Bloom Filter简介
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。BF其中的元素越多,false positive rate(误报率)越大,但是false negative (漏报)是不可能的。
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
Bloom Filter的应用
可以用来实现数据字典,进行数据的判重,或者集合求交集。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。
Bloom Filter就被广泛用于拼写检查和数据库系统中。
Bloom Filter在网络领域获得了新生,各种Bloom Filter变种和新的应用不断出现。
集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。

错误率f估计
Note: 这个错误率f是将不属于本集合的元素引进来的概率。如果外集有(u-n)个元素,则有(u-n)f个外元素可能被引进来。
假设:布隆过滤器中的hash function满足simple uniform hashing假设:每个元素都等概率地hash到m个slot中的任何一个,与其它元素被hash到哪个slot无关。
前面我们已经提到了,Bloom Filter在判断一个元素是否属于它表示的集合时会有一定的错误率(false positive rate),下面我们就来估计错误率的大小。在估计之前为了简化模型,我们假设kn<m且各个哈希函数是完全随机的。当集合S={x1, x2,…,xn}的所有元素都被k个哈希函数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:

Note: m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)
其中1/m表示任意一个哈希函数选中这一位的概率(前提是哈希函数是完全随机的),(1-1/m)表示哈希一次没有选中这一位的概率。要把S完全映射到位数组中,需要做kn次哈希。某一位还是0意味着kn次哈希都没有选中它,因此这个概率就是(1-1/m)的kn次方。令p = e-kn/m是为了简化运算,这里用到了计算e时常用的近似:

令ρ为位数组中0的比例,则ρ的数学期望E(ρ)= p’。在ρ已知的情况下,要求的错误率(false positive rate)为:

(1-ρ)为位数组中1的比例,(1-ρ)k就表示k次哈希都刚好选中1的区域,即false positive rate。上式中第二步近似在前面已经提到了,现在来看第一步近似。p’只是ρ的数学期望,在实际中ρ的值有可能偏离它的数学期望值。M. Mitzenmacher已经证明[2] ,位数组中0的比例非常集中地分布在它的数学期望值的附近。因此,第一步的近似得以成立。分别将p和p’代入上式中,得:


相比p’和f’,使用p和f通常在分析中更为方便。
最优的哈希函数个数k
既然Bloom Filter要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
先用p和f进行计算。注意到f = exp(k ln(1 − e−kn/m)),我们令g = ln(f),只要让g取到最小,f自然也取到最小。由于p = e-kn/m,我们可以将g写成

根据对称性法则可以很容易看出当p = 1/2,也就是k = ln2· (m/n)时,g取得最小值。在这种情况下,最小错误率f等于(1/2)^k = ((1/2)^ln2) ^(m/n)≈ (0.6185)^(m/n)。另外,注意到p是位数组中某一位仍是0的概率,所以p = 1/2对应着位数组中0和1各一半。换句话说,要想保持错误率低,最好让位数组有一半还空着。
需要强调的一点是,p = 1/2时错误率最小这个结果并不依赖于近似值p和f。同样对于f’ = exp(k ln(1 − (1 − 1/m)kn)),g’ = k ln(1 − (1 − 1/m)kn),p’ = (1 − 1/m)kn,我们可以将g’写成

同样根据对称性法则可以得到当p’ = 1/2时,g’取得最小值。
位数组的大小m
下面我们来看看,在不超过一定错误率的情况下,Bloom Filter至少需要多少位才能表示全集中任意n个元素的集合。
{表示任意n个元素的集合的最小m数的推导
假设全集中共有u个元素,允许的最大错误率为є,下面我们来求位数组的位数m。
假设X为全集中任取n个元素的集合,F(X)是表示X的位数组。那么对于集合X中任意一个元素x,在s = F(X)中查询x都能得到肯定的结果,即s能够接受x。显然,由于Bloom Filter引入了错误,s能够接受的不仅仅是X中的元素,它还能够接受є (u - n)个false positive。因此,对于一个确定的位数组来说,它能够接受总共n + є (u - n)个元素。在n + є (u - n)个元素中,s真正表示的只有其中n个,所以一个确定的位数组可以表示

个集合。m位的位数组共有2m个不同的组合,进而可以推出,m位的位数组可以表示

个集合。全集中n个元素的集合总共有

个,因此要让m位的位数组能够表示所有n个元素的集合,必须有

即:

