Python3数据分析与挖掘建模实战
Python数据分析简介
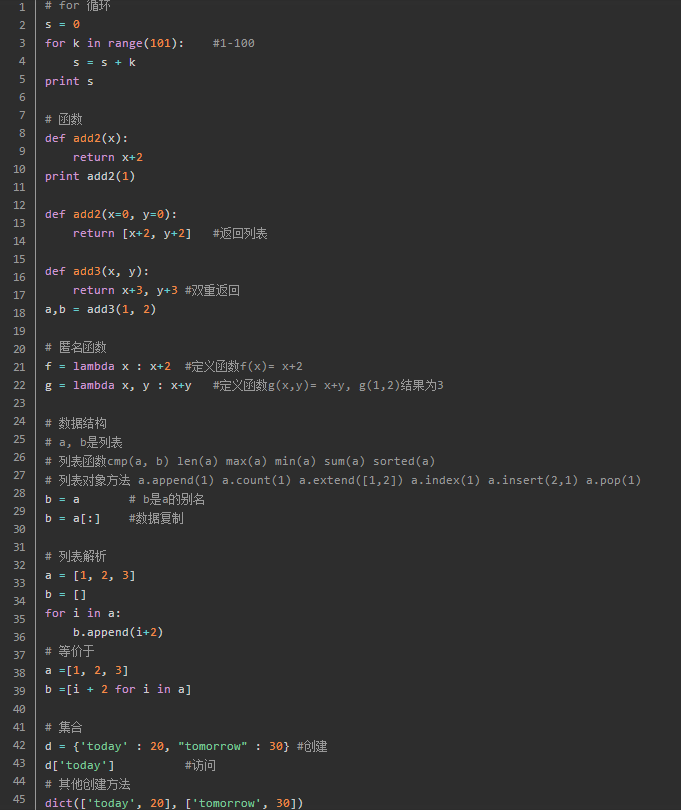
Python入门
运行:cmd下"python hello.py"
基本命令:
第三方库
安装
Windows中
pip install numpy
或者下载源代码安装
python setup.py install
Pandas默认安装不能读写Excel文件,需要安装xlrd和xlwt库才能支持excel的读写
pip install xlrd
pip install xlwt
StatModel可pip可exe安装,注意,此库依赖于Pandas和patsy
Scikit-Learn是机器学习相关的库,但是不包含人工神经网络
model.fit() #训练模型,监督模型fit(X,y),非监督模型fit(X)
# 监督模型接口
model.predict(X_new) #预测新样本
model.predict_proba(X_new) #预测概率
model.score() #得分越高,fit越好
# 非监督模型接口
model.transform() #从数据中学到新的“基空间”
model.fit_transform() #从数据中学到新的基,并按照这组基进行转换
Keras是基于Theano的强化的深度学习库,可用于搭建普通神经网络,各种深度学习模型,如自编码器,循环神经网络,递归神经网络,卷积神经网络。Theano也是一个Python库,能高效实现符号分解,速度快,稳定性好,实现了GPU加速,在密集型数据处理上是CPU的10倍,缺点是门槛太高。Keras的速度在Windows会大打折扣。
Windows下:安装MinGWindows--安装Theano---安装Keras--安装配置CUDA
Gensim用来处理语言方面的任务,如文本相似度计算、LDA、Word2Vec等,建议在Windows下运行。
Linux中
sudo apt-get install python-numpy
sudo apt-get install python-scipy
sudo apt-get install python-matplotlib
