论文信息:论文,AAAI2020
概述
关系抽取旨在从非结构化文本中抽取结构化的三元组,比如从文本“ Barack Obama was born in the United States”中识别实体"Barack Obama"和"United States"的关系是"born in",从而得到(Barack Obama,born in,United States)这个三元组。该任务一个主要的问题是缺乏大量人工标注数据,因此基于远程监督构造监督数据的方式(即将文本与Freebase知识库对齐,如果语句中出现了某个三元组中的实体对,就认为该语句表达了对应的关系)逐渐获得广泛研究。
然而,远程监督假设过强,通常面临噪声数据问题,即训练集中部分语句的关系标签是错误的。目前主要有两类解决办法:
- soft方法:将包含同一实体对的句子组成sentence bag,然后为每个句子计算一个权重,为噪声句子分配更低的权重降低它对实体对预测的影响,进而减少噪声影响。
- hard方法:直接从sentence bag中识别噪声句子并剔除掉。
然而这些方法都忽略了问题的真正原因,即正确标签的缺失。因此,该论文转而通过纠正噪声句子的标签来解决这个问题,这样既减少了噪声影响,同时也增加了正确语句的数目。该论文模型DCRE主要包含三个模块:
- 语句编码模块:用于对文本进行编码得到向量
- 噪声检测模块:通过计算sentence bag中的语句和标签之间的匹配程度,挑选出噪声语句
- 标签生成模块:基于深度聚类方法为挑选的噪声语句分配正确的关系标签
方法

问题定义
假定关系集合为\(\mathbb{R}=\{r_1,r_2,\dots,r_k\}\),\(\mathbb{S}_b=\{s_1,s_2,\dots,s_b\}\)是与实体对\((e_1,e_2)\)对应的sentence bag,关系抽取的目的就是根据\(\mathbb{S}_b\)预测实体对\((e_1,e_2)\)的关系\(r_i\)。
文本编码模块
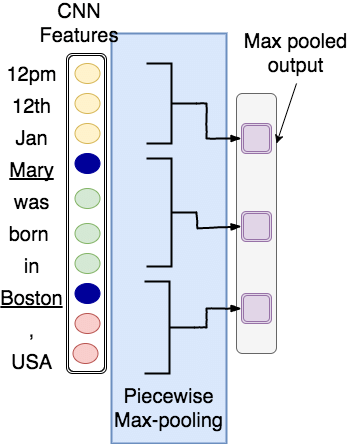
上图展示的就是该论文所使用的文本编码模块,同时也是实体关系抽取中最流行的文本编码器。它的大致流程为:给定一个包含某实体对的文本句,每个词首先被转换为\(d_w\)维的词向量,再拼接根据单词与实体距离计算的两个维度为\(d_p\)的位置向量,最终每个单词向量维度为\(d_s=d_w+2d_p\);拼接得到的句子矩阵送入到CNN网络中提取n-gram特征;根据实体在句中的位置将特征分为三段,每段分别进行最大池化;将池化后的特征拼接得到最终的文本语句编码向量。
噪声检测模块
假定一个sentence bag中文本向量为\(H_b \in \mathbf{R}^{b \times d_s}\),所有的关系向量为\(L \in \mathbf{R}^{k \times d_s}\),其中\(b\)表示bag中语句个数,\(d_s\)表示向量维度,\(k\)为关系数目。语句向量\(h_i\)和关系标签\(l_j\)之间的相关性用点积表示:
\[ \alpha_{i} = h_i l_j^T \]
接着,对一个bag内所有语句相关性使用softmax进行归一化
\[ \alpha_i = \frac{\exp(\alpha_i)}{\sum_b \exp(\alpha_i)} \]
\(\alpha_i\)表示语句关系标签正确的概率。当\(\alpha_i\)小于阈值\(\phi\)时,该语句就被认为是噪声语句。
