MySQL高级
这里高级应用的SQL语句,不需要背。当实际需要时,查询本教程或谷歌即可。
一、视图
1)视图是什么
- 数据库表结构改变时,程序也要相应改动,这样的话,耦合度太高了。
- 当我们写完一个程序时,它要在操作系统上使用。那是不是,Windows上要一个版本?然后Linux上要一个版本?理论上是的。但是有这样一个东西,它叫解释器,有Windows解释器也有Linux解释器。只要有这些解释器,在不同操作系统上,程序不用改动,就可以达到相同的功能。解释器去除了底层的区别。
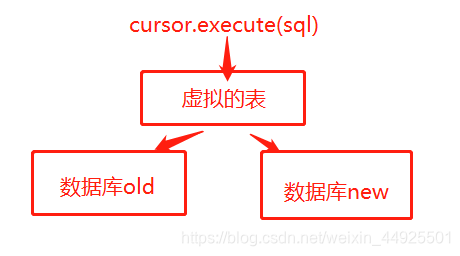
- 我们弄一个虚拟的表,从而无视底层的数据表变化。这个虚拟的表就叫视图。
2)视图的作用
- 视图的作用就是隔离数据库:视图就是一条select语句执行后返回的结果集。是对若干张基本表的引用,是一张虚表,是查询语句执行的结果。
- 视图是为了方便查询的,不是为了增删改的。
- 虚拟表在调用时,才产生(相当于执行SQL语句)。所以它具有跟随基础表同步更新的特性。
3)代码
- 你需要一个select语句查询出来的结果集,比如:
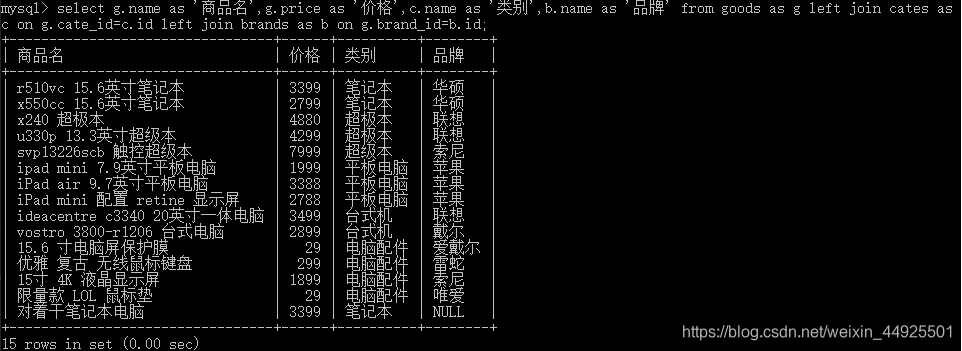
- 创建视图
create view 视图名 as 结果集;
视图名以v_开头美观。
(创建视图代码)

(查看表,发现有个虚拟表)
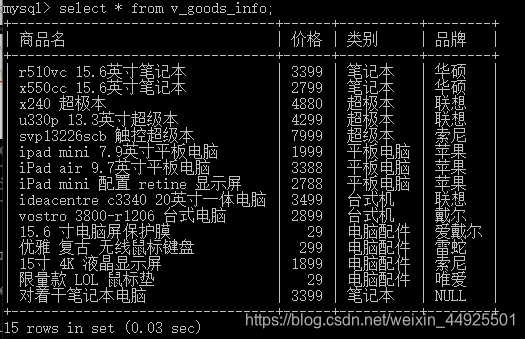
(直接查看虚拟表)
4)删除视图
drop view 视图名;
5)视图的好处
- 提高了重用性,就像一个函数
- 对数据库重构,却不影响程序的运行
- 提高了安全性能,可以对不同的用户
- 让数据更加清晰
二、事务
1)事务是什么
- 比如转账,不可以一个人扣了钱,另一个人没收到。这种要么同时执行,要么同时不执行,形成一个不可分割的工作单位。这,就是事务。
- 事务是保证将来数据百分之百成功的一种方式。
- 使用start transaction;开启一个事务。使用commit;提交一个事务。使用rollback;回滚一个事务。
2)事务的四大特性ACID(背诵理解)
1>四大特性
- 原子性A
- 一致性C
- 隔离性I
