原文链接:http://tecdat.cn/?p=7318
产品可以根据销售者进行分类
在Evolution上,有一些顶级类别(“药品”,“数字商品”,“欺诈相关”等)细分为特定于产品的页面。每个页面包含不同供应商的几个列表。
我根据供应商同现关系在产品之间建立了一个图表,即每个节点对应于一种产品,其边权重由同时出售两种事件产品的供应商数量定义。因此,举例来说,如果有3个供应商同时出售甲斯卡林和4-AcO-DMT,那么我的图在甲斯卡林和4-AcO-DMT节点之间的权重为3。我使用 基于随机块模型的分层边缘 实现来生成以下Evolution产品网络的可视化:
代码片段
importimport pandaspandas asas pdpd
importimport graph_toolgraph_t as gt
import graph_tool.draw
import graph_tool.community
import itertools
import collections
import matplotlib
import math
In [2]:
gt.draw.graph_draw(g, pos=pos, vertex_fill_color=b,
edge_control_points=cts,
vertex_size=20,
vertex_text=g.vertex_properties['label'],
vertex_text_rotation=g.vertex_properties['text_rot'],
vertex_text_position=1,
vertex_font_size=20,
vertex_font_family='mono',
vertex_anchor=0,
vertex_color=b,
vcmap=matplotlib.cm.Spectral,
ecmap=matplotlib.cm.Spectral,
edge_color=g.edge_properties['color'],
bg_color=[0,0,0,1],
output_size=[1024*2,1024*2],
output='/home/aahu/Desktop/evo_nvends={0}.png'.format(MIN_SHARED_VENDORS))
saving to disk...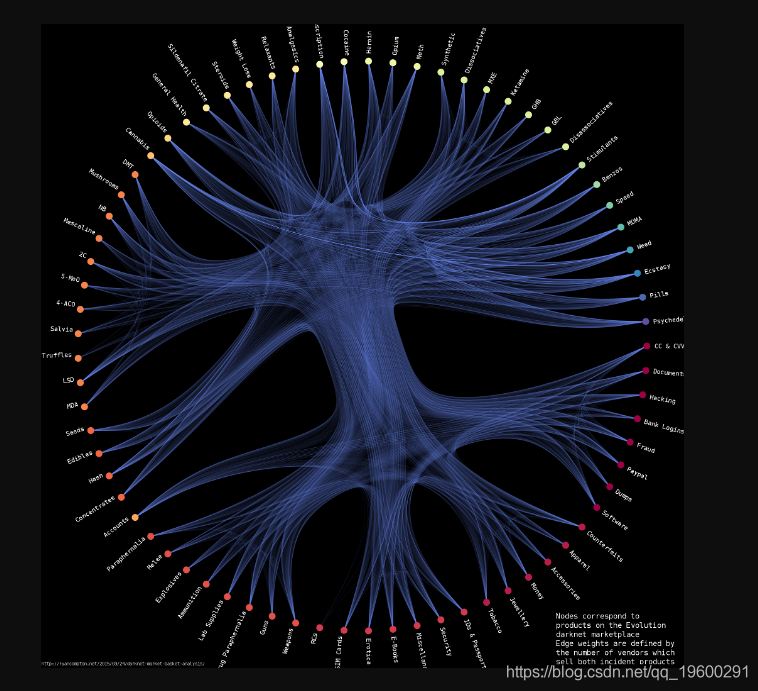
![]()
它包含73个节点和2,219个边缘(我在数据中找到了3,785个供应商)。
代码片段:
# coding: utf-8
from bs4 import BeautifulSoup
import re
import pandas as pd
import dateutil
import os
import logging
def main():
for datestr in os.listdir(DATA_DIR):
d1 = os.path.join(DATA_DIR, datestr)
fdate = dateutil.parser.parse(datestr)
catdir = os.path.join(d1,'category')
if os.path.exists(catdir):
logger.info(catdir)
df = catdir_to_df(catdir, fdate)
outname ='category_df_'+datestr+'.tsv'
df.to_csv(os.path.join(DATA_DIR,outname),'\t',index=False)
if __name__=='__main__':
main()权重较高的边缘绘制得更明亮。节点使用随机块模型进行聚类,并且同一聚类中的节点被分配相同的颜色。图的上半部分(对应于毒品)和下半部分(对应于非毒品,即武器/黑客/信用卡/等)之间有明显的分界。这表明销售毒品的供应商销售非毒品的可能性较小,反之亦然。
91.7%的出售速度
关联规则学习是解决市场篮子分析问题的一种直接且流行的方法。传统的应用是根据其他顾客的购物车向购物者推荐商品。由于某些原因,典型的例子是“购买尿布的顾客也购买啤酒”。
