性能优化做的好,bug也会绕道跑
首先作为一个前端,除了会写页面的话,最应该掌握的技术就是如何将你的页面性能进行优化,只要你有优化的意识,那样你写出来的页面才能称得上前端页面开发。
-
出发点1:URL路径的剖析
首先我们要知道一个页面是怎么加载出来的:给大家画个示意图吧。
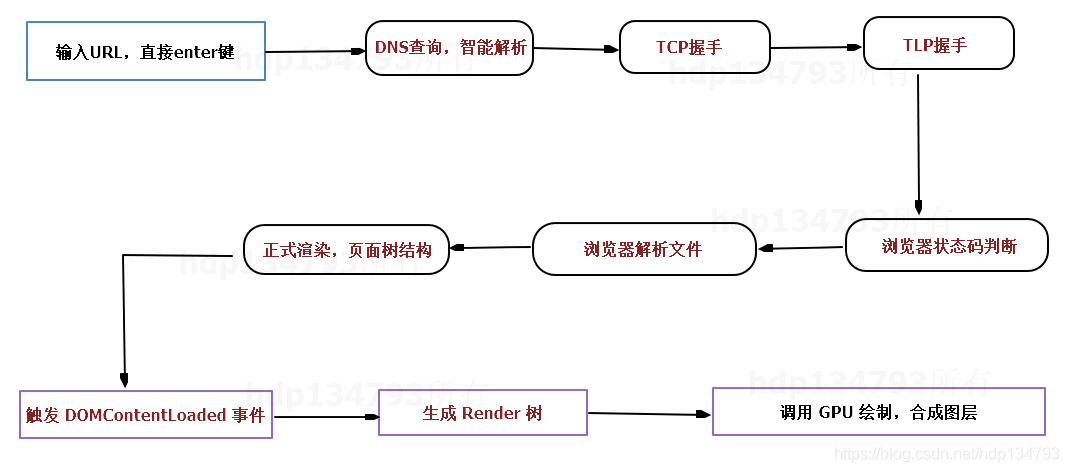
主要页面渲染你可以看这个详细说明:
A.首先做 DNS 查询,如果这一步做了智能 DNS 解析的话,会提供访问速度最快的 IP 地址回来
B.接下来是 TCP 握手,应用层会下发数据给传输层,这里 TCP 协议会指明两端的端口号,然后下发给网络层。网络层中的 IP 协议会确定 IP 地址,并且指示了数据传输中如何跳转路由器。然后包会再被封装到数据链路层的数据帧结构中,最后就是物理层面的传输了
C.TCP 握手结束后会进行 TLS 握手,然后就开始正式的传输数据
数据在进入服务端之前,可能还会先经过负责负载均衡的服务器,它的作用就是将请求合理的分发到多台服务器上,这时假设服务端会响应一个 HTML 文件.
D.首先浏览器会判断状态码是什么,如果是 200 那就继续解析,如果 400 或 500 的话就会报错,如果 300 的话会进行重定向,这里会有个重定向计数器,避免过多次的重定向,超过次数也会报错
E.浏览器开始解析文件,如果是 gzip 格式的话会先解压一下,然后通过文件的编码格式知道该如何去解码文件
F.文件解码成功后会正式开始渲染流程,先会根据 HTML 构建 DOM 树,有 CSS 的话会去构建 CSSOM 树。如果遇到 script 标签的话,会判断是否存在 async 或者 defer ,前者会并行进行下载并执行 JS,后者会先下载文件,然后等待 HTML 解析完成后顺序执行,如果以上都没有,就会阻塞住渲染流程直到 JS 执行完毕。遇到文件下载的会去下载文件,这里如果使用 HTTP 2.0 协议的话会极大的提高多图的下载效率。
G.初始的 HTML 被完全加载和解析后会触发 DOMContentLoaded 事件
H.CSSOM 树和 DOM 树构建完成后会开始生成 Render 树,这一步就是确定页面元素的布局、样式等等诸多方面的东西
I.在生成 Render 树的过程中,浏览器就开始调用 GPU 绘制,合成图层,将内容显示在屏幕上了
过程总结
我们从输入 URL 到显示页面这个过程中,涉及到网络层面的,有三个主要过程:
(1)DNS 解析
(2)TCP 连接
(3)HTTP 请求/响应
对于 DNS 解析和 TCP 连接两个步骤,我们前端可以做的努力非常有限。相比之下,HTTP 连接这一层面的优化才是我们网络优化的核心。
明确方向
HTTP 优化有两个大的方向: -
减少请求次数;
-
减少单次请求所花费的时间。
-
出发点2:浏览器缓存机制
浏览器缓存机制有四个方面,它们按照获取资源时请求的优先级依次排列如下:
Memory Cache
Service Worker Cache
HTTP Cache
Push Cache
MemoryCache
MemoryCache,是指存在内存中的缓存。从优先级上来说,它是浏览器最先尝试去命中的一种缓存。从效率上来说,它是响应速度最快的一种缓存。浏览器秉承的是“节约原则”,我们发现,Base64 格式的图片,几乎永远可以被塞进 memory cache,这可以视作浏览器为节省渲染开销的“自保行为”;此外,体积不大的 JS、CSS 文件,也有较大地被写入内存的几率——相比之下,较大的 JS、CSS 文件就没有这个待遇了,内存资源是有限的,它们往往被直接甩进磁盘。
Service Worker Cache
Service Worker 是一种独立于主线程之外的 Javascript 线程。它脱离于浏览器窗体,因此无法直接访问 DOM。这样独立的个性使得 Service Worker 的“个人行为”无法干扰页面的性能,这个“幕后工作者”可以帮我们实现离线缓存、消息推送和网络代理等功能。我们借助 Service worker 实现的离线缓存就称为 Service Worker Cache。
HTTP Cache
它又分为强缓存和协商缓存。优先级较高的是强缓存,在命中强缓存失败的情况下,才会走协商缓存。
对一条http get 报文的基本缓存处理过程包括7个步骤:
1、接收;
2、解析;
3、查询,缓存查看是否有本地副本可用,如果没有,就获取一份副本;
4、新鲜度检测, 缓存查看已缓存副本是否足够新鲜,如果不是,就询问服务器是否有任何更新;
5、创建响应,缓存会用新的首部和已缓存的主体来构建一条响应报文;
6、发送,缓存通过网络将响应发回给客服端;
7、日志。
Push Cache
Push Cache 是指 HTTP2 在 server push 阶段存在的缓存。
Push Cache 是缓存的最后一道防线。浏览器只有在 Memory Cache、HTTP Cache 和 Service Worker Cache 均未命中的情况下才会去询问 Push Cache。
Push Cache 是一种存在于会话阶段的缓存,当 session 终止时,缓存也随之释放
不同的页面只要共享了同一个 HTTP2 连接,那么它们就可以共享同一个 Push Cache。
最后希望大家能够在这文章中学到一些东西,哪怕一点点,一起加油,早日拿高薪升职,嘿嘿,喜欢的话可以给个心心或者关注哈,么么哒