- 持久性D
比如买东西时。需要几个步骤:①检查账户余额是否充足 ②从本人账户扣款 ③从商家账户增款
上面三个操作必须打包在一个事务中,任何一个步骤失败,则必须回滚rollback;所有的步骤。
1>四大特性详解
原子性是指: 一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能值执行其中的一部分操作,这就是事务的原子性
#(所有语句都成功,就commit。否则就rollback)
一致性是指: 数据库总是从一个一致性的状态,转向另一个一致性的状态。(比如某条失败,事务中所做的修改也不会保存在数据库中)(要么执行成功,要么不执行成功)
隔离性是指: 一个事务在最终提交之前,对其它事务是隔离的,不可见。(如下面,一个终端发生了事务,另一个终端也想对此行进行修改。哪个先commit,哪个就先修改。当然,后修改的会覆盖。)
持久性是指: 一旦事务提交,其所做的修改会永久保存到数据库。(即使系统崩溃,修改的数据也不会丢失。)
**总结一下:**原子性是要么成功,要么不成功。一致性是不会出现中间数据丢了的情况。隔离性是一个用户的操作,对其他用户不可见。
3>举例说明
- python是默认开启事务的,所以需要commit提交。终端也是默认开启事务的,但它也默认提交。希望终端开启事务而不自动提交,就需要手动开启事务。用start transaction;或者begin;来开启一个事务,这样,只要用户不commit,它就不会提交。(在这个终端即使不提交,也可以预览到。但实际是没发生的。可以在没提交状态下,使用另一个终端查看。)
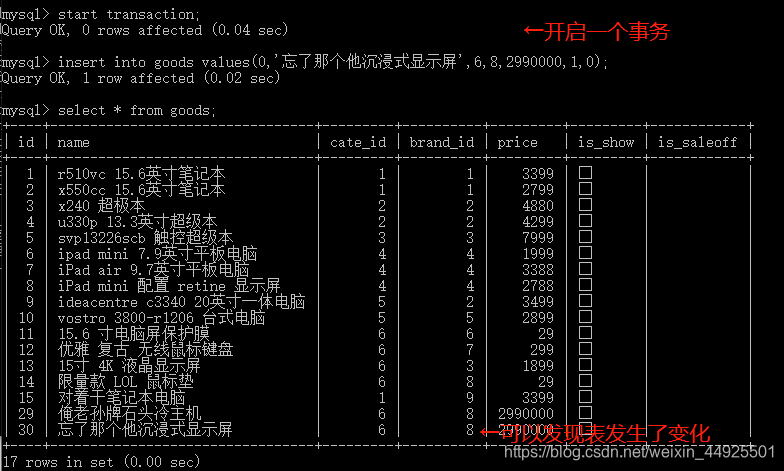
这样看来,开启事务似乎没什么影响啊。我们保持这个终端不动,开启另一个终端。会发现,没有最后那一条数据。原因就是没有提交commit。
接下来,和我做一样的操作:在原终端,不提交事务,而在新终端对原终端修改的这几条记录,进行修改,会发生什么?
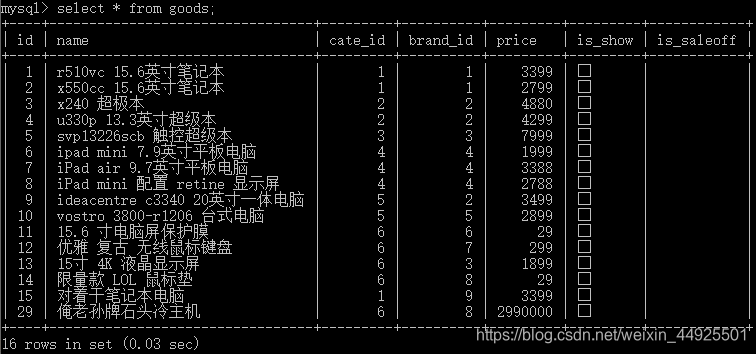
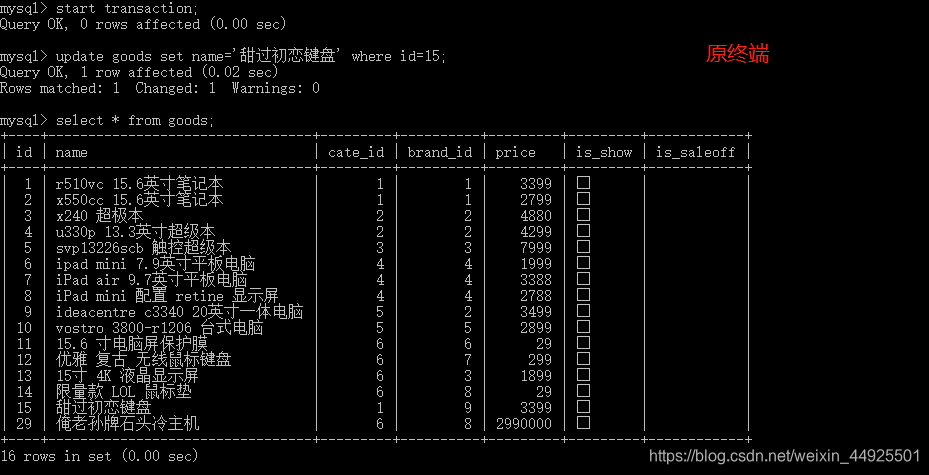
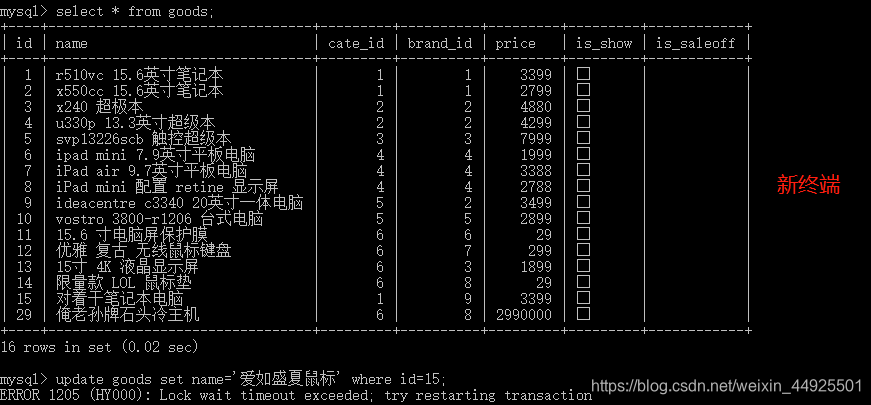
