事务:
事务有一个最显著的特征,就是它包含的所有 SQL 语句作为一个整体向数据库提交,只有所有的 SQL 语句都执行完成,整个事务才算成功,一旦某个 SQL 语句执行失败,整个事务就失败了。事务失败后需要回滚所有的 SQL 语句。
事务是指单个逻辑工作单元执行得一系列操作,要么都做,要么都不做,是不可分割的工作单位,是数据库环境中的的最小工作单元。
事务包含了一组操作,这些操作可以是一条SQL语句、一组SQL语句或整个程序。如果其中一个操作不成功,这些操作都不会执行,前面执行的操作也会回滚原状态,用来保证数据的一致性和完整性。例如,就像银行转账,张三给李四转账,只有当张三的钱转走了,并且李四账户的钱收到了之后才会事务提交,否则事务会回滚到转账前的状态,保证数据的一致性,保证数据不会出错。
应用场景:
事务有很多实用的场景。例如对于电商网站,通常将用户订单存储在一张表中,将商品库存情况存储在另一张表中,当有用户下单时,需要执行两条 SQL 语句,一条负责更新订单表,一条负责更新库存表,这两条 SQL 语句必须同时执行成功。如果只有一条语句执行成功,另一条语句执行失败,将导致数据库出错,这种后果是无法接受的。为了避免出现意外,可以将以上两条语句放到一个事务中,其中一条语句执行失败时,数据库将回滚到原来的状态。对于买家来说,数据库回滚会导致下单失败,但这很容易处理,让买家再次下单即可。数据库的正确性永远是最重要的。
A:初始1000 ; B:初始200

原子性是事务的基础,持久性和隔离性是手段,一致性是目的
原子性 :要么 2个都完成(A->B转账成功;B收款成功)
一致性 (A+B=1200)

持久性 :事务一旦提交就不可逆

隔离性





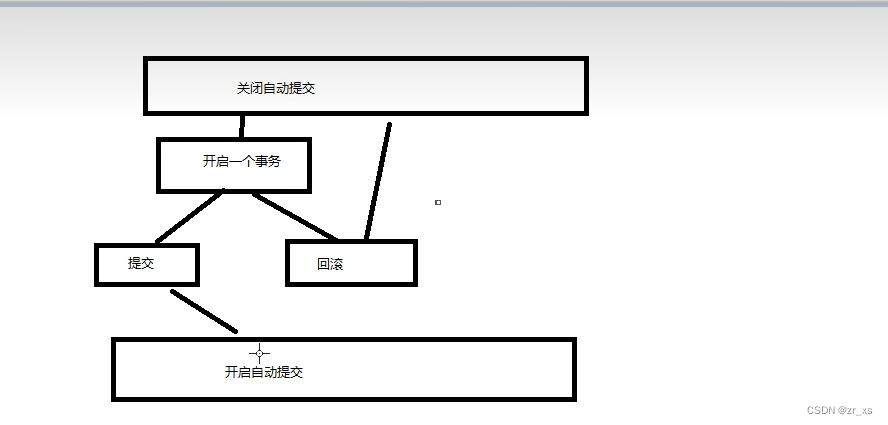
mysql是默认开启,oracle是默认不开启的
mysql是默认开启:其实我们平时使用数据库时,就已经在使用事务了,只不过这种事务只包含一条 SQL 语句,并且由数据库引擎自动封装和提交。这意味着,对于任何一条 SQL 语句,要么执行成功,要么执行失败,不能成功一部分,失败一部分。

