论文解读:Combining Distant and Direct Supervision for Neural Relation Extraction

夏栀的博客——王嘉宁的个人网站 正式上线,欢迎访问和关注:http://www.wjn1996.cn
远程监督关系抽取一直存在一个问题就是噪声,现如今有诸多工作来解决噪声问题,本文创新点在于结合了远程监督和普通监督学习来实现降噪。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 远程监督关系抽取 |
| 4 | 核心内容 | Relation Extraction |
| 5 | GitHub源码 | https://github.com/allenai/comb_dist_direct_relex/ |
| 6 | 论文PDF | https://www.aclweb.org/anthology/N19-1184.pdf |
二、全文摘要翻译
远程监督关系抽取任务中,噪声数据使得模型很难达到更高的质量,先前的工作通过利用注意力机制为每个句子进行加权求和来解决这个问题,我们提出一种结合直接监督学习的远程监督学习方法来改进这些模型。我们发现联合这两种监督模式的模型更能识别出噪声数据。另外我们发现基于sigmod的注意力和最大池化计算比加权平均效果更好。我们提出的模型在FB-NYT数据集上获得最优效果。
三、相关工作
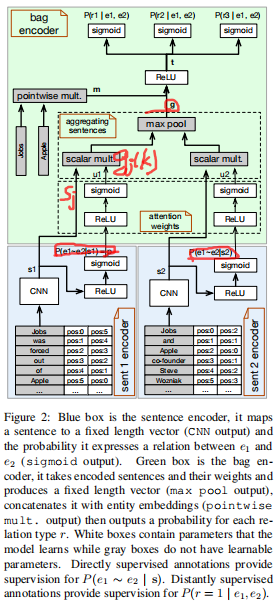
解决噪声的诸多策略中,作者提出一种结合监督学习和远程监督的方法。这一类方法也曾经被其他工作所采用,但它们的做法只是简单的将两种类型的数据集结合起来,作者在后续发现这种策略并没有多少提升,因此作何认为能够真正结合两种不同的监督模式的办法则是利用multi-task训练。大致的解决方法如图所示:

模型一共包括两个主要部分——sentence-level encoder用于执行supervision任务,bag-level encoder用于解决distant supervision任务。
首先输入一个句子(示例),由于远程监督基于启发式的知识库与语料对齐的强假设,给定的句子虽然包含的实体在知识库中是有关系的,但这个句子所表达的语义不一定有关系,因此句子表征部分除了生成一个向量
外,还会得到一个输出
,其是一个0-1分布,其中0表示这个句子是一个噪声(Negtive),1表示这个句子不是噪声(Positive)。
对于所有包含相同实体对的句子,每个句子都将会得到一个
,通过一系列的计算生成对每个句子的权重分布attention,并将权重与每个句子向量sentence embedding进行乘积,再在每个维度上进行最大池化,得到bag embedding。最终的输出则是对每个类型的0-1分布。
所以,当一个句子是噪声时,由
则可以得到其较低的权重,从而有助于降噪。因此sentence和bag两部分即分别表示direct supervision和distant supervision。
四、提出的方法
整体模型如图所示:
输入一个句子
,给定GloVe词向量表,则可以得到这个句子的word embedding,另外和其他工作一样引入位置表征
,则输入表征为
。
然后使用一个卷积神经网络对句子进行特征提取,并应用最大池化层映射到一个向量,卷积核的尺寸选择
,并将每个卷积核卷积核池化后的向量拼接起来,并一同喂入一个全连接网络中,即:
如果将 喂入一个带有RELU和sigmod的两层神经网络中,则可以得到对这个句子的positive和negative的分布: 。这个分布式一个0-1分布。0表示这个句子是噪声(或没有关系)。
接下来是bag层的编码。对于每一个句子,作者依然采用attention。计算方法相比传统方法不同之处在于使用了max-pool。Attention分为两步:
(1)计算Attention: 根据上面计算的
分布,将其再次喂入一个含有ReLU的神经网络中,并进行归一化则可以得到每个句子的权重,记做:
,其中
是
的简写。
(2)Max-pooling: 根据权重,可以得到每个句子
表征向量的加权向量,记做
,其中
表示CNN表征向量的第
个维度。因此最大池化后可以得到一个包的表征:
,其中
表示包中句子的数量。可知
的维度与
维度相等。
模型的输出部分并非是对每个类的概率分布,而是对每个类的0-1分布,作者将其作为一个multi-label分类任务对待。输出部分表示为 ,其中 表示实体向量的直乘(这一部分表示实体自身信息的增强)。
模型的训练采用多任务学习方法,loss包括两部分,分别为distant部分(DistSupLoss)和direct supervision(DirectSupLoss)。远程监督部分采用交叉信息熵,如果当前预测的类与两个实体组成的三元组出现在知识库中,则表示1( ),否则为0。因为其分布并不是所有类上的概率分布,而是一系列的0-1分布(即属于0和1的概率分布),因此对于每个类进行一次计算。计算如下:
对于direct supervision部分,作者先使用supervision的数据进行学习,训练得到的参数用于distant supervision任务中,因此这一部分也包括loss,计算如下:
其中 表示direct supervision数据集, 表示golden label。两个loss进行加权求和:
, 是模型学习的参数。
五、实验分析
作者在FB-NYT数据集上进行实验,选择direct supervision数据集是[Combining distant and partial supervision for relation extraction]一文提供的数据集,其将该数据集进行了修改,将句子标签改为有关系的positive和无关系的negative。作者采用Multi-Task训练方法,对两个数据集同时训练。因为我们知道FB-NYT是没有关于句子是否为噪声的label,因此作者用另外一个数据集充当学习的经验,Multi-Task方法能够使用同一个模型来完成这项工作,将训练的参数保留下来,用于评估FB-NYT数据集中句子是否是噪声,并给出权重。
(1)作者首先与几个基线模型进行对比,评价指标为PR曲线和AUC面积,如图:

(2)其次,作者对sentence-level attention部分选择的模式进行比对,模式包括选用的max-pooling和avg,激活函数包括uniform和sigmod。对比结果如下:

通过比对发现当选用sigmod和max-pooling时效果最好。
(3)最后作者分析了多任务学习过程中,两个loss之间的权重系数 ,作者选择了一些参数 ,并进行了对比,实验结构表明, 时达到最好。实验结果如图所示(竖向黑色曲线表示变化幅度,作者对每个 进行了三次实验,蓝色曲线则表示均值):

六、总结
这篇工作巧妙的利用其它监督数据企图学习含有噪声数据,是一种不错的研究思路,也融合了Multi-Task和Multi-Label。不过,是否利用其它监督数据就能很好的判断某个示例是否是噪声?这个作者并没有给出一些解释,实验上的效果是否是偶然?
