1. 图的遍历定义
图的遍历定义:
从给定图中任意指定的顶点(称为初始点)出发,按照某种搜索方法沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次,这个过程称为图的遍历。
图遍历得到的顶点序列称为图遍历序列。
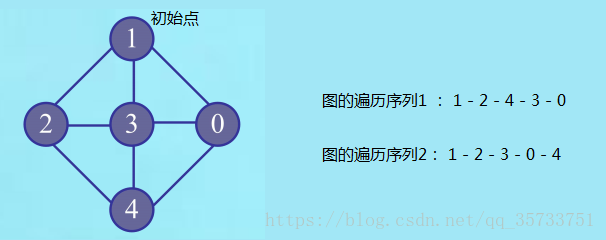
图1-图的遍历
图中顶点之间是多对多的关系,而从一个顶点出发一次只能访问另外一个相邻顶点。比如:顶点1是初始点,从顶点1出发,访问顶点1,接着我们可以再这样访问:
1.再访问顶点2,4,3,0
2.再访问顶点2,3,0,4
实际上上面这种不同的访问次序得到的不同的图的遍历序列,就构成了不同的访问方法,那么根据搜索访问的不同,图的遍历方法有两种:
深度优先遍历(DFS),Deep-First-Search
广度优先遍历(BFS),Breadth-First-Search
2. 遍历策略
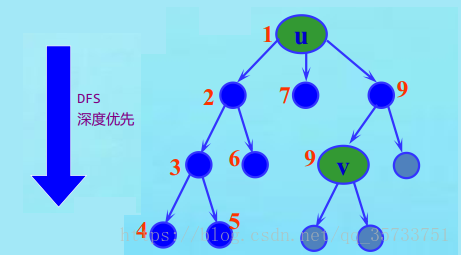
图2-树的深度优先(DFS)遍历
我们从树的遍历过程中来看深度优先遍历,比如:上图中的树采用先序遍历的方式进行搜索左子树的次序为:1,2,3,4,5,6。从上到下,直到把左子树访问完毕,我们可以看到这样的搜索过程其实就是一个深度优先搜索的过程。
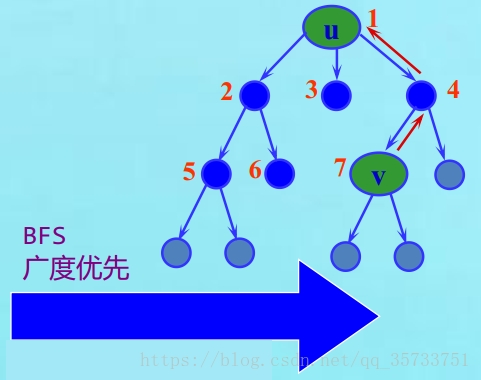
图3-树的广度优先(BFS)遍历
而对于广度优先搜索,其实就是树的一个层次遍历的过程,比如:当我们访问完1的时候,接着就开始访问下一层:2,3,4。然后再接着访问下一层5,6,7,…… 每一次的访问都把所有的孩子节点都访问一遍。
3. 深度优先(DFS)遍历图
深度优先遍历过程:
1. 从图中某个初始顶点v出发,首先访问初始顶点v。
2. 选择一个与顶点v相邻且没被访问过的顶点w,再从w出发进行深度优先搜索,直到图中与当前顶点v邻接的所有顶点都被访问过为止。
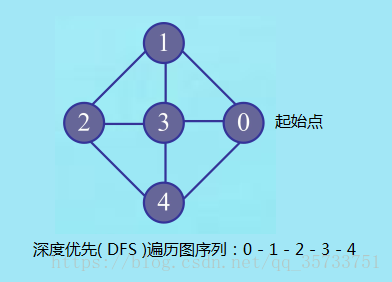
图4-深度优先(DFS)遍历图
图4中的深度优先遍历过程得到的图遍历序列为:0 - 1 - 2 - 3 - 4,现在我们来看一下这个序列的遍历过程是怎样的:
首先从图中选择从顶点0(初始顶点)出发,访问顶点0,然后选择一个与顶点0相邻且没被访问过的顶点0(如果有多个相邻的顶点,则选择其中一个且该顶点没有被访问过),再从顶点1进行深度优先搜索,选择一个与顶点1相邻且没被访问过的顶点2再进行深度优先搜索 …… 直到访问完毕,得到图遍历序列为:0 - 1 - 2 - 3 - 4。
4. 深度优先(DFS)算法设计思路
深度优先遍历的过程体现出后进先出的特点:用栈或递归方式实现。

图5-深度优先(DFS)算法设计思路
图是一种比较复杂的数据结构,因为它的任一顶点都可能有多个相邻的邻接点,极有可能存在沿着某条路径搜索后,再回到原点,而有些顶点却还没有遍历到的情况。因此我们需要在遍历过程中记录访问过的顶点,以避免访问多次。那么如何确定一个顶点是否已经访问过呢?

