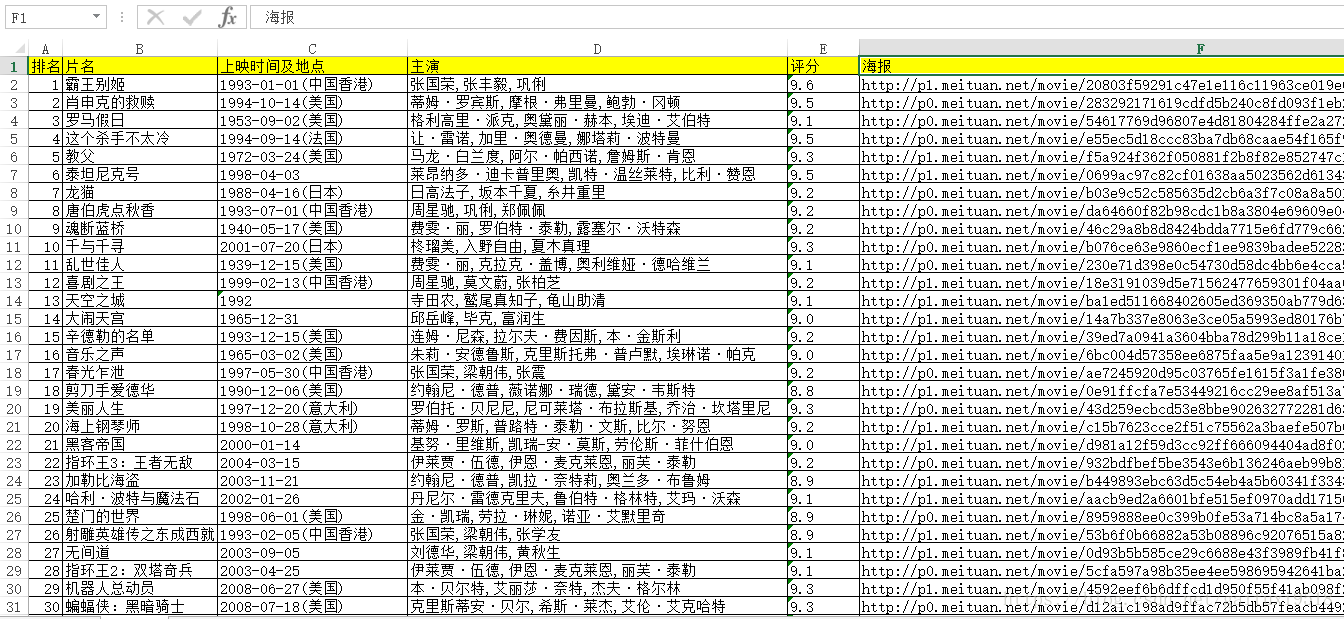
5.官方源码
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)