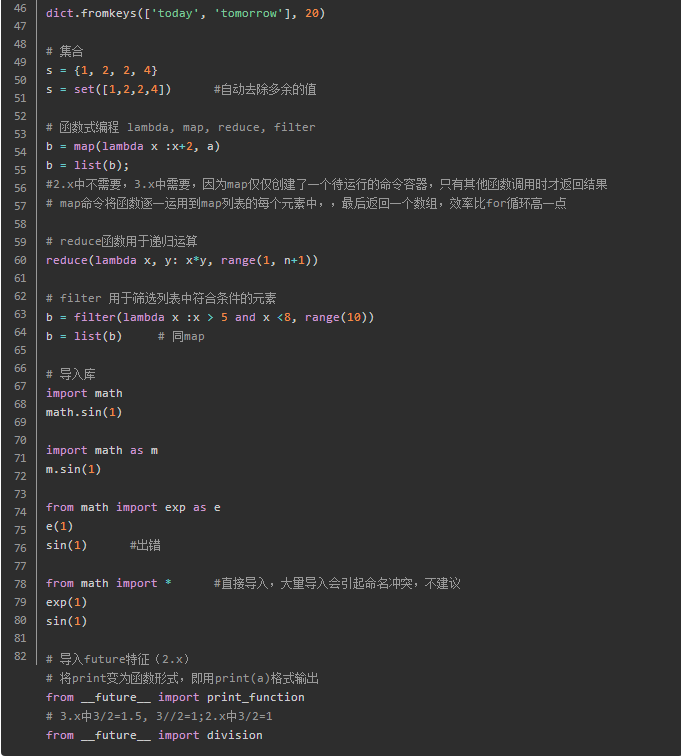
使用
Matplotlib默认字体是英文,如果要使用中文标签,
plt.rcParams['font.sans-serif'] = ['SimHei']
保存作图图像时,负号显示不正常:
plt.rcParams['axes.unicode_minus'] = False
数据探索
脏数据:缺失值、异常值、不一致的值、重复数据
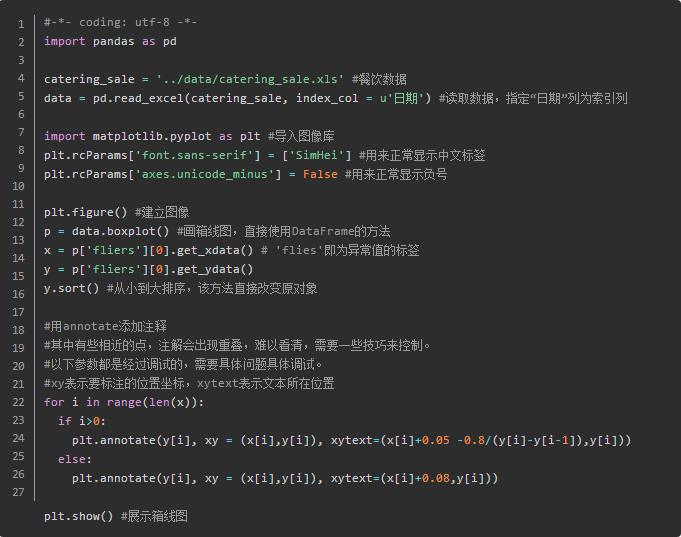
异常值分析
- 简单统计量分析:超出合理范围的值
- 3sigma原则:若正态分布,异常值定义为偏差超出平均值的三倍标准差;否则,可用远离平均值的多少倍来描述。
- 箱型图分析:异常值定义为小于Q_L-1.5IQR或者大于Q_U +1.5IQR。Q_L是下四分位数,全部数据有四分之一比他小。Q_U是上四分位数。IQR称为四分位数间距,IQR=Q_U-Q_L
分布分析
定量数据的分布分析:求极差(max-min),决定组距和组数,决定分点,列出频率分布表,绘制频率分布直方图。
定性数据的分布分析:饼图或条形图
对比分析
统计量分析
集中趋势度量:均值、中位数、众数
离中趋势度量:极差、标准差、变异系数、四份位数间距
变异系数为:s表示标准差,x表示均值

周期性分析
贡献度分析
又称帕累托分析,原理是帕累托法则,即20/80定律,同样的投入放在不同的地方会产生不同的收益。

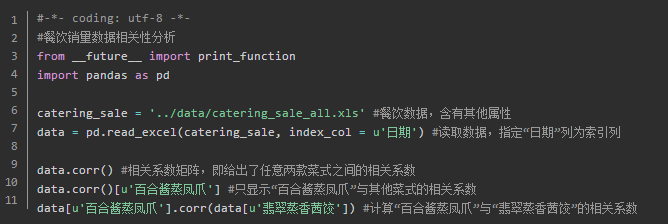
相关性分析
途径:绘制散点图、散点图矩阵、计算相关系数
Pearson相关系数:要求连续变量的取值服从正态分布。
$$
\begin{cases}
{|r|\leq 0.3}&\text{不存在线性相关}\
0.3 < |r| \leq 0.5&\text{低度线性相关}\
0.5 < |r| \leq 0.8&\text{显著线性相关}\
0.8 < |r| \leq 1&\text{高度线性相关}\
\end{cases}
$$
相关系数r的取值范围[-1, 1]
