文章目录
一、写作动机与文献来源
- Paper:本文的基础支撑资料来自UCB2018年一名博士的毕业论文:Learning to Learn with Gradients
- 写作动机:元学习入门
- 写作说明:为了方便读者学习,本文将尽可能采用“问题引导”的形式组织结构。
二、摘要
人类在仅仅通过很小的例子来学习新的概念并且快速应用在之间没有见过的情况下的能力很强大。为了做到这一点,人类在自己的先验知识上,为适应能力做准备,将之前的观察和少数的新证据结合起来进行快速学习。然而,在绝大部分的机器学习系统中,都拥有特定的训练和测试阶段:训练包括使用数据来更新模型,在测试阶段,模型被用作僵硬的决策机器。在元学习领域,我们将讨论基于梯度的方法来学习如何学习,来赋予机器类似人类的灵活性。与采用确定的、非适应性的系统不同的是,这些元学习技术显式地进行训练来获取快速适应的能力,因此在测试阶段,他们在面对新的场景的时候往往能够快速地学习。
为了研究“学会如何学习”的问题,我们首先对元学习的问题、术语和与元学习算法的重要特性进行了正式的定义和阐述。在此基础之上,我们展示了一类模型不可知的元学习方法(即对模型细节不了解——model-agnostic),该类方法将基于梯度的最优化过程嵌入学习器中。与之前方法不同的是,这类方法将关注获取可迁移的表征而非是一个好的学习规则。因此,这些方法在从将一个固定的最优化过程/方法(a fixed optimization)作为学习规则(learning rule)中继承许多重要特性的同时,仍然保持了完整的表达性(expressivity),因为学到的表征可以控制更新规则(update rule)。
我们展示了这些方法是如何可以通过将元学习的元素和基于深度模型的强化学习(reinforcement learning)、模仿学习(imitation learning)和逆向强化学习(inverse reinforcement learning)的技术结合起来扩展到电机控制(motor control)的应用上来的。通过这样做,我们建立了可以适应动态环境的模拟代理,它们可以使得真的机器人通过观看一段人类的视频就学会操作新的物体并且允许人类仅仅使用少量的图片就向机器人传达目标。最后,我们通过讨论一些在元学习领域开放的问题和未来的方向来进行总结,以期确定我们现有方法的关键缺陷和限制假设。
三、简述
1.为什么要研究元学习?
现有的机器学习方法都只是关注一个特定的任务,比如语音识别、翻译文本、分类等等,然后训练一个模型(model or policy),端到端地(end-to-end),来从头开始解决该任务("从头开始"指的是随机初始化)。在机器学习领域,端到到地从头开始进行学习似乎已经被奉为金科玉律,因为这不需要有实际领域的具体人类知识或者说专家来解决这个任务。
然而,从真正的人类智能角度来说,让一个系统每次都从头开始学习一个单一的独立的任务是毫无意义的。想象一下,如果一个小孩儿在之前的学习任务中就已经学会了认识汉字,现在新的学习任务要求他写一篇作文,而他在新的任务中表现得就好像之前从来不曾识过字一般(也就是又需要从头开始学习完成新的任务所需要的知识),这合理吗?如果我们想要系统表现出人类智能的普遍性,它们必须在面对每一个新的任务、概念或者环境的时候不都需要海量的数据。
举个例子来说,现有的训练分类器的通用数据集MNIST和CIFAR-10都大概有60000张图片,10个类别。但是这与真正的人类认识世界的需求是不一样的。事实上,与神经网络分别需要10个不同类别的6000个实例来完成学习不同,人类往往是通过6000个不同类别物体的10个实例就能完成认知学习。从多样性的层次上来说,人类能够高效地迁移学习就不是很令人吃惊了。
2.元学习与迁移学习的关系?
迁移学习是机器学习下一个拥有悠久研究历史的子领域,它的目的是学习一种能力,这种能力使得它可以在从新的数据进行学习的时候利用到之前的数据集。可以说,现代的迁移学习中的一个最大的成功就是预训练(pre-training)技术,然后在新任务的数据的基础上进行微调(fine-tuning)。这个技术在ImageNet上使用监督学习作为预训练来初始化用来训练卷积网络已经取得了广泛的成功。 然而,预训练技术也仅仅只是能做到这一步,它们的性能在如果只能使用很少量的样本进行微调的时候就会受到很大的限制。小样本学习(few-shot learning)更具有挑战性,而且考虑到人类具有处理小样本数据的能力,这完全是可能被解决的。
3.当前的元学习方法的分类以及进展
以前的元学习的方法可以被大致分成以下两类:【1】训练大规模黑盒神经网络(large black-box neural network)模型来从数据中进行学习的方法和【2】将已知的最优化过程(known optimization procedure)的结构融合到学习器中的方法。
对于前者而言,一个深度神经网络,比如LSTM[2][3][4][6],一个神经图灵机器[5],或者是使用了记忆(memory)或者循环(recurrence)的模型[7][8],被训练来从输入的数据中进行“学习”。这些模型要么输入一个新的未标记过的数据要求输出其标记[9][10],要么预测另一个能解决该任务的神经网络的权重[11][12][18][19]。这类方法被[13]扩展到强化学习的设定中,学习一个循环神经网络但是并不在多个流程(across episode)中重置隐藏状态(hidden state),因此它可以从之前的过程中进行学习。这些方法已经被应用到解决许多问题。然而,没有任何结构的先验知识,去从头开始学习这些黑盒学习过程(black-box learning procedure)是很困难而且低效率的。
对于后者而言,目前已经有了很多工作尝试将结构融入到元学习过程中。少样本分类中有一类方法就是在一个已经被学习的度量空间(metric space)中去学习如何比较样本,比如:Siamese networks[14]、循环模型[15][16][17]等等。这些方法已经取得了很多成功的结果,但是将其直接扩展到其他问题上(比如强化学习)也是更加困难的。本文将主要讨论融合结构的先验知识来发展具有黑盒方法的通用性的模型,这些模型将与常见术语甚至是常见的问题陈述高度独立。
第一部分. 基础
四、元学习算法的重要特性
本节介绍三个重要特性,但这并不是全部。
4.1.Expressive Power of Meta-Learning Algorithms

4.2.Consistent Learning Algorithms
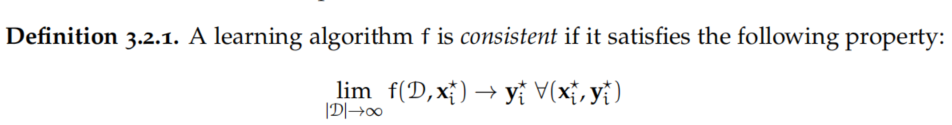
4.3.Handling Ambiguity In Learning
说明: 第四节我们将作者提到的这三个特性简单列出,具体的细节等到我们具体介绍了元学习的主流方法再回过来进行总结。(笔者按:学习总是螺旋上升的)