Nature | 机器学习在药物研发中的应用
2019-06-18 12:48:18 qq2648008726 阅读数 443更多
分类专栏: Chemoinformatics Bioinformatics 机器学习
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://blog.csdn.net/u012325865/article/details/92778433
摘要
药物研发管线漫长、复杂且取决于许多因素。机器学习(ML)通过丰富且高质量的数据改进指定问题的发现和决策。机器学习在药物发现的所有阶段都有应用:靶标验证、生物标志物的鉴定和临床试验中数字病理学数据的分析。应用程序的范围和方法不同,有些方法可以产生准确的预测和解释。应用机器学习的主要挑战在于ML产生的结果缺乏可解释性和可重复性,可能限制其应用。在所有领域,仍然需要生成系统和全面的高维数据。
介绍
生物系统是发育和疾病期间复杂的信息来源。 现在使用大量的“组学”和智能技术系统地测量和挖掘这些信息。针对生物学和疾病的高通量方法的出现为制药业带来了挑战和机遇,其目的是确定可用于开发药物的治疗假设。许多因素的最新进展导致对制药工业中机器学习方法的使用兴趣增加;再加上无限可扩展的存储ML提供基础的数据集类型,增加了制药公司能够访问和组织更多数据的机会。数据类型可以包括图像、文本信息、生物特征、来自可穿戴设备的其他信息和高维组学数据。
人工智能(AI)领域已经从大量的理论研究转向现实世界的应用。这种爆炸性增长的大部分与图形处理单元(GPU)等新计算机硬件的广泛可用性有关。新的ML算法的从数据构建强大的模型以及这些技术在众多公共竞赛中的成功,有助于增加ML在制药公司中的应用。尽管许多消费者服务行业早已采用ML领域的新方法,但制药行业的采用率一直滞后。 众所周知,药物开发的成功率在所有治疗领域和整个制药行业都非常低。最近对21143种化合物的研究发现,总体成功率低至6.2%。 因此,制药行业中使用ML技术的许多理由是由业务需求驱动以降低总体损耗和成本。
药物研发的所有阶段,包括临床试验已着手开发和利用ML算法和软件来识别新靶点,为靶标-疾病关联提供更有力的证据,改进小分子化合物的设计和优化,增加对疾病机制的理解,增加对疾病和非疾病表型的了解,为药物疗效开发新的生物标志物,改进患者监测和可穿戴设备的生物特征和其他数据分析,增强数字病理成像并从图像中提取高含量信息的水平。

许多制药公司已开始投资资源、技术和服务,以生成和策划数据集支持该领域的研究。此外,IBM和谷歌等技术巨头,生物技术初创企业和学术中心不仅提供基于云的计算服务,还与行业合作伙伴一起在制药和医疗保健领域合作。
机器学习工具箱
从根本上说,ML是使用算法解析数据,从数据中学习然后对任何新数据集的未来状态做出决策或预测的实践。 因此,不是使用一组特定指令手动编写软件来完成特定任务,而是使用大量数据和算法对机器进行训练,使其能够学习如何执行任务。程序员编码用于训练网络的算法而不是编码专家规则。
