图的搜索算法
最直接的理解就是在图中的一个顶点出发,到达另一个顶点的路径。图的搜索算法中,广度优先搜索BFS和深度优先搜索DFS就是最简单最粗暴的算法,因为也没什么优化空间,也叫暴力搜索算法。
图的存储有两种方式:一种邻接矩阵,一种邻接表。本文主要使用邻接表来存储图。
BFS和DFS都可以用在有向图或者无向图中。本文主要使用的是无向图。
这两种搜索算法都只能适用于图不大的搜索。
广度优先搜索算法
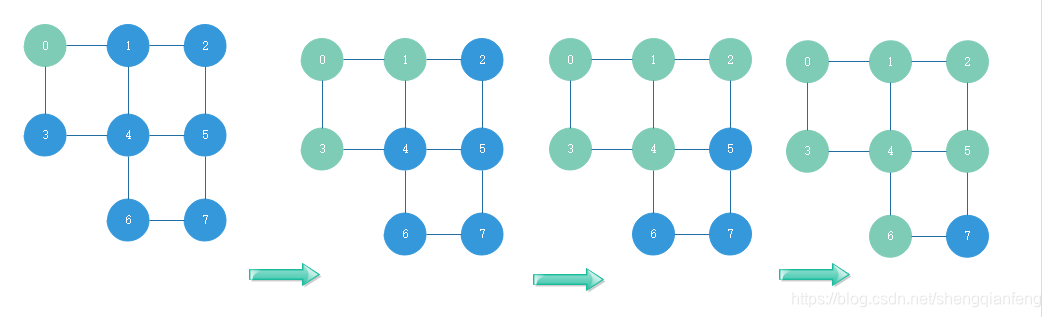
广度优先搜索(Breadth-First-Search),简称BFS,它的搜索策略直观来说就是地毯式层层推进。也就是先查找距离起始顶点最近的,然后是次近的,依次往外扩展搜索。
代码实现
package com.study.algorithm.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @Auther: JeffSheng
* @Date: 2019/9/30 13:52
* @Description: 无向图
*/
public class Graph {
/**
* 顶点的个数
*/
private int v;
/**
* 邻接表
*/
private LinkedList<Integer> adj[];
public Graph(int v){
this.v = v;
adj = new LinkedList[v];
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
/**
* 无向图 一条边存两次
* @param s 起始顶点
* @param t 终止顶点
*/
public void addEdge(int s,int t){
adj[s].add(t);
adj[t].add(s);
}
/**
* 广度优先遍历
* @param s
* @param t
*/
public void bfs(int s, int t) {
if (s == t) {
return;
}
boolean[] visited = new boolean[v];
visited[s]=true;
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
while (queue.size() != 0) {
//返回并删除队首元素
int w = queue.poll();
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
if (q == t) {
print(prev, s, t);
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
private void print(int[] prev, int s, int t) { // 递归打印 s->t 的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
public static void main(String[] args) {
Graph graph = new Graph(8);
graph.addEdge(0,1);
graph.addEdge(0,3);
graph.addEdge(1,2);
graph.addEdge(1,4);
graph.addEdge(3,4);
graph.addEdge(2,5);
graph.addEdge(4,5);
graph.addEdge(4,6);
graph.addEdge(5,7);
graph.addEdge(6,7);
graph.bfs(0,7);
}
}
重点解释visited、prev、queue三个变量的含义:
visited:记录已经被访问过的顶点,避免被重复访问,只要顶点q被访问,则visited[q]=true。
queue:queue是一个队列用来存储那些自身已经被访问过,但其连接的顶点还没被访问的顶点。广度优先搜索是逐层访问,也就是说当第K层的所有顶点都被访问过之后,才能访问第K+1层的顶点,
prev:prev数组用来记录搜索路径,当我们从起始顶点s开始,广度优先搜索到顶点t后,prev数组中存储的就是搜索的路径,比如prev[q]=w表示的就是q这个顶点是从w访问过来的。
BFS时间、空间复杂度分析
极端情况下第一个顶点是起始顶点s,最后一个顶点是终止顶点t,那么需要遍历整张图才能找到路径,这个时候每个顶点都要进出一遍队列,每个边也会被访问一次,所以BFS的时间复杂度为O(V+E),V就是顶点个数,E就是边的个数。对于连通图(图中的所有顶点都是连通的)E肯定比V个数要大的多,所以BFS的时间复杂度可以为O(E).
BFS的空间复杂度主要就是由visited数组、prev数组、queue队列三个来决定的,不过他们三个的存储空间大小不会超过顶点个数V,因此空间复杂度为O(V).
深度优先搜索
深度优先搜索(Depth-First-Search),简称DFS。
实际上深度优先搜索使用的思想是回溯思想,回溯思想适合用递归去实现。
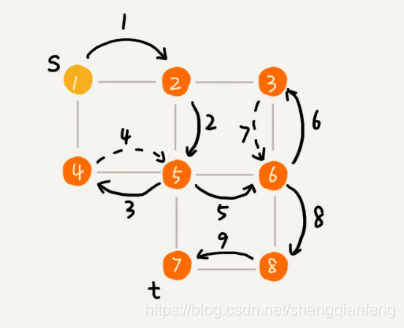
深度优先搜索找到的路径并不是起始顶点s到终止顶点t的最短路径。
代码实现
package com.study.algorithm.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @Auther: JeffSheng
* @Date: 2019/9/30 13:52
* @Description: 无向图
*/
public class Graph {
/**
* 顶点的个数
*/
private int v;
/**
* 邻接表
*/
private LinkedList<Integer> adj[];
public Graph(int v){
this.v = v;
adj = new LinkedList[v];
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
/**
* 无向图 一条边存两次
* @param s 起始顶点
* @param t 终止顶点
*/
public void addEdge(int s,int t){
adj[s].add(t);
adj[t].add(s);
}
private void print(int[] prev, int s, int t) { // 递归打印 s->t 的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
/**
* 全局变量或者类成员变量
*/
boolean found = false;
/**
* 深度优先遍历
* @param s 起始顶点
* @param t 终止顶点
*/
public void dfs(int s, int t) {
found = false;
boolean[] visited = new boolean[v];
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
recurDfs(s, t, visited, prev);
print(prev, s, t);
}
/**
*
* @param w
* @param t
* @param visited
* @param prev
*/
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found == true){
return;
}
visited[w] = true;
if (w == t) {
found = true;
return;
}
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
public static void main(String[] args) {
Graph graph = new Graph(8);
graph.addEdge(0,1);
graph.addEdge(0,3);
graph.addEdge(1,2);
graph.addEdge(1,4);
graph.addEdge(3,4);
graph.addEdge(2,5);
graph.addEdge(4,5);
graph.addEdge(4,6);
graph.addEdge(5,7);
graph.addEdge(6,7);
graph.bfs(0,7);
}
}
DFS时间、空间复杂度分析
DFS每条边最多会被访问两次,一次是遍历,一次是回退。所以DFS时间复杂度O(E),
DFS的空间复杂度主要消耗的内存是visited数组、prev数组、递归调用栈,他们都不会超过顶点个数V,所以DFS的空间复杂度为O(V)