图6-visited数组
设置一个visited[ ]全局数组,数组中的下标i和顶点i是相对应的,当visited[i] = 0表示顶点i没有访问过, 当visited[i] = 1表示顶点i已经访问过了。
如图6所示:当visited[0] = 1就表示顶点0已经被访问过了,当visited[1] = 0就表示顶点1没有被访问过。
5. 采用邻接表的DFS算法
//定义数组,算法执行前全置0
int visited[N] = {0};
//G表示给定的图,采用邻接表存储
//v表示起始点
void DFS(ALGraph *G , int v)
{
ArcNode *p = NULL;
int w;
if(G == NULL)
{
return;
}
//置为已访问标记
visited[v] = 1;
//输出被访问顶点的编号
printf("%d\t" , v);
//p指向顶点v的第一条边的头节点
p = G->adjlist[v].firstarc;
while(p != NULL)
{
//如果顶点w没有被访问过,则递归访问
w = p->adjvex;
if(visited[w] == 0)
{
DFS(G,w);
}
//如果已经访问过,p则指向下一条边的头节点
p = p->nextarc;
}
}
DFS算法调用过程:
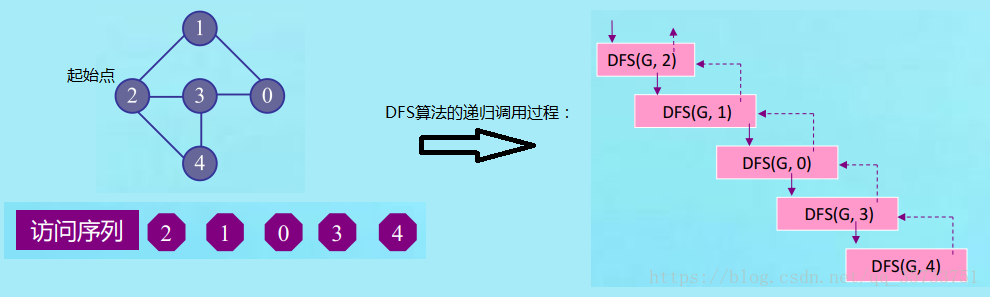
图7-DFS算法调用过程
DFS算法的整个递归调用过程如上图所示,其中实线表示递归调用过程,而虚线则表示递归回退的过程。
6. 广度优先(BFD)遍历图
广度优先(BFD)遍历过程:
1. 访问初始点v
2. 接着访问v的所有未被访问过的邻接点v1,v2 …… vt ;按照v1,v2 …… vt 的次序,访问每一个顶点的所有未被访问过的邻接点。
3. 以此类推,直到图中所有和初始点v有路径相通的顶点都被访问过为止。
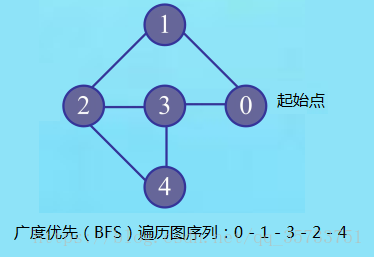
图8-广度优先(BFS)遍历
通过上图中的广度优先(BFS)遍历图序列可知:
首先从图中选择从顶点0(初始顶点)出发,访问顶点0,接下来访问所有和顶点0相邻且没有被访问过的顶点1,顶点3;然后再按照1,3这样的次序,访问每一个顶点的所有未被访问过的邻接点。于是根据顶点1再去访问顶点2,根据顶点3再去访问顶点4 。最后完成整个广度优先(BFS)遍历的过程,得到的图序列为:0 - 1 - 3 - 2 - 4。
广度优先(BFS)遍历的特点就是当访问一个顶点时,接着再依次访问所有和这个顶点相邻且没有访问过的顶点,然后再按照1,3这样的次序,访问每一个顶点的所有未被访问过的邻接点。根据这样的特点我们可以知道广度优先(BFS)具有队列里先进先出的特点,那么我们在实现的时候就可以采用队列实现BFS算法。另外,我们在实现BFS算法的时候同样也需要定义一个visited数组来标记已访问的节点。
7. BFS算法实现
//G表示给定的图,采用邻接表存储
//v表示起始点
void BFS(ALGraph *G,int v)
{
ArcNode *p;
int w,i;
int queue[MAXV],front=0,rear=0;
//定义存放节点的访问标志的visited数组,并全部初始化为0
int visited[MAXV];
for (i=0; i<G->n; i++)
visited[i]=0;
//访问第一个顶点并入队,注意这里是采用的环形队列
printf("%2d",v);
//标记为已访问
visited[v]=1;
rear=(rear+1)%MAXV;
queue[rear]=v;
//队列是否为空,否则取出队中未被访问的顶点
while (front!=rear)
{
//取出队中顶点
front=(front+1)%MAXV;
w=queue[front];
//获取邻接点(访问该顶点的所有未访问的邻接点并使之入队)
p=G->adjlist[w].firstarc;
while (p!=NULL)
{
//这个邻接点是否已经访问
if (visited[p->adjvex]==0)
{
//访问这个邻接点,并将该邻接点标记为已访问
printf( "%2d",p->adjvex);
visited[p->adjvex]=1;
//然后将邻接点入队
rear=(rear+1)%MAXV;
queue[rear]=p->adjvex;
}
//获取下一个邻接点
p=p->nextarc;
}
}
printf("\n");
}