索引(*****)
索引:提高查询速度(以空间换时间(B-Tree))
常见的索引分类:
聚簇索引:主键索引(primary key)
二级索引:唯一索引(unique)
普通索引(index)
全文索引(fulltext)--解决中子文索引问题。
-
创建主键索引
方法一:
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));方法二:
-- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));方法三:
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);主键索引的特点:
- 一个表中,最多有一个主键索引,当然可以使符合主键
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为null,且不能重复
- 主键索引的列基本上是int
- 创建唯一索引
方法一:
-- 在表定义时,在某列后直接指定unique唯一属性。
create table user4(id int primary key, name varchar(30) unique);
方法二:
-- 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));方法三:

create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);唯一索引的特点:
- 一个表中,可以有多个唯一索引
- 查询效率高(相对于普通索引而言)
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定not null,等价于主键索引
- 创建普通索引
方法一:
create table user7(
id int primary key,
name varchar(20),
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);方法二:
create table user8(id int primary key, name varchar(20), email varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引方法三:
create table user9(id int primary key, name varchar(20), email varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
- 查询索引
第一种方法:show keys from 表名
第二种方法: show index from 表名;
第三种方法(信息比较简略): desc 表名;
- 删除索引
第一种方法-删除主键索引: alter table 表名 drop primary key;
第二种方法-其他索引的删除: alter table 表名 drop index 索引名;(索引名就是show keys from 表名中的 Key_name 字段)
第三种方法方法: drop index 索引名 on 表名
- 创建索引的原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引
- 不会出现在where子句中的字段不该创建索引
- explain工具:查看当前语句是否使用了索引
事务 (InnoDB支持事务,MyISAM不支持事务)
事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部失败,是一个整体。MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的数据是不相同的。
事务的基本操作
- 开始一个事务
start transaction ;- 创建一个保存点
savepoint name(事务保存点名);- 回滚到保存点
rollback to name(要回滚到的保存点名);若没有设置保存点,rollback语句直接回滚到当前事务开始时。
注意:回滚的前提是该事务还没有提交。即提交过的事务不能回滚。
- 提交事务
commit;- 事务的隔离级别
当MySQL表被多个线程或者客户端开启各自事务操作数据库中的数据时,MySQL提供了一种机制,可以让不同的
事务在操作数据时,具有隔离性。从而保证数据的一致性。
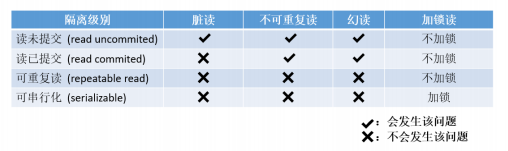
脏读:是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务
也访问这个数据,然后使用了这个数据。
不可重复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一
个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就
发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
幻读:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中
的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发
生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
事务的隔离级别:
- 设置事务的隔离级别:
--将当前事务的隔离级别设置为读未提交
set session transaction isolation level read uncommitted;
- 查看当前的隔离级别:
select @@tx_isolation;说明:mysql默认的隔离级别是可重复读,一般情况下不要修改
- 事务的ACID特性(****)
- 原子性 (Atomicity):事务是应用中最小的执行单位,是应用中不可再分的最小逻辑执行体。
- 一致性 (Consistency):事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态。一致性是通过原子性来保证的。
- 隔离性 (Isolation):各个事务的执行互不干扰,任意一个事务的内部操作对其他并发事务都是隔离的。也就是说,并发执行的事务之间不能看到对方的中间状态,并发执行的事务之间不能互相影响。
- 持久性 (Durability):持久性是指一个事务一旦被提交,它对数据库所做的改变都要记录到永久存储中(如:磁盘)
视图
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。
视图的数据变化会影响到基表,基表的数据变化也会影响到视图。
- 创建视图
create view 视图名 as select语句;- 删除视图
drop view 视图名;- 视图的规则和使用
- 与表一样,必须唯一命名(不能出现同名视图或表名)
- 创建视图数目无限制,但要考虑复杂查询创建为视图之后的性能影响
- 视图不能添加索引,也不能有关联的触发器或者默认值
- 视图可以提高安全性,必须具有足够的访问权限
- order by 可以用在视图中,但是如果从该视图检索数据 select 中也含有 order by ,那么该视图中的order by 将被覆盖
- 视图可以和表一起使用
用户管理
- 查看用户信息
select * from mysql.user; --在mysql库中的user表中查找- 创建用户
create user '用户名'@'登陆主机/ip' identified by '密码;- 删除用户
drop user '用户名'@'主机名';
- 给用户权限
grant 权限列表 on 库.对象名 to '用户名'@'登陆位置' [identified by '密码];- 收回权限
revoke 权限列表 on 库.对象名 from '用户名'@'登陆位置';
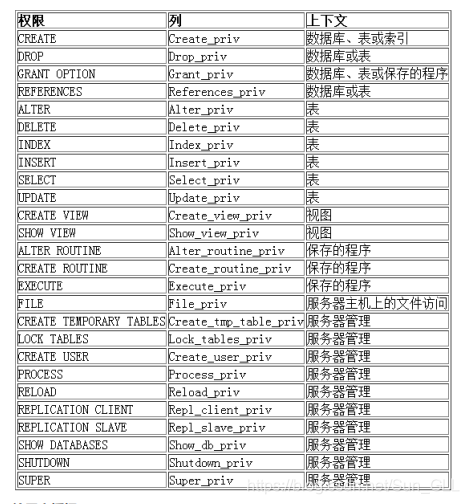
MySQL数据库提供的权限列表: