(1)lxml解析html
from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,encoding="utf-8").decode("utf-8")
requests+lxml+xpath实现豆瓣电影爬虫
import requests from lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
原始界面:
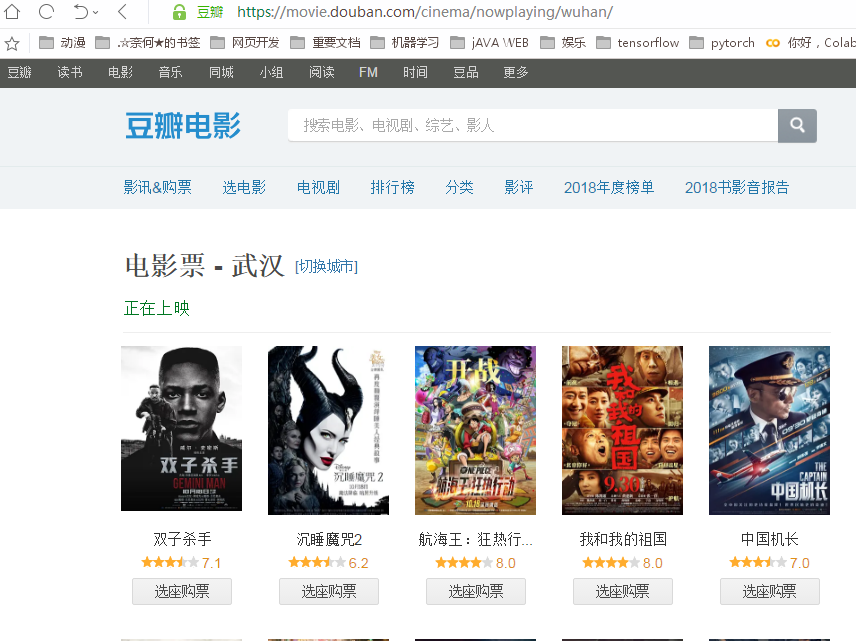
url="https://movie.douban.com/cinema/nowplaying/wuhan/" response=request.get(url,headers=headers) text=response.text html=etree.HTML(text)
我们会得到一个html对象

转换成字符串看下结果
result=etree.tostring(html,encoding="utf-8").decode("utf-8")
部分结果如下:

然后进行xpath解析:
我们对准其中一部电影点击鼠标右键--检查,得到如下视图:

我们发现,上映电影的信息都在带有属性lists的ul中,我们可以对此进行xpath解析,(我们解析的是html对象,而不是转成字符串的结果):
uls=html.xpath("//ul[@class='lists']")[0]
我们在转成字符串查看一下结果:
res=etree.tostring(uls,encoding="utf-8").decode("utf-8") print(res)

正是我们想要的,我们接着解析里面的内容:
首先获取所有的li:
#这句的意思是获取当前uls下的所有直接li
lis=uls.xpath("./li)
结果是一系列的li对象:

我们再分别进行解析:
movies=[] for li in lis: name=li.xpath("@data-title")[0] score=li.xpath("@data-score")[0] country=li.xpath("@data-region")[0] director=li.xpath("@data-director")[0] actors=li.xpath("@data-actors")[0] category=li.xpath("@data-category")[0] movie={ "name":name, "score":score, "country":country, "director":director, "actors":actors, "category":category } movies.append(movie) print(movies)
部分结果如下:

在json中格式化结果如下:

至此,一个初步的爬虫就完成了。