FP-growth算法
项目背景/目的
对于广告投放而言,好的关联会一定程度上提高用户的点击以及后续的咨询成单
对于产品而言,关联分析也是提高产品转化的重要手段,也是大多商家都在做的事情,尤其是电商平台
曾经我用SPSS Modeler做过Apriori关联分析模型,也能满足需求,但是效果自然是不及python了,这里分享一下操作流程
还有一周就双十一了,那不妨去看看产品关联背后的原理
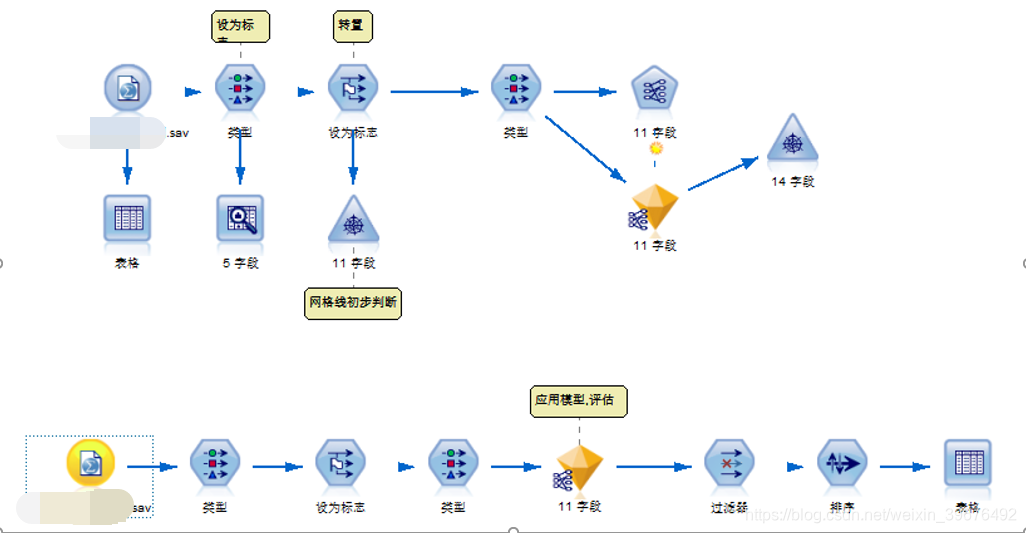
项目原理
步骤一 数据处理
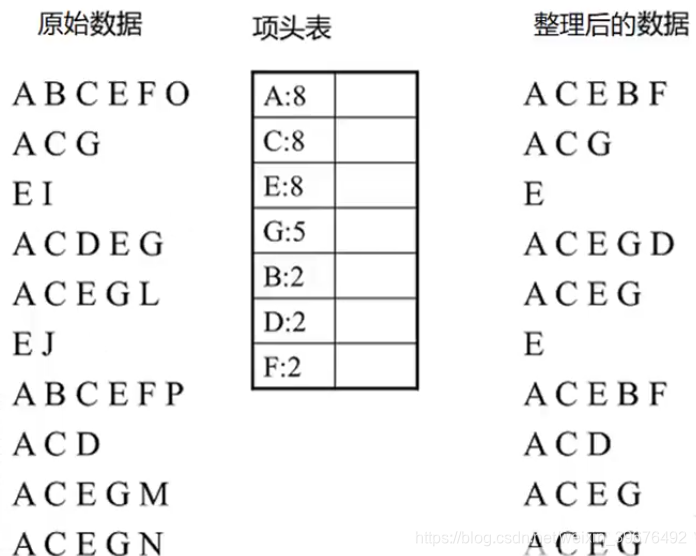
1.遍历所有的数据集合,计算所有项的支持度(次数)
2.丢弃非频繁项(次数小于2)
3.再对所有出现次数降序排列
4.对所有的数据集按照支持度排序,并丢弃非频繁项
~ 到这一步整个数据就处理好了,后面就是生成FP tree以及节点链表
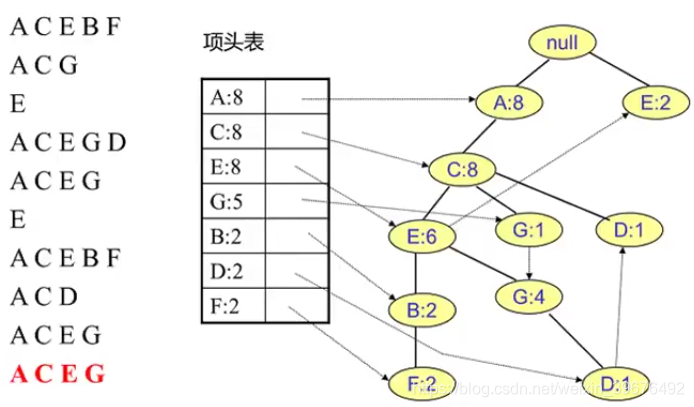
步骤二 FP树创建
1.读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项,这里讲根节点设置为null,就是指根节点不包括任何的项,是为了任何一个数据集进来都被视为空项开始的
2.每新增一个计数加1,没有重合则新增一个节点
步骤三 从FP数中挖掘频繁项集
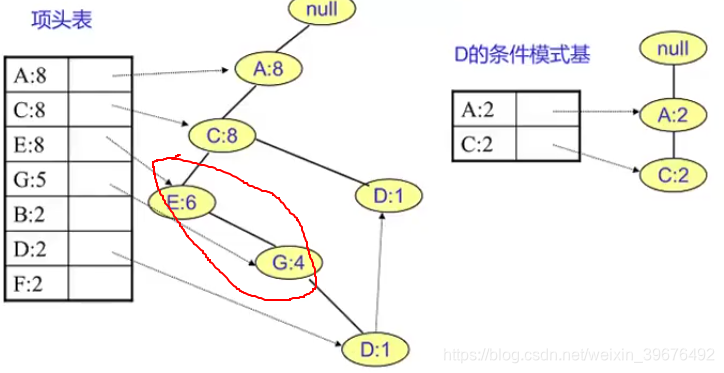
1.对头部链表进行降序排序
2.对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集
也就是说对项头表频率最小的开始,找对其对于的叶子节点并计数,也就是其对应的条件模式基
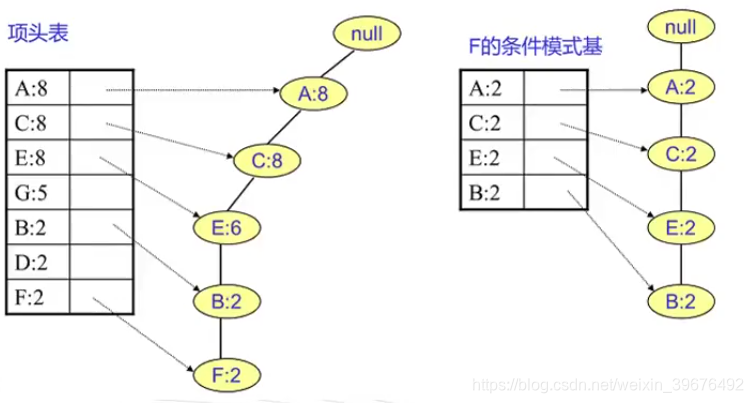
这里的叶子节点计数为 {A:2,C:2,E:1,G:1,D:1},删除阈值小于2的 故只有A,C
代码解释
FP树的节点结构
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue # 节点名称
self.count = numOccur # 节点出现次数
self.nodeLink = None # 不同项集的相同项通过nodeLink连接在一起
self.parent = parentNode # 指向父节点
self.children = {} # 存储叶子节点
def inc(self, numOccur):
"""inc(对count变量增加给定值)
"""
self.count += numOccur
def disp(self, ind=1):
"""disp(用于将树以文本形式显示)
"""
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)
def __lt__(self, other):
return self.count < other.count
读取数据并调用createTree方法,设置频繁项集(也就是出现次数这里是100000)
parsedDat = [line.split() for line in open('kosarak.dat').readlines()]
initSet = createInitSet(parsedDat)
myFPtree, myHeaderTab = createTree(initSet, 100000)
调用mineTree方法
myFreList = []
mineTree(myFPtree, myHeaderTab, 100000, set([]), myFreList)
print(myFreList)
由于代码量较大就不一一copy上了
结论
最终输出如下结果,eg:浏览(购买)过1的同时也浏览(购买)了6,几百万的数据量运行也是很快的

❤❤❤
最后感谢AI Learning团队,网址附上(http://www.apachecn.org)有兴趣的小伙伴可以去看看,很nice的一个组织
扫描二维码关注公众号,回复:
3956736 查看本文章
