spark版本
spark 1.6.1
从Rdd的action开始追源码,最后都会到rdd.runJob
|
|
可以看到接下来调用了dagScheduler.runJob
|
|
eventProcessLoop是DAGSchedulerEventProcessLoop类的实例,DAGSchedulerEventProcessLoop类是EventLoop的子类。EventLoop里有一个阻塞队列,post函数往队列里放请求,还有开启了一个线程不断从队列里取请求。
以上代码总结,往队列里放了一个JobSubmitted的请求,然后需要处理JobSubmitted请求了
|
|
newResultStage函数 通过传入finalRDD最后返回finalStage (stage之间和rdd之间都会有依赖关系, newResultStage函数是 通过rdd之间的依赖关系 划分stage的)
继续看源码
|
|
以上代码是为了获取finalRDD对应finalStages的所有依赖父Stage
|
|
以上代码是找到finalRdd的直接父Stage。并在找到直接宽依赖rdd的时候,对先找到这些rdd的所有祖先宽依赖,再对这些祖先宽依赖进行注册(这里也会划分stage)。
下面的代码是如果找到rdd的所有祖先宽依赖(直接或间接)
|
|
下面举一个例子来说明划分stage的过程
图说明:12表示finalRdd,蓝色表示宽依赖,黑色表示窄依赖
1、newResultStage函数 入参12号finalRdd, 通过函数getParentStagesAndId得到finalRdd的直接宽依赖9,10,4,5号Rdd在的Stage。并且注册9,10,4,5号Rdd在的Stage对应的所有直接或间接Stage(通过getParentStagesAndId下的getShuffleMapStage函数)
2、getShuffleMapStage函数 入参(举例:10号Rdd在的Stage), 通过函数getAncestorShuffleDependencies得到10号Rdd的所有直接或间接宽依赖(宽依赖有2号和3号),并通过函数newOrUsedShuffleStage进行注册2号和3号成为新的Stage
最后划分的Stage如下图所示: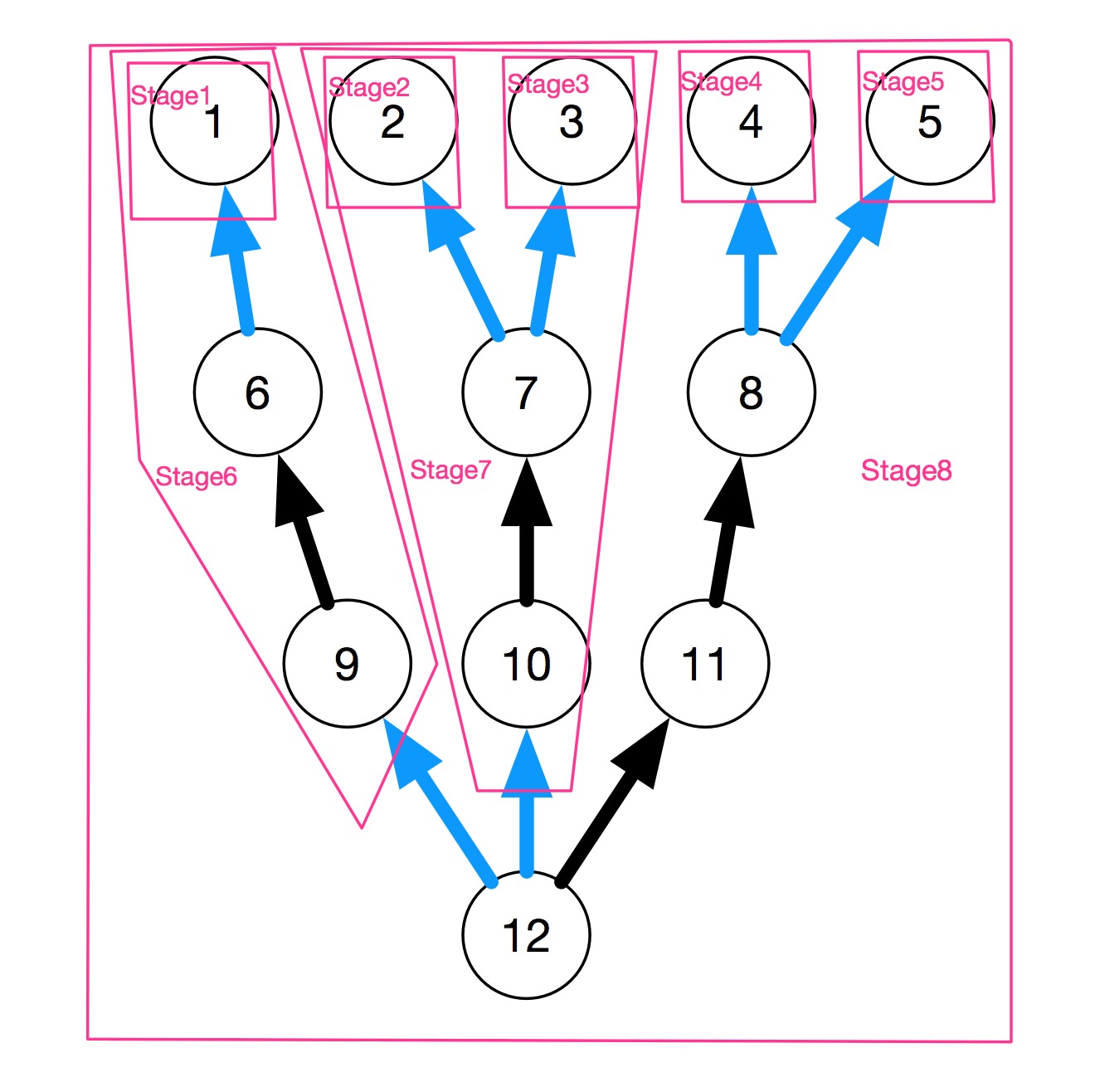
回到DAGScheduler.handleJobSubmitted函数
以上部分完成了handleJobSubmitted函数的newResultStage步骤(划分Stage),函数还有submitStage步骤
|
|
继续以上面的图为例,submitStage(Stage8) => getMissingParentStages(Stage8) 得到 Stage4, Stage5, Stage6, Stage7
再递归提交submitStage(Stage4), submitStage(Stage5),submitStage(Stage6),submitStage(Stage7)…
最后能调用submitMissingTasks函数的有Stage1, Stage2, Stage3, Stage4, Stage5
waitingStages记录待提交有Stage6, Stage7, Stage8.最后通过DAGScheduler.handleJobSubmitted的submitWaitingStages处理这些待提交的Stage
|
|
先告一段落..