版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
用这个图为例子
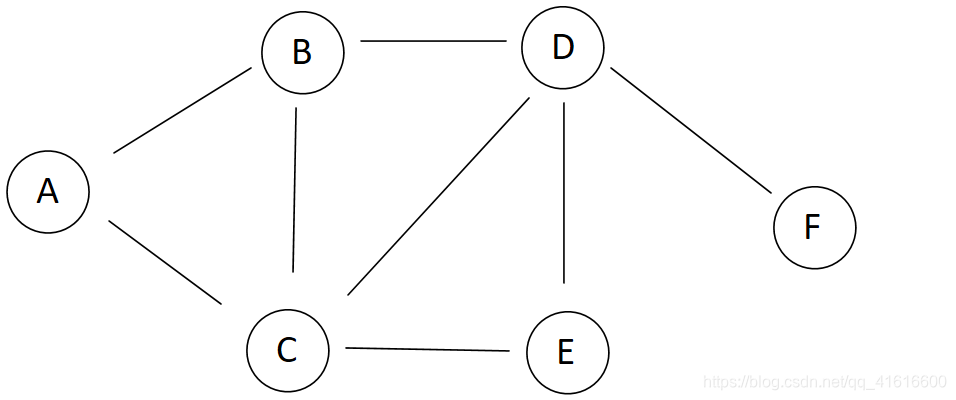
用字典存储这个图
graph = {
'A':['C','B'],
'B':['A','C','D'],
'C':['A','B','E','D'],
'D':['B','C','E','F'],
'E':['C','D'],
'F':['D']
}
广度优先算法的本质是一个队列
def BFS(graph,start):
queue = []
queue.append(start)
seen = set()
seen.add(start)
while len(queue)>0:
vert = queue.pop(0) # 这里表现出是个队列,先进先出
nodes = graph[vert]
for w in nodes:
if w not in seen:
queue.append(w)
seen.add(w)
print(vert)
BFS(graph,'D')
深度优先算法的本质是一个堆栈
def DFS(graph,start):
queue = []
queue.append(start)
seen = set()
seen.add(start)
while len(queue)>0:
vert = queue.pop() # 这里表现出是一个堆栈 ,后进先出
nodes = graph[vert]
for w in nodes:
if w not in seen:
queue.append(w)
seen.add(w)
print(vert)
DFS(graph,'A')