随着可用于学习的数据的数量和质量的增加,算法自适应地改善其性能。 因此,ML最适用于解决大量数据和若干变量即将出现的问题,但与这些问题相关的模型或公式尚不清楚。
ML有两种主要类型的技术:监督和无监督学习。 监督学习方法用于开发训练模型以预测数据类别或连续变量的未来值,而无监督方法用于探索目的以开发能够以用户未指定的方式聚类数据的模型。监督学习训练已知输入和输出数据关系的模型,以便它可以预测新输入的未来输出。 未来的输出通常是数据分类的模型或结果,或者是对最有影响变量的理解。 无监督学习技术识别输入数据中的隐藏模式或内在结构,并使用它们以有意义的方式聚类数据。
模型选择
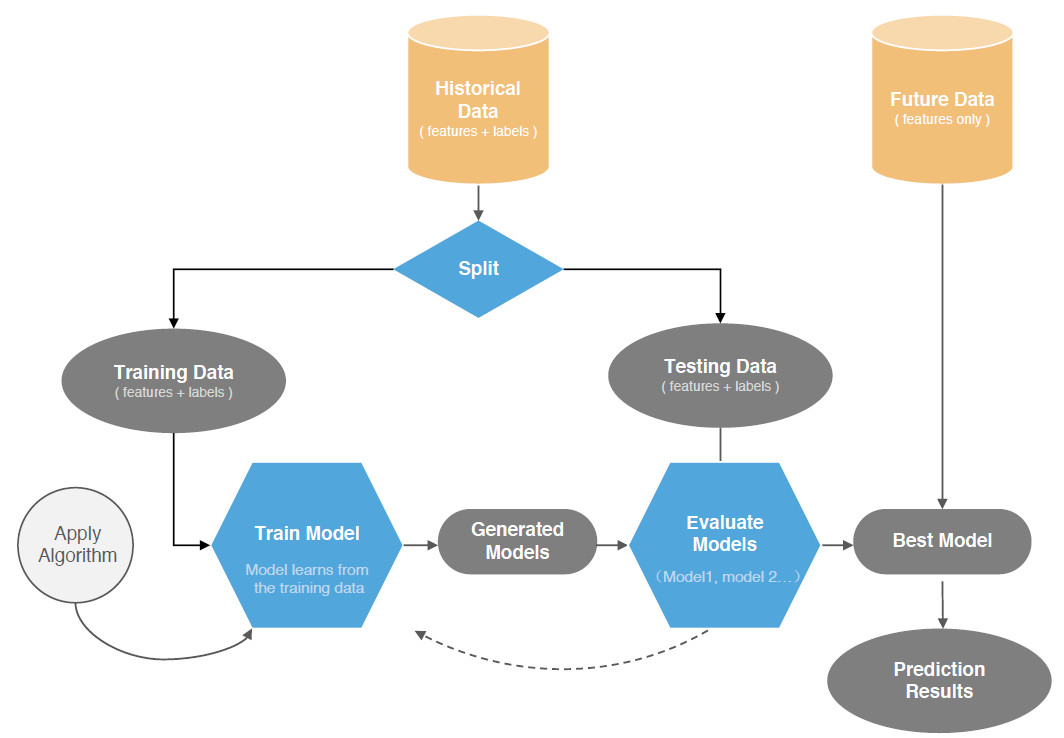
良好ML模型的是从训练数据到测试数据很好地概括。泛化指的是模型学习的概念在训练期间应用于模型未见的数据的程度。每种技术中存在几种方法,它们的预测准确度、训练速度和它们可以处理的变量的数量不同。 必须仔细选择算法,以确保适合于眼前的问题以及可用数据的数量和类型。所需的参数调整量以及该方法将信号与噪声分离的程度也是重要的考虑因素。
当模型不仅学习信号而且学习训练数据的一些不寻常特征并将这些特征结合到模型中时,模型过度拟合发生,从而对模型在新数据上的性能产生负面影响。欠拟合指的是既不能对训练数据建模也不能推广到新数据的模型。限制过度拟合的典型方法是应用重采样方法或阻止部分训练数据用作验证数据集。随着模型复杂性的增加,正则化回归方法会增加参数的惩罚,从而迫使模型推广数据而不是过度拟合。避免过度拟合的最有效方法之一是dropout方法,它随机删除隐藏层中的单位。不同的ML技术具有不同的性能指标。基本评估指标,如分类准确度、曲线下面积(AUC),对数损失和混淆矩阵可用于比较各种方法的性能。
数据特征
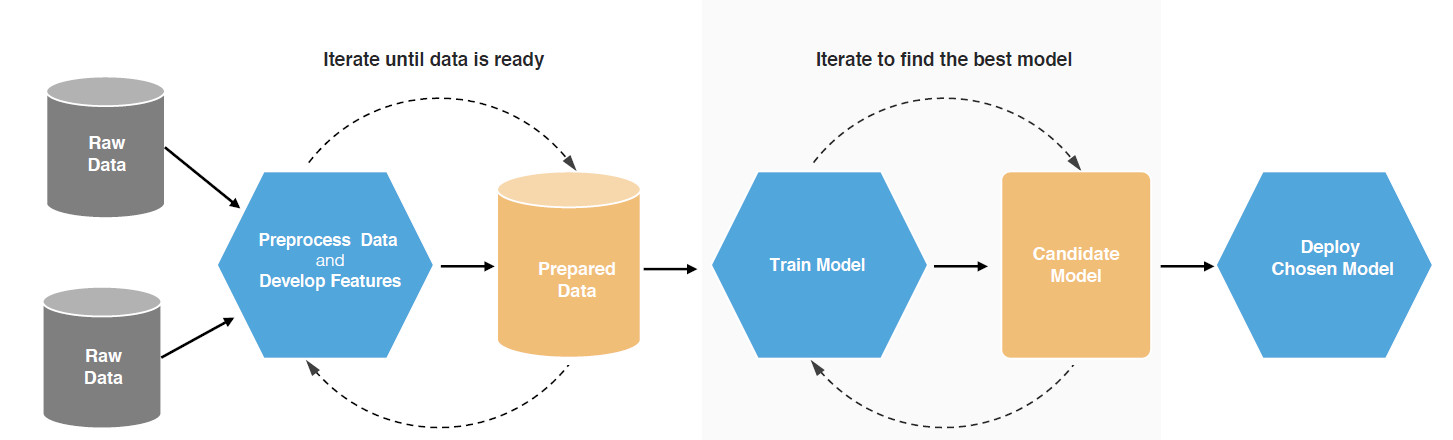
据说ML的实践包括至少80%的数据处理和清理以及20%的算法应用。因此,任何ML方法的预测能力取决于高质量的大量数据的可用性。用于训练的数据需要准确、精确并尽可能完整,以便最大限度地提高可预测性。实验设计通常涉及关于理想样本大小的讨论以及用于正确估计该参数的适当功率计算。是否可以获得正确类型的数据以及应该通过实验生成哪些数据也是某些问题的关键考虑因素。当用于以系统方式生成的数据时,ML应用程序更加强大,具有最小的噪声和良好的注释。许多应用程序并不是特别有效,因为数据是从具有可变数据质量的多个来源组合而来的。目前正在努力开发药物发现的特定领域中的开放注释数据,例如靶标验证。这些目标旨在在药物发现和开发中重要的领域产生高质量的正面和负面注释,以促进ML的应用。
ML在药物发现中主要应用
靶标确诊和有效性
小分子设计和优化
预测生物标志物
计算病理学
参考
Applications of machine learning in drug discovery and development Nature Reviews Drug Discovery ( IF 50.167 ) Pub Date : 2019-04-11 , DOI: 10.1038/s41573-019-0024-5