上式中的近似前提是n和єu相比很小,这也是实际情况中常常发生的。
根据上式,我们得出结论:在错误率不大于є的情况下,m至少要等于n log2(1/є)才能表示任意n个元素的集合。
}
上一小节中我们曾算出当k = ln2· (m/n)时错误率f最小,这时f = (1/2)^k = (1/2)^((mln2) / n)。现在令f≤є,可以推出

这个结果比前面我们算得的下界n log2(1/є)大了log2 e ≈ 1.44倍。这说明在哈希函数的个数取到最优时,要让错误率不超过є,m至少需要取到最小值的1.44倍。
总结来说就是,当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于є的情况下,m至少要等于n*lg(1/є)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/є)*lge,即m/n = -lnp/(ln2)^2 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子
我们假设错误率为0.01,则此时m应大概是n的9.6倍。这样k大概是7个{6.64个}。 (m应大概是n的13倍。这样k大概是8个。这个计算是错的应该)。
对于一个有1%误报率和一个最优k值的布隆过滤器来说,无论元素的类型及大小,每个元素只需要9.6 bits(m/n=9.6)来存储。这个优点一部分继承自array的紧凑性,一部分来源于它的概率性。如果你认为1%的误报率太高,那么对每个元素每增加4.8 bits {m/n = -ln(p/10)/(ln2)^2 = -lnp/(ln2)^2)+ln(10)/(ln2)^2 = -lnp/(ln2)^2)+4.8},我们就可将误报率降低为原来的1/10。[布隆过滤器 (Bloom Filter) 详解]
[推导参考wikipedia Bloom filter]
设计和应用布隆过滤器的方法
应用时首先要先由用户决定要add的元素数n和希望的误差率P(这里P代表错误率f)。这也是一个设计完整的布隆过滤器需要用户输入的仅有的两个参数,之后的所有参数将由系统计算,并由此建立布隆过滤器。
系统首先要计算需要的内存大小m bits:
![clip_image002[60]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319183767.png)
再由m,n得到hash function的个数:
![clip_image002[52]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319197289.png)
至此系统所需的参数已经备齐,接下来add n个元素至布隆过滤器中,再进行query。
根据公式,当k最优时:
![clip_image002[66]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319209142.png)
![clip_image004[8]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319219566.png)
因此可验证当P=1%时,存储每个元素需要9.6 bits:
![clip_image002[70]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319231320.png)
而每当想将误判率降低为原来的1/10,则存储每个元素需要增加4.8 bits:
![clip_image002[72]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319248745.png)
这里需要特别注意的是,9.6 bits/element不仅包含了被置为1的k位,还把包含了没有被置为1的一些位数。此时的
![clip_image002[74]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319257251.png)
才是每个元素对应的为1的bit位数。
![clip_image002[76]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319253597.png) 从而使得P(error)最小时,我们注意到:
从而使得P(error)最小时,我们注意到:
![clip_image002[78]](http://images.cnblogs.com/cnblogs_com/allensun/201102/20110216231926499.png) 中的
中的 ![clip_image002[80]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319269038.png) ,即
,即![clip_image002[82]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319275940.png)
此概率为某bit位在插入n个元素后未被置位的概率。因此,想保持错误率低,布隆过滤器的空间使用率需为50%。
Bloom Filter的优缺点
优点
1 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(
如果可能元素范围不是很大,并且大多数都在集合中,则使用确定性的bit array远远胜过使用布隆过滤器。因为bit array对于每个可能的元素空间上只需要1 bit,add和query的时间复杂度只有O(1)。注意到这样一个哈希表(bit array)只有在忽略collision并且只存储元素是否在其中的二进制信息时,才会获得空间和时间上的优势,而在此情况下,它就有效地称为了k=1的布隆过滤器。
而当考虑到collision时,对于有m个slot的bit array或者其他哈希表(即k=1的布隆过滤器),如果想要保证1%的误判率,则这个bit array只能存储m/100个元素,因而有大量的空间被浪费,同时也会使得空间复杂度急剧上升,这显然不是space efficient的。解决的方法很简单,使用k>1的布隆过滤器,即k个hash function将每个元素改为对应于k个bits,因为误判度会降低很多,并且如果参数k和m选取得好,一半的m可被置为为1,这充分说明了布隆过滤器的space efficient性。
2 散列函数相互之间没有关系,方便由硬件并行实现。
