版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
**
SparkSQL读取MySQL数据
**
一、sparkSQL读取MySQL数据
1、第一种方式
def main(args: Array[String]): Unit = {
//获取sparkSession
val sparkSession = SparkSession.builder().appName(this.getClass.getSimpleName.filter(!_.equals('$'))).getOrCreate()
//获取sparkContext
val sparkContext = sparkSession.sparkContext
//设置日志级别
sparkContext.setLogLevel("WARN")
//读取数据
val properties = new Properties()
properties.put("user","qjjc")
properties.put("password","XXX")
val url = "jdbc:mysql://10.213.111.XXX:23306/buf_amr_all"
val data: DataFrame = sparkSession.read.jdbc(url,"pdwqy_pms_yx_sbxx",properties)
data.show()
//释放资源
sparkContext.stop()
sparkSession.stop()
}
该方法还可以并发读取数据
- 指定数据库字段的范围分区:
调用函数:
def jdbc(
url: String,
table: String,
columnName: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
connectionProperties: Properties): DataFrame
代码示例:
val lowerBound = 1
val upperBound = 100000
val numPartitions = 5
val properties = new Properties()
properties.put("user","qjjc")
properties.put("password","XXX")
val url = "jdbc:mysql://10.213.111.XXX:23306/buf_amr_all"
val df = sqlContext.read.jdbc(url, "pdwqy_pms_yx_sbxx", "id", lowerBound, upperBound, numPartitions, prop)
- 根据任意字段进行分区
调用函数:
def jdbc(
url: String,
table: String,
predicates: Array[String],
connectionProperties: Properties): DataFrame
代码示例:
val predicates = Array[String]("reportDate <= '2014-12-31'",
"reportDate > '2014-12-31' and reportDate <= '2015-12-31'")
val properties = new Properties()
properties.put("user","qjjc")
properties.put("password","XXX")
val url = "jdbc:mysql://10.213.111.XXX:23306/buf_amr_all"
val df = sqlContext.read.jdbc(url, "pdwqy_pms_yx_sbxx", predicates, prop)
注意Array中的写法格式应为SQL表达式格式,例如:
xx < xx 或者 xx=xx 或者 xx is null
2、第二种方式
def main(args: Array[String]): Unit = {
//创建sparkSession(打包在集群上运行要删除master)
val sparkConf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.filter(!_.equals('$')))
//获取sparkContext
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("WARN")
//获取sqlContext
val spark: SQLContext = new SQLContext(sparkContext)
//读取数据
val data: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://10.213.111.XXX:23306/buf_amr_all")
.option("dbtable", "pdwqy_pms_yx_sbxx")
.option("user", "qjjc")
.option("password", "XXX")
.load()
data.show()
//释放资源
sparkContext.stop()
sparkSession.stop()
}
二、sparkSQL将数据写入到MySQL
1、第一种方式
//计算得到DataFrame类型结果
val result: DataFrame = spark.sql("select * from table1")
//将数据保存到MySQL
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","root")
result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/gwdsj","pdwqy_pms_yx_sbxx",properties)
2、第二种方式
//计算得到DataFrame类型结果
val result: DataFrame = spark.sql("select * from table1")
//将数据保存到MySQL
YJYP_result.write.mode(SaveMode.Append).format("jdbc")
.option(JDBCOptions.JDBC_URL,"jdbc:mysql://21.76.120.XXX:3306/us_app?rewriteBatchedStatement=true")
.option("user","root")
.option("password","XXX")
.option(JDBCOptions.JDBC_TABLE_NAME,"tb_pdwqy_ywfz_yjyp")
.option(JDBCOptions.JDBC_TXN_ISOLATION_LEVEL,"NONE") //不开启事务
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE,500) //设置批量插入
.save()
**
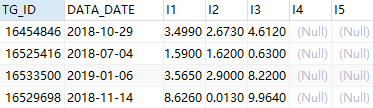
此外,执行写入操作时,结果数据的字段缺失和字段顺序都不用在意,例如:
val result = spark.sql("select TG_ID,`1` I1,`2` I2,`3` I3,DATA_DATE from result_temp")
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123")
result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/test11","dlzz111",properties)
数据可以顺利插入:
SparkSQL读取Oracle数据
**
整体与MySQL类似,只需要修改URL驱动就可以:
jdbc:oracle:thin:@//10.212.242.XXX:11521/pmsgs
另外,如果是maven项目,需要注意:
由于Oracle授权问题,Maven3不提供oracle JDBC driver,我们也可以在Maven的中心搜索ojdbc驱动包,但是可以看到版本过于陈旧,即使有坐标,也下载不了。
为了可以在使用Maven构建的项目中使用Oracle JDBC driver,我们就必须手动添加Oracle的JDBC驱动依赖到本地仓库中。
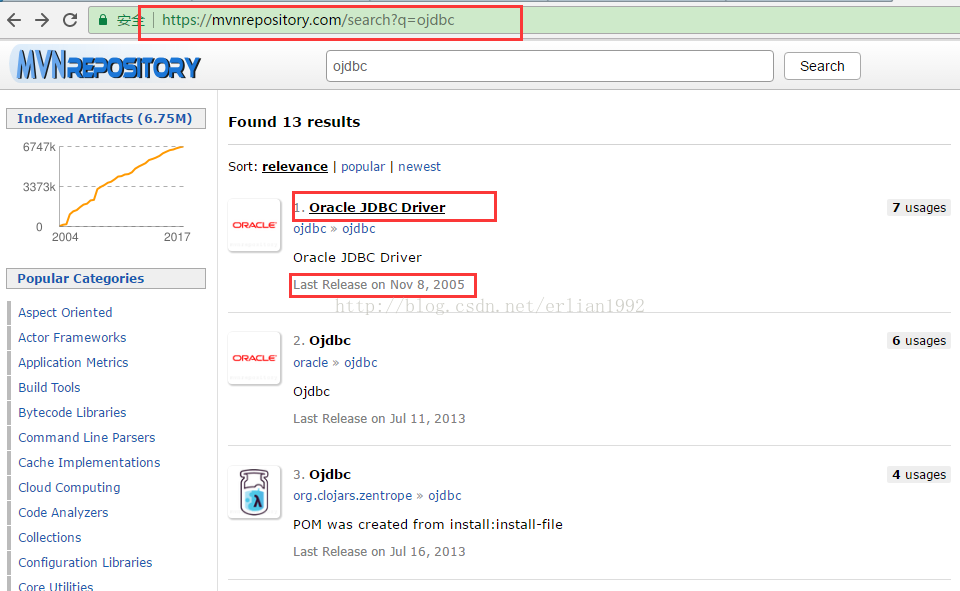
网上下载合适的Oracle依赖包(本人使用的是classes12)
将jar包手动添加到maven项目中,参考:
maven项目手动导入jar包依赖