我们没有来自Evolution上公开帖子的抓取的客户数据。但是,我们确实拥有每个供应商所销售产品的数据,可以帮助我们量化上述视觉分析所建议的结果。
这是我们的数据库的示例(完整的文件有3,785行(每个供应商一个)):
| Vendor | Products |
|---|---|
| MrHolland | [‘Cocaine’, ‘Cannabis’, ‘Stimulants’, ‘Hash’] |
| Packstation24 | [‘Accounts’, ‘Benzos’, ‘IDs & Passports’, ‘SIM Cards’, ‘Fraud’] |
| Spinifex | [‘Benzos’, ‘Cannabis’, ‘Cocaine’, ‘Stimulants’, ‘Prescription’, ‘Sildenafil Citrate’] |
| OzVendor | [‘Software’, ‘Erotica’, ‘Dumps’, ‘E-Books’, ‘Fraud’] |
| OzzyDealsDirect | [‘Cannabis’, ‘Seeds’, ‘MDMA’, ‘Weed’] |
| TatyThai | [‘Accounts’, ‘Documents & Data’, ‘IDs & Passports’, ‘Paypal’, ‘CC & CVV’] |
| PEA_King | [‘Mescaline’, ‘Stimulants’, ‘Meth’, ‘Psychedelics’] |
| PROAMFETAMINE | [‘MDMA’, ‘Speed’, ‘Stimulants’, ‘Ecstasy’, ‘Pills’] |
| ParrotFish | [‘Weight Loss’, ‘Stimulants’, ‘Prescription’, ‘Ecstasy’] |
关联规则挖掘是计算机科学中的一个巨大领域–在过去的二十年中,已经发表了数百篇论文。
我运行的FP-Growth算法的最小允许支持为40,最小允许置信度为0.1。该算法学习了12,364条规则。
| 规则前项 | 后项 | 支持度 | 置信度 |
|---|---|---|---|
| [‘Speed’, ‘MDMA’] | [‘Ecstasy’] | 155 | 0.91716 |
| [‘Ecstasy’, ‘Stimulants’] | [‘MDMA’] | 310 | 0.768 |
| [‘Speed’, ‘Weed’, ‘Stimulants’] | [‘Cannabis’, ‘Ecstasy’] | 68 | 0.623 |
| [‘Fraud’, ‘Hacking’] | [‘Accounts’] | 53 | 0.623 |
| [‘Fraud’, ‘CC & CVV’, ‘Accounts’] | [‘Paypal’] | 43 | 0.492 |
| [‘Documents & Data’] | [‘Accounts’] | 139 | 0.492 |
| [‘Guns’] | [‘Weapons’] | 72 | 0.98 |
| [‘Weapons’] | [‘Guns’] | 72 | 0.40 |
如果您有任何疑问,请在下面发表评论。

大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]()
QQ:3025393450
![]() QQ交流群:186388004
QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询

欢迎选修我们的R语言数据分析挖掘必知必会课程!

大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]()
QQ:3025393450
![]() QQ交流群:186388004
QQ交流群:186388004
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询
欢迎选修我们的R语言数据分析挖掘必知必会课程!