3 布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
4 布隆过滤器可以表示全集,其它任何数据结构都不能。
5 k和m相同,使用同一组散列函数的两个布隆过滤器的交并差运算可以使用位操作进行。
缺点
但是布隆过滤器的缺点和优点一样明显。
1 误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
2 一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面。这一点单凭这个过滤器是无法保证的。
不允许remove元素,还有因为那样的话会把相应的k个bits位置为0,而其中很有可能有其他元素对应的位。因此remove会引入false negative,这是绝对不被允许的。
3 另外计数器回绕?也会造成问题。在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
4 当add的元素过多时,即n/m过大时(n是元素数,m是bloom filter的bits数),会导致false positive过高,此时就需要重新组建filter,但这种情况相对少见。
Bloom Filter的改进
1 当k很大时,设计k个独立的hash function是不现实并且困难的。对于一个输出范围很大的hash function(例如MD5产生的128 bits数),如果不同bit位的相关性很小,则可把此输出分割为k份。或者可将k个不同的初始值(例如0,1,2, … ,k-1)结合元素,feed给一个hash function从而产生k个不同的数。
2 Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。BF不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以用一个counter数组代替位数组,就可以支持删除了。
3 Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。应该就是[Count-Min Sketch 算法]。
问题示例
1 给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿。n=50亿,如果按出错率0.01算需要的大概是480(*9.6的话应该是480,而不是*13=650)亿个bit。 现在可用的是340亿,相差并不多,这样可能会使出错率上升些。
判断第二个文件中的url有没有在前面第一个文件构造的过滤器中,在就输出。
另外如果这些url ip是一一对应的,就可以转换成ip,则大大简单了。
lz:多个文件时,使用同一组散列函数的n-1个布隆过滤器的交运算,但是此时只知道给出一个url是不是在这里面。所以最后一个文件不再进行交运算,也就是不构造第n个布隆过滤器,而是判断最后一个文件中的url有没有在前面进行交运算的n-1个BF的最终的过滤器中,在就输出。
2 垃圾邮件过滤中黑白名单:现有1亿个email的黑名单,每个都拥有8 bytes的指纹信息。
可能的元素范围为 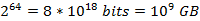 ,对于bit array来说是根本不可能的范围,而且元素的数量(即email列表)为
,对于bit array来说是根本不可能的范围,而且元素的数量(即email列表)为 ![clip_image002[6]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162318586502.png) ,相比于元素范围过于稀疏,而且还没有考虑到哈希表中的collision问题。
,相比于元素范围过于稀疏,而且还没有考虑到哈希表中的collision问题。
若采用哈希表,由于大多数采用open addressing来解决collision,而此时的search时间复杂度为 :
![clip_image002[8]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162318587865.png)
即若哈希表半满(n/m = 1/2),则每次search需要probe 2次,因此在保证效率的情况下哈希表的存储效率最好不超过50%。此时每个元素占8 bytes,总空间为:
![clip_image002[10]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162318595847.png)
若采用Perfect hashing(这里可以采用Perfect hashing是因为主要操作是search/query,而并不是add和remove),虽然保证worst-case也只有一次probe,但是空间利用率更低,一般情况下为50%,worst-case时有不到一半的概率为25%。
若采用布隆过滤器,取k=8。因为n为1亿,所以总共需要 ![clip_image002[12]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162318598289.png) 被置位为1,又因为在保证误判率低且k和m选取合适时,空间利用率为50%,所以总空间为:
被置位为1,又因为在保证误判率低且k和m选取合适时,空间利用率为50%,所以总空间为:
![clip_image002[14]](http://images.cnblogs.com/cnblogs_com/allensun/201102/201102162319009303.png)
所需空间比上述哈希结构小得多,并且误判率在万分之一以下。
from: http://blog.csdn.net/pipisorry/article/details/64127666
ref: [Bloom Filter]*
[谷歌黑板报的数学之美系列二十一 - 布隆过滤器(Bloom Filter)]
[A. Broder and M. Mitzenmacher. Network applications of bloom filters: A survey. Internet Mathematics, 1(4):485–509, 2005.
M. Mitzenmacher. Compressed Bloom Filters. IEEE/ACM Transactions on Networking 10:5 (2002), 604—612.
www.cs.jhu.edu/~fabian/courses/CS600.624/slides/bloomslides.pdf