2条insert 语句在同一 事务内,只要有一个失败,2个都不会被提交
\

索引:
作用更高效的获取数据。


索引的使用
给字段添加索引

使用索引,在执行sql时,会快一点
创建索引方法:
1.在创建表的时候 给字段添加索引
2.创建完毕后,给字段增加索引

插入100万条数据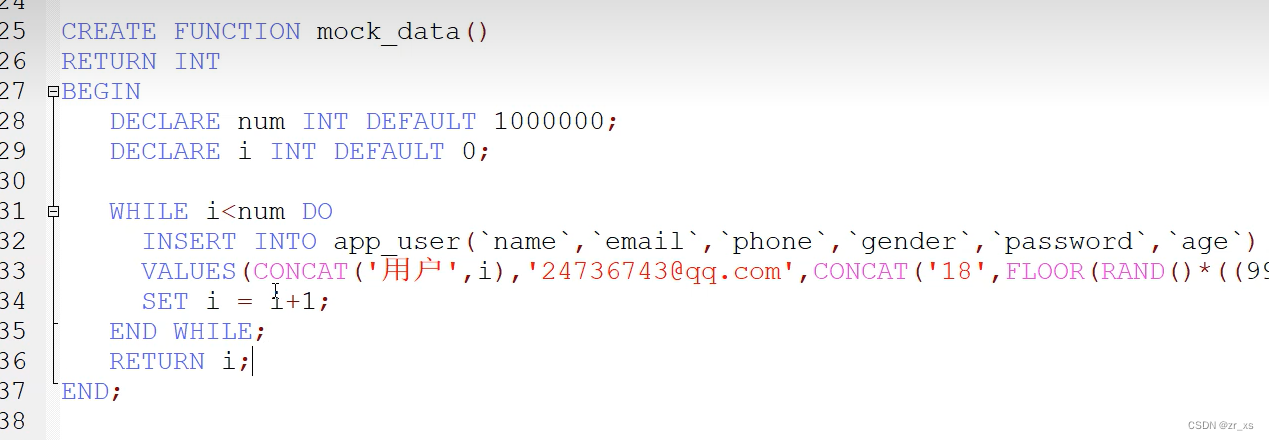
查看SQL语句对索引的使用情况(即:查询SQL的查询执行计划QEP):
在select语句前加上EXPLAIN即可。分析该SQL的性能,查询执行时间
创建索引前:查一条数据,耗时0.78秒
 创建索引后: 查一条数据耗时 0.001秒
创建索引后: 查一条数据耗时 0.001秒

索引能提高查询效率,但是会降低增删改的效率,但是利大于弊
索引在小数据量时,用处不大;但是在大数据的时候,区别明显
MySQL索引的优化 (194条消息) Mysql索引详解及基本用法_mysql索引的使用_牧马人Eikko的博客-CSDN博客
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。下面是一些总结以及收藏的MySQL索引的注意事项和优化方法。
key和index区别:
mysql的key和index多少有点令人迷惑,这实际上考察对数据库体系结构的了解的。
1.key 是数据库的物理结构,它包含两层意义,一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。包括primary key, unique key, foreign key 等。
primary key 有两个作用,一是约束作用(constraint),用来规范一个存储主键和唯一性,但同时也在此key上建立了一个index;
unique key 也有两个作用,一是约束作用(constraint),规范数据的唯一性,但同时也在这个key上建立了一个index;
foreign key也有两个作用,一是约束作用(constraint),规范数据的引用完整性,但同时也在这个key上建立了一个index;
可见,mysql的key是同时具有constraint和index的意义,这点和其他数据库表现的可能有区别。(至少在Oracle上建立外键,不会自动建立index),因此创建key也有如下几种方式:
(1)在字段级以key方式建立, 如 create table t (id int not null primary key);
(2)在表级以constraint方式建立,如create table t(id int, CONSTRAINT pk_t_id PRIMARY key (id));
(3)在表级以key方式建立,如create table t(id int, primary key (id));
其它key创建类似,但不管那种方式,既建立了constraint,又建立了index,只不过index使用的就是这个constraint或key。
2. index是数据库的物理结构,它只是辅助查询的,它创建时会在另外的表空间(mysql中的innodb表空间)以一个类似目录的结构存储。索引要分类的话,分为前缀索引、全文本索引等;
因此,索引只是索引,它不会去约束索引的字段的行为(那是key要做的事情)。
如,create table t(id int, index inx_tx_id (id));
3.最后的释疑:
(1).我们说索引分类,分为主键索引、唯一索引、普通索引(这才是纯粹的index)等,也是基于是不是把index看作了key。
比如 create table t(id int, unique index inx_tx_id (id)); –index当作了key使用
(2).最重要的也就是,不管如何描述,理解index是纯粹的index,还是被当作key,当作key时则
索引在查询中如何使用:
SELECT * FROM test_tab WHERE name = 一个外部输入的数据
刚开始,数据不多的时候,执行效果还不错。
随着数据量的增加,这个查询,执行起来,越来越慢了。
然后在 name 上面 建立了索引
CREATE INDEX idx_test4_name ON test_tab (name );
这样, 可以加快前面那个查询的速度。
但是,某天,你执行了下面这个SQL, 发现速度又慢了
SELECT * FROM test_tab WHERE age = 25
为啥呢? 因为 age 字段上面,没有索引
索引只在 name 上面有
换句话说, 也就是 WHERE 里面的条件, 会自动判断,有没有 可用的索引,如果有, 该不该用。
多列索引,就是一个索引,包含了2个字段。
例如:CREATE INDEX idx_test_name_age ON test_tab (name, age);那么SELECT * FROM test_tab WHERE name LIKE ‘张%’
AND age = 25
这样的查询,将能够使用上面的索引。
多列索引,还有一个可用的情况就是, 某些情况下,可能查询,只访问索引就足够了, 不需要再访问表了。
视图(虚表)
1.只提供查询

2. 定义

3.使用