然而,这样做无法保证相关性更大的语句就不是错误标注的句子。因此该论文做了一些限制:在一个sentence bag中,相关性分数最大的语句被认为是正确语句,相关性分数小于阈值的语句被认为是噪声语句,而夹在中间的语句都会被忽略。这么做有两个好处:1)如果相关性分数最大的语句确实是正确语句,那么选中它作为该bag的正例符合expressed-at-least-one假设;2)如果相关性分数最大的语句都是噪声语句,那忽略其它语句也是一种降噪方式。不管哪种情况,都达到了降噪的目的。
标签生成模块
标签生成模块的目的是为挑选出的噪声句子重新分配高置信度的关系标签,这是通过聚类实现的。假设\(\mathbf{H} \in \mathbf{R}^{n\times d_s}\)是所有文本语句的向量表示,\(\mathbf{L} \in \mathbf{R}^{k \times d_s}\)是所有关系的向量表示。论文的第一步是将文本向量投影到关系空间:
\[ \mathbf{C} = \mathbf{HL}^T + \mathbf{b} \]
然后对\(\mathbf{C}\)进行聚类,产生\(n_c\)个类簇\(\{\mathbf{\mu}_i\}_{i=1}^{n_c}\)。该论文使用\(t\)-分布作为相似度度量函数,因此\(c_i\)和类簇中心\(\mu_i\)的相似度定义为:
\[ q_{ij} = \frac{(1+||\mathbf{c}_i - \mathbf{\mu}_j||^2)^{-1}}{\sum_j(1+||\mathbf{c}_i - \mathbf{\mu}_j||^2)^{-1}} \]

\(q_{ij}\)是投影语句向量\(c_i\)和类簇中心\(\mu_j\)的相似度,也可以看作是给对应的句子\(s_i\)分配关系标签\(r_j\)的概率。
聚类的目标函数使用KL散度定义:
\[ \mathcal{L} = KL(P||Q) = \sum_i \sum_j p_{ij}\log \frac{p_{ij}}{q_{ij}} \]
其中\(P\)是目标分布。因为NYT-10数据集关系服从长尾分布,因此该论文借鉴(Xie,Girshick,and Farhadi 2016)的工作,将\(P\)定义为:
\[ p_{ij}=\frac{q_{ij}^2/\sum_i q_{ij}}{\sum_j(q_{ij}^2/\sum_i q_{ij})} \]
另外,该论文只对非NA语句重新生成关系标签,因为NA(标记为无关系)的句子真实的关系标签通常是难以获知的,给它们分配标签可能会导致更大的噪声。相反的,将非NA语句重标为NA意味着移除了该噪声句子。
缩放损失函数
由于噪声句子没有明显的监督信息,聚类结果很难保证就是对的,也就是说重新分配的标签可能也是错的。因此该论文在挑选噪声句子时,设立了阈值\(\phi\)。除此之外,还将\(q_{ij}\)作为交叉熵损失函数的权重,这种缩放使得聚类得到的标签对于模型的影响正比于其聚类置信度。最终的交叉熵损失函数定义为:
\[ \begin{aligned} \mathcal{J}(\theta) = &-\sum_{(x_i,y_i)\in \mathbb{V}}\log p(y_i|x_i;\Theta) \\ &-\lambda \sum_{(x_i,y_i)\in \mathbb{N}}q_{ij} \log p(y_i|x_i;\Theta) \end{aligned} \]
其中\((x_i,y_i)\)是一个训练实例,表示语句\(x_i\)的关系标签是\(y_i\)。\(y_j \neq y_i\)表示\(x_i\)的新关系标签。\(\mathbb{V}\)是相关性分数最大的语句集合,\(\mathbb{N}\)是挑选的噪声语句集合,\(\Theta\)是模型参数。
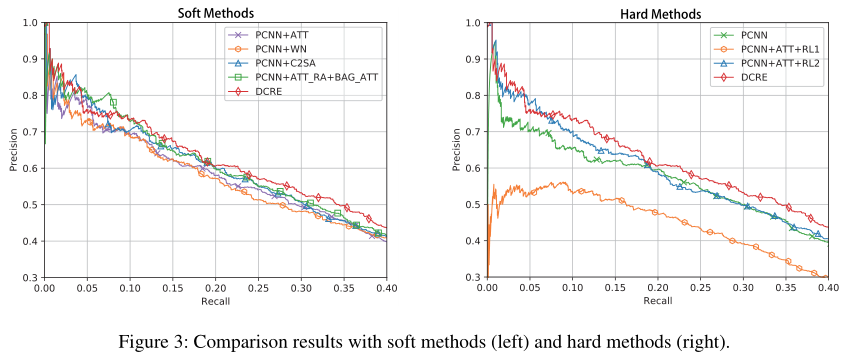
实验
该论文采用经典的NYT-10数据集进行实验,评价指标也是常用的Precision-recall曲线,实验主要结果如下图所示: