今天是1024属于我们程序员的日子,一定要写上一篇博客对不对,于是乎抽点时间来把关于SQL基础的最后一点内容分享一下,当然并不是说以后不分享这块内容了,我的思路就是由简到难,由繁到简。到了后面可能一个问题就发一篇博客,当然发博客也不是抱着什么年头,只是让自己在巩固基础,在工作的时候可以更加努力,人生转瞬即逝,留下博客也可以以后再回味回味,话说的有点多了哈,开始今天正题吧。
继续之前的风格开始吧。
上一篇:MySQL学习笔记_中(数据操作语言(DML_insert&update&delete)、数据定义语言(DDL_create&drop&alter))
第7章:数据库事务
7.1 什么是事务
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
数据库事务由以下的部分组成:
- 一个或多个DML 语句
- 一个 DDL(Data Definition Language – 数据定义语言) 语句
- 一个 DCL(Data Control Language – 数据控制语言) 语句
7.2 如何处理事务
事务处理(事务操作):保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback)到最初状态。
为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
当一个连接对象被创建时,默认情况下是自动提交事务:每次执行一个SQL 语句时,如果执行成功,就会向数据库自动提交,而不能回滚。
具体过程:
- 设置提交状态:SET AUTOCOMMIT = FALSE;
- 以第一个 DML 语句的执行作为开始
- 以下面的其中之一作为结束:
- COMMIT或ROLLBACK语句。
- DDL 语句(自动提交)。
- 用户会话正常结束。
- 系统异常终止。
COMMIT和ROLLBACK语句的优点:
- 确保数据完整性。
- 数据改变被提交之前预览。
- 将逻辑上相关的操作分组。
数据完整性:
存储在数据库中的所有数据值均处于正确的状态。如果数据库中存储有不正确的数据值,则该数据库称为已丧失数据完整性。
数据库采用多种方法来保证数据完整性,包括外键、束约、规则和触发器。
提交或回滚前的数据状态:
- 改变前的数据状态是可以恢复的
- 执行 DML 操作的用户可以通过 SELECT 语句查询提交或回滚之前的修正
- 其他用户不能看到当前用户所做的改变,直到当前用户结束事务。
- DML语句所涉及到的行被锁定, 其他用户不能操作。
提交后的数据状态:
- 数据的改变已经被保存到数据库中。
- 改变前的数据已经丢失。
- 所有用户可以看到结果。
- 锁被释放, 其他用户可以操作涉及到的数据。
数据回滚后的状态:
使用 ROLLBACK 语句可使数据变化失效:
-
数据改变被取消。
-
修改前的数据状态可以被恢复。
7.3 事务的ACID属性
-
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 -
一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。 -
隔离性(Isolation)
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。 -
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
7.4 数据库的隔离级别
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
-
脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段。 之后, 若 T2 回滚, T1读取的内容就是临时且无效的。
-
不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段。 之后, T1再次读取同一个字段, 值就不同了。
-
幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行。 之后, 如果 T1 再次读取同一个表, 就会多出几行。
-
数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题。
-
一个事务与其他事务隔离的程度称为隔离级别。数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱。
数据库提供的 4 种事务隔离级别:

-
Oracle 支持的 2 种事务隔离级别:READ COMMITED, SERIALIZABLE。 Oracle 默认的事务隔离级别为: READ COMMITED 。
-
Mysql 支持 4 种事务隔离级别。 Mysql 默认的事务隔离级别为: REPEATABLE READ
在MySql中设置隔离级别
- 每启动一个 mysql 程序, 就会获得一个单独的数据库连接。每个数据库连接都有一个全局变量 @@tx_isolation, 表示当前的事务隔离级别.
- 查看当前的隔离级别: SELECT @@tx_isolation;
- 查看全局的隔离级别: SELECT @@global.tx_isolation;
- 设置当前 mySQL 连接的隔离级别:
set tx_isolation ='repeatable-read';
- 设置数据库系统的全局的隔离级别:
set global tx_isolation ='read-committed';
注意:这里的隔离级别中间是减号,不是下划线。
第8章:其它数据库对象
8.1 常见的数据库对象
| 对象 | 描述 |
|---|---|
| 表(TABLE) | 基本的数据存储集合,由行和列组成 |
| 视图(VIEW) | 从表中抽出的逻辑上相关的数据集合 |
| 序列(SEQUENCE) | 提供有规律的数值。 |
| 索引(INDEX) | 提高查询的效率 |
| 同义词(SYNONYM) | 给对象起别名 |
8.2 视图(VIEW)
视图简述:
-
视图是一种虚表
-
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
-
向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句 。
-
视图向用户提供基表数据的另一种表现形式。
-
为什么使用视图?
- 控制数据访问
- 简化查询
- 避免重复访问相同的数据
简单视图和复杂视图对比:
| 特性 | 简单视图 | 复杂视图 |
|---|---|---|
| 表的数量 | 一个 | 一个或多个 |
| 函数 | 没有 | 有 |
| 分组 | 没有 | 有 |
| DML操作 | 可以 | 有时可以 |
创建视图
- 在 CREATE VIEW 语句中嵌入子查询
CREATE VIEW empvu80
AS
SELECT employee_id, last_name, salary
FROM employees
WHERE department_id = 80;
- 子查询可以是复杂的 SELECT 语句
create or replace view empview
as
select employee_id emp_id,last_name name,department_name
from employees e,departments d
Where e.department_id = d.department_id;
- 创建视图时在子查询中给列定义别名
CREATE VIEW salvu50
AS
SELECT employee_id ID_NUMBER, last_name NAME,salary*12 ANN_SALARY
FROM employees
WHERE department_id = 50;
- 描述视图结构
DESCRIBE empvu80;

