关联规则算法Apriori以及FP-growth学习
最近选择了关联规则算法进行学习,目标是先学习Apriori算法,再转FP-growth算法,因为Spark-mllib库支持的关联算法是FP,随笔用于边学边记录,完成后再进行整理
一、概述
关联规则是一种常见的推荐算法,用于从发现大量用户行为数据中发现有强关联的规则。常用于回答“那些商品经常被同时购买”的问题,最经典的用途就是“购物篮分析”,也就是“尿布和啤酒”,用于在商场中发现顾客经常一起购买的商品,从而优化货物摆放。
从大规模数据集中寻找物品间的隐含关系被称作关联分析(association analysis)或者关联规则学习(association rule learning)。这里的主要问题在于,寻找物品的不同组合是一项十分耗时的任务,所需的计算代价很高,蛮力搜索方法并不能解决这个问题,所以需要用更智能的方法在合理的时间范围内找到频繁项集。本文分别介绍如何使用Apriori算法和FP-growth算法来解决上述问题。
二、关联分析
关联分析是在大量数据中寻找存在关系的任务。这些关系可能有两种
●频繁项集
●关联规则
频繁项集(frequent item sets)是经常出现在一块儿的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
举例说明,给出某店销售清单:
| 订单号 | 商品 |
| 1 | 豆奶、莴苣 |
| 2 | 莴苣、豆奶、葡萄酒、甜菜 |
| 3 | 豆奶、尿布、葡萄酒、橙汁 |
| 4 | 莴苣、豆奶、尿布、葡萄酒 |
| 5 | 莴苣、豆奶、尿布、橙汁 |
●频繁项集指经常出现在一起的集合,例如订单中的{葡萄酒、豆奶、尿布},或是{豆奶、尿布},根据频繁项集我们可以推测,购买了豆奶的人,很有可能会同时购买尿布,为了度量这种推测的可靠性,引入两个标准,支持度和置信度。
●支持度(Support)
支持度表示item-set在所有的事件N中出现的频率,计算公式为
![]()
例如在上述示例中,{尿布、豆奶}的支持度为3/5=0.6。五条事务中有三条事务包含尿布和豆奶
在实际使用中,通常会设置一个最低支持度(minimum support),将大于或等于最低支持度的X称为频繁的item-set。
●置信度(Confidence)
置信度表示规则 X ⇒ Y 在所有事务中出现的频率。他的含义是满足X的条件下,同时满足Y的事务占所有事务的比例:
![]()
在示例中X ⇒ Y体现在:购买尿布的人中,同时还会购买豆奶
示例中,{尿布、豆奶}的置信度为0.6/0.6=1。
同样使用中我们会设置一个最低置信度,>=最低置信度的规则我们认为是有意义的
三、Apriori原理
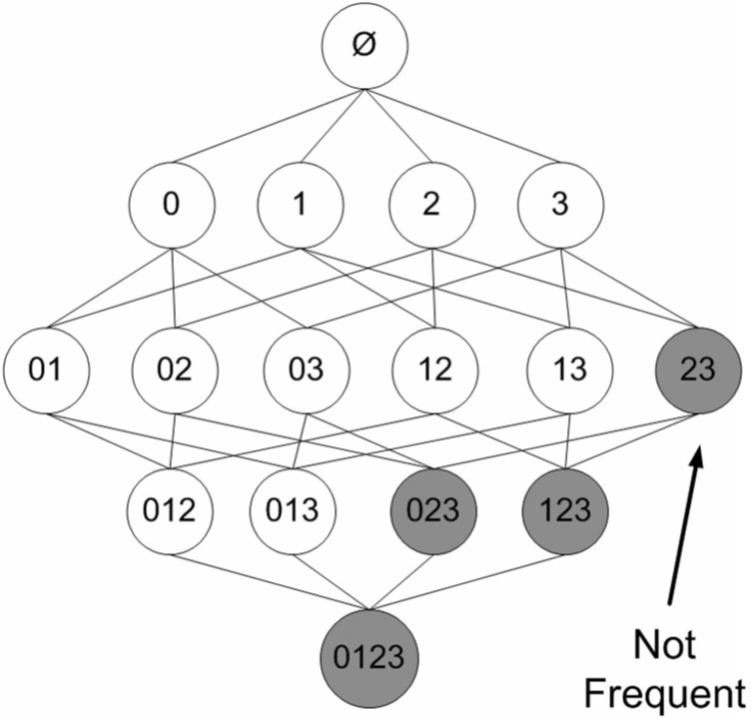
假设一家店有商品1、2、3、4,图中显示了商品所有可能的组合

对于单个项集的支持度,我们可以通过遍历的方式来计算,但是当商品数N过大时,数据集共有
2N−1种项集组合,进行遍历效率不高。
因此基于一种Apriori原理,即说如果某个项集是频繁的,那么它的所有子集也是频繁的,以及他的逆否命题如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
例如在下图中,已知阴影项集{2,3}是非频繁的。由此我们就可以知道项集{0,2,3},{1,2,3}以及{0,1,2,3}也是非频繁的。也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的后,就可以由此排除{0,2,3}、{1,2,3}和{0,1,2,3}。
四、Apriori算法流程
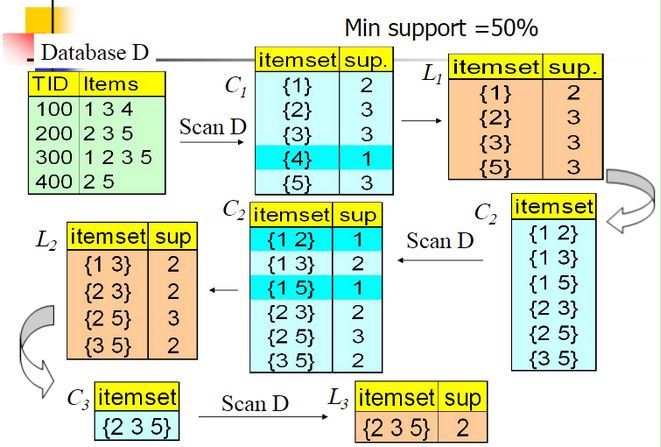
如图,给定订单Database D,Apriori的扫描流程:
1.扫描所有订单的所有商品,生成候选频繁1项集C1,包含所有的五个数据并计算五个数据的支持度。
2.进行剪枝,数据{4}的支持度只有25%被剪掉,得到频繁1项集L1为1235
3.选出只有最后一位不同的集合求并集,连接生成频繁2项集C2,包括12,13,15,23,25,35六组,第一轮迭代结束
4.第二轮迭代,扫描数据集计算C2的支持度,继续剪枝,删除12和15得到频繁2项集L2
5.对L2进行链接,剪枝。。。。。
6.最终得到频繁三项集235
流程总结:
输入:数据集合D,支持度阈值α
输出:最大的频繁K项集
过程:
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
2)挖掘频繁k项集
a) 扫描数据计算候选频繁k项集的支持度
b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。 如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
c) 基于频繁k项集,连接生成候选频繁k+1项集。
3) 令k=k+1,转入步骤2。
Apriori算法Aprior算法每轮迭代都要扫描数据集,因此在数据集很大,数据种类很多的时候,算法效率比较低。