Spearman相关系数:不服从正态分布的变量、分类或等级变量之间的关联性可用该系数,也称等级相关系数。
对两个变量分别按照从小到大的顺序排序,得到的顺序就是秩。R_i表示x_i的秩次,Q_i表示y_i的秩次。
判定系数:相关系数的平方,用来解释回归方程对y的解释程度。
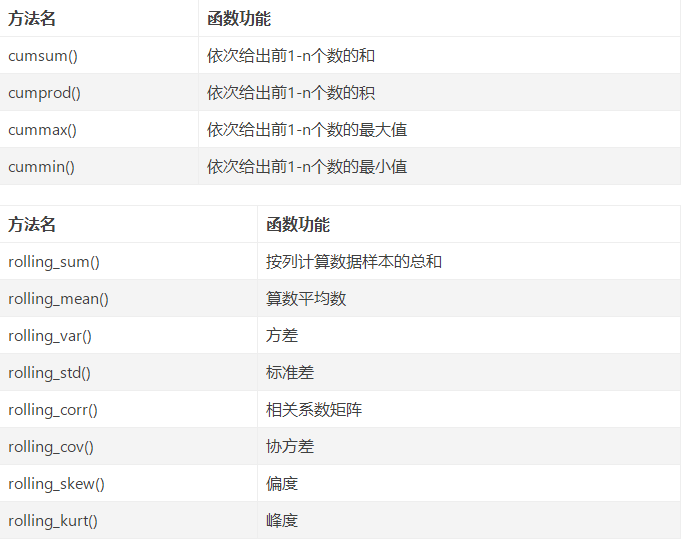
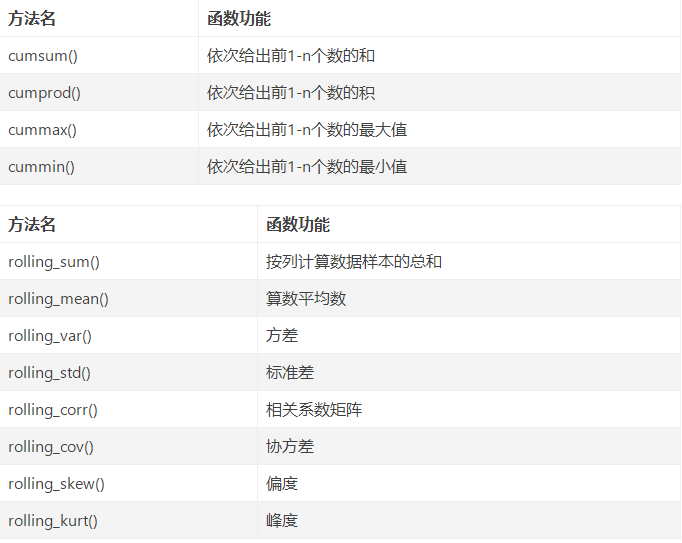
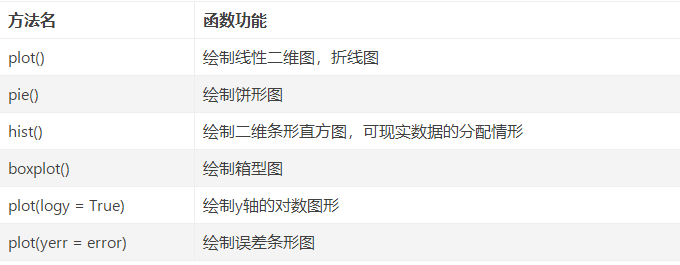
数据探索函数




电子商务网站用户行为分析及服务推荐
数据抽取:建立数据库--导入数据--搭建Python数据库操作环境
数据分析
- 网页类型分析
- 点击次数分析
- 网页排名
数据预处理
- 数据清洗:删除数据(中间页面网址、发布成功网址、登录助手页面)
- 数据变化:识别翻页网址并去重,错误分类网址手动分类,并进一步分类
- 属性规约:只选择用户和用户选择的网页数据
模型构建
基于物品的协同滤波算法:计算物品之间的相似度,建立相似度矩阵;根据物品的相似度和用户的历史行为给用户生成推荐列表。
相似度计算方法:夹角余弦、Jaccard系数、相关系数
财政收入影响因素分析及预测模型
数据分析
- 描述性统计分析
- 相关分析
模型构建
对于财政收入、增值税、营业税、企业所得税、政府性基金、个人所得税
- Adaptive-Lasso变量选择模型:去除无关变量
- 分别建立灰色预测模型与神经网络模型
基于基站定位数据的商圈分析
数据预处理
- 属性规约:删除冗余属性,合并时间属性
- 数据变换:计算工作日人均停留时间、凌晨、周末、日均等指标,并标准化。
模型构建
- 构建商圈聚类模型:采用层次聚类算法
- 模型分析:对聚类结果进行特征观察
电商产品评论数据情感分析
文本采集:八爪鱼采集器(爬虫工具)
文本预处理:
- 文本去重:自动评价、完全重复评价、复制的评论
- 机械压缩去词:
- 删除短句
文本评论分词:采用Python中文分词包“Jieba”分词,精度达97%以上。
模型构建
- 情感倾向性模型:生成词向量;评论集子集的人工标注与映射;训练栈式自编码网