说明:在选择视图中的列时应使用别名
- 查询视图
SELECT *
FROM empvu80;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f7DGsMhq-1571548409263)(SQL开发.assets/1555430882363.png)]](https://img-blog.csdnimg.cn/20191023202451341.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p4ZHNwYW9wYW8=,size_16,color_FFFFFF,t_70)
- 修改视图
- 使用CREATE OR REPLACE VIEW 子句修改视图
CREATE OR REPLACE VIEW empvu80
(id_number, name, sal, department_id)
AS
SELECT employee_id, first_name || ' ' || last_name, salary, department_id
FROM employees
WHERE department_id = 80;
说明:CREATE VIEW 子句中各列的别名应和子查询中各列相对应。
- 创建复杂视图
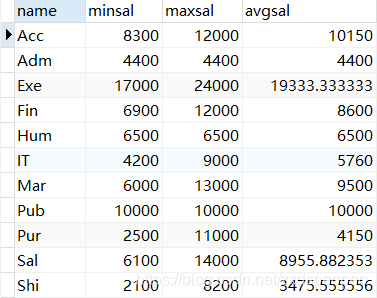
CREATE VIEW dept_sum_vu
(name, minsal, maxsal, avgsal)
AS
SELECT d.department_name, MIN(e.salary), MAX(e.salary),AVG(e.salary)
FROM employees e, departments d
WHERE e.department_id = d.department_id
GROUP BY d.department_name;
查询:
视图中使用DML的规定:
-
可以在简单视图中使用DML操作
-
当视图定义中包含以下元素之一时不能使用delete:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
-
当视图定义中包含以下元素之一时不能使用update:
- 组函数
- GROUP BY子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义为表达式
-
当视图定义中包含以下元素之一时不能使用insert:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义为表达式
- 表中非空的列在视图定义中未包括
删除视图:
删除视图只是删除视图的定义,并不会删除基表的数据。
DROP VIEW empvu80;
删除后视图被删除,但是原来的数据没有被删除。
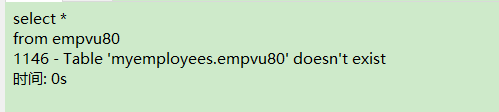

8.3 索引(INDEX)
8.3.1 基本介绍
- 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中,是一个单独的、物理的数据库结构。
- 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度。
- 索引一旦建立, 数据库管理系统会对其进行自动维护, 而且由数据库管理系统决定何时使用索引。用户不用在查询语句中指定使用哪个索引。
- 在删除一个表时,所有基于该表的索引会自动被删除。
- 通过指针加速数据库服务器的查询速度。
- 通过快速定位数据的方法,减少磁盘 I/O。
8.3.2 索引的介绍
例如:一本字典,如何快速找到某个字,可以给字典加目录,对数据库来说,索引的作用即是给"数据"加目录。
设有N条随机记录,不用索引,平均查找N/2次,那么用了索引之后呢。如果是btree(二叉树)索引, 则是logN。 如果是hash(哈希)索引,时间复杂度是1。
MySQL提供多种索引类型供选择:
- 普通索引
- 唯一性索引
- 主键索引:只有一个主键索引
- 全文索引:MySQL5.X版本只有MyISAM存储引擎支持FULLTEXT,并且只限于CHAR、VARCHAR和TEXT类型的列上创建。
MySQL的索引方法:
- HASH
- BTREE(MySQL中多数索引都以BTREE的形式保存。)
8.3.3 创建索引
-
自动创建: 在定义 PRIMARY KEY 或 UNIQUE 约束后系统自动在相应的列上创建唯一性索引
-
手动创建: 用户可以在其它列上创建非唯一的索引,以加速查询
-
在一个或多个列上创建索引语法:
CREATE INDEX index
ON table (column,[,column]...)
- 在表 EMPLOYEES的列 LAST_NAME 上创建索引
CREATE INDEX emp_last_name_idx
ON employees(last_name);
索引的优缺点:
- 索引的优点:加快了查询速度(select )
- 索引的缺点:降低了增,删,改的速度(update/delete/insert),增大了表的文件大小(索引文件甚至可能比数据文件还大)
什么时候创建索引:
以下情况可以创建索引:
-
列中数据值分布范围很广
-
列经常在 WHERE 子句或连接条件中出现
-
表经常被访问而且数据量很大 ,访问的数据大概占数据总量的2%到4%
什么时候不要创建索引:
- 表很小
- 列不经常作为连接条件或出现在WHERE子句中
- 查询的数据大于2%到4%
- 表经常更新
- 索引散列值,过于集中的值不要索引,例如:给性别"男","女"加索引,意义不大
索引不需要用,只是说我们在用name进行查询的时候,速度会更快。当然查的速度快了,插入的速度就会慢。因为插入数据的同时,还需要维护一个索引。
8.3.4 删除索引
使用DROP INDEX 命令删除索引语法:
DROP INDEX 索引名
ON 表名;
例如:
DROP INDEX upper_last_name_idx
ON uppers;
注意:
- 只有索引的拥有者或拥有DROP ANY INDEX 权限的用户才可以删除索引。
- 删除操作是不可回滚的。
欢迎大家一起交流学习~
上一篇:MySQL学习笔记_中(数据操作语言(DML_insert&update&delete)、数据定义语言(DDL_create&drop&alter))