最后一行的意思是,有锁,终端等待太久,请尝试重新启动事务。
只要旧终端一提交或是回滚,新终端紧接着就会开始执行。最后显示的内容,是新终端的内容。
三、索引
- 索引是一种特殊的文件(innoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
- 相当于一个文章的空间,留出一小部分来放置目录。
1)程序执行的时间
- 要知道索引有多快,首先要知道怎样记录时间。
- 拿出你的
秒表终端:
--开启运行时间监测
set profiling=1;
--运行几条SQL语句
--查看执行的时间(会显示ID,时间,以及对应的SQL语句)
show profiles;
单看,并不觉得快或是慢,下面建立索引,对比看看。
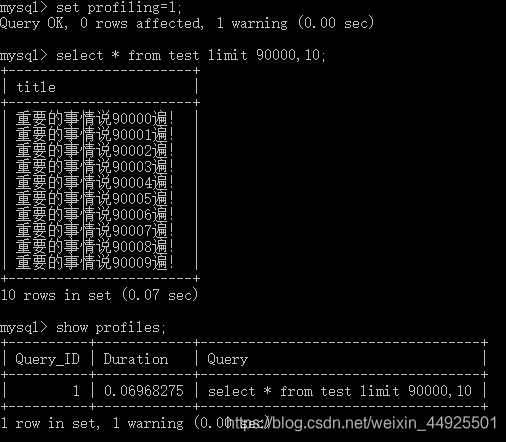
2)建立索引
create index 表名 on 表名(字段名);
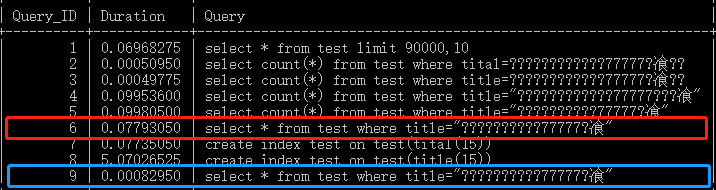
例如: create index test on test(tital(15));
--解释一下,这里title是字符串类型的,且长度为15.整数类型就不用写括号。
依次执行下列语句:
- select * from test where title=“重要的事情说77777遍!”;
- create index test on test(title(15));
- select * from test where title=“重要的事情说77777遍!”;
红框为没有索引时的时间,蓝框为建立索引后的时间。十万条数据下,快了两个数量级。数据更多时,差距更大。
- 索引的字段就相当于字典里的笔画拼音等,是一个依据,只有根据它查找时,才会更快。如果有多个字段,根据其它字段查找,并不会变快。
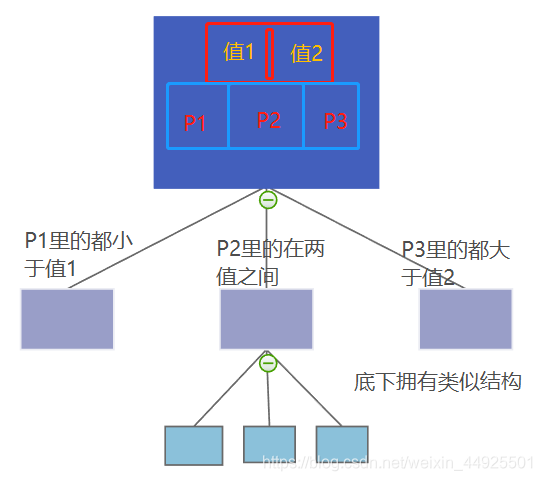
- 索引通过不断地缩小想要获得数据的范围来筛选出最终想要的结果。相当于一个树。下面是一个B+树。
3)查看索引

- keyname表示索引的表,colum_name表示索引的字段。

- 上图是什么? 我们查询了一个没有添加过索引的表的索引。发现有三个索引。原来是生成主键和外键时,自动生成了索引。
4)删除索引
drop index 索引名 on 表名;
5)注意
- 建立太多的索引将会影响更新和插入的书读。因为它同样需要更新每个索引文件。如果更新修改的频率大,查询频率小,就没有必要建立索引了。比较小的表,也没有必要建立索引。
- 索引要占用磁盘空间。
四、账户管理(需要时查文档即可)
1)授予权限
1>理解用户概念
--使用mysql数据库。(数据库信息存在这个数据库里。)
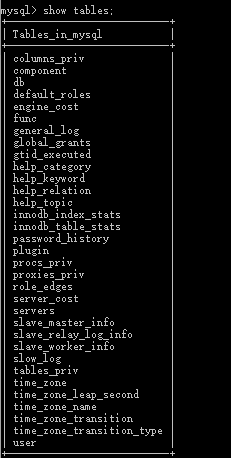
- use mysql;
- show tables;
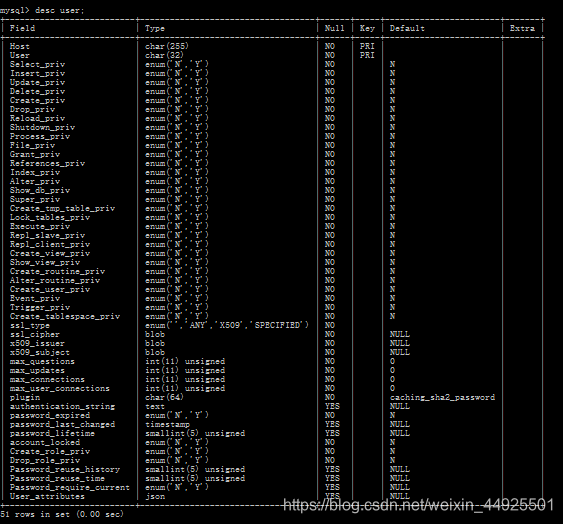
-- 可以看到有许多张表。user表里存着root用户信息。接下来查看user的字段。- desc user;
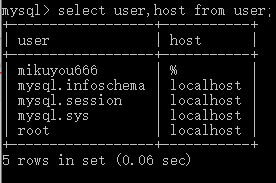
--可以看到有许多的字段。- select user,host from user;
左边一列,表示可以登录mysql的用户。右边表示可以通过哪个地方登录, % 表示任意一台电脑登录,localhost表示只能本地登录。
--查看密码(加密过的密码)- select host,user,authentication_string from user;

2>创建用户demo
创建用户: create user ‘用户名’@‘访问主机’ identified by ‘密码’;
给与权限: grant 权限列表 on 数据库 to ‘用户名’@‘访问主机’;
--创建的前提是以root管理员登录
create user ‘tom’@‘localhost’ identified by ‘123456’;
grant select on shop.* to ‘tom’@‘localhost’;

3>删除账号
drop user ‘名’@‘密’;
3>更多操作
官方对创建用户的签名
官方对Grant的说明
不要用远程登录。只要注释了IP,就给了别人可乘之机。IP和端口可以用扫描仪,账户一般都有一个‘root‘,密码暴力破解。数据库的大门自向别人打开。
