作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
代码详见[]
一、程序
此为该程序的main函数:
def main(argv):
if (len(argv)==1): #执行功能4的直接输入
str0 = input()
str0 = re.sub('[^a-zA-Z]',' ',str0)
redirect(str0)
elif (sys.argv[1]=='-s'):
if(len(argv)==2): #执行功能4文件重定向
str1 = input()
str1 = re.sub('[^a-zA-Z]',' ',str1)
redirect(str1)
else: #执行功能1
file_name1=argv[2]
put_total(file_name1)
put_1to10(file_name1)
elif(str(os.path.exists(sys.argv[1]))=='True'): #执行功能3
get_folder_filename(argv[1])
else: #执行功能2
file_name2=argv[1]+".txt"
put_total_plush(file_name2)
put_1to10(file_name2)
if __name__=="__main__":
main(sys.argv)
功能一
重点难点:1、命令行输入 2、只存取不重复字母且计数 在这里我用的python内置的Counter函数可以很好解决这个问题 3、在使用Counter之前要用正则表达式进行处理,将除字母以外都换成空格。
代码片段:
import sys
import os
import re
import fileinput
import codecs
#超级好用的自带计数器
from collections import Counter
#以字符串形式获取文件中的内容
def get_txt(file_name):
with codecs.open(file_name,'r',encoding='utf-8') as fo:
str1 = fo.read()
str1 = re.sub('[^a-zA-Z]',' ',str1) #通过正则表达式 去除 除字母以外的字符
return str1
#通过Counter返回个字典类型对象
def con(file_name):
txt = get_txt(file_name)
count = Counter(txt.split())
return count
#按出现次数排序(通过调用内置的方法)
def put_1to10(file_name):
dic=con(file_name).most_common(10) #dic列表里面存的是元组
for each in dic:
print(each[0],each[1])
#返回不重复的单词个数(用于功能一)
def put_total(file_name):
print("total:",len(con(file_name)))
功能一执行图:

功能二
重点难点:1、只读取文件名 需要自己加 .txt
代码片段:
#返回包括重复的单词个数
def put_total_plush(file_name):
print("total:",len(list(con(file_name).elements())))
功能二执行图:

功能三
重点难点:1、需要获取文件夹的路径 对路径要加以处理 2、用列表存取文件夹下的文本路径
代码片段:
#用于文件夹功能
def get_folder_filename(folder_name):
current_path = os.path.abspath('.')
current_path = current_path.replace('\\','/') + '/'+ folder_name + '/'
folder_list = []
folder_path = os.listdir(current_path)
for f in folder_path:
folder_list.append(f)
for i in folder_list:
print(i)
for j in folder_list:
print(j)
put_total_plush(current_path+j)
put_1to10(current_path+j)
功能三执行图:
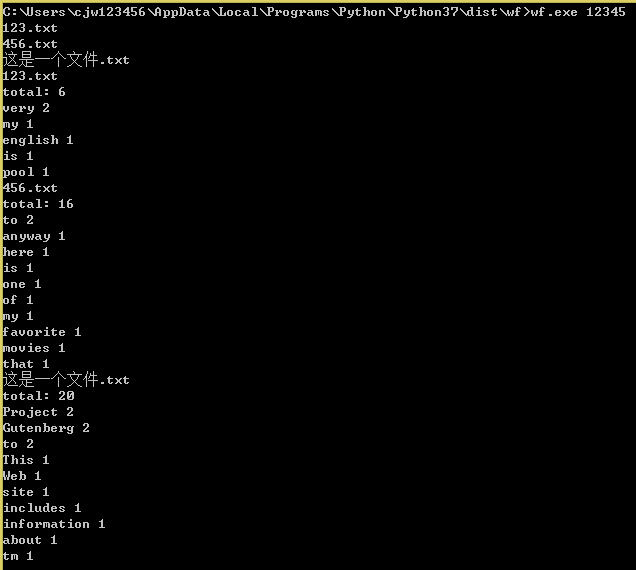
功能四
重点难点:1、重定向传入 用input()接收 2、在main里作判断 如main中代码所示 3、到目前还未实现 将文件全部传入 用fileinput.input()获得对象 进行遍历到 可以实现 但在该代码中,这样做会影响 argv[]的不确定 无法实现main里的判断 个人能力有限经过查询也没找到合适方法。
代码片段:
#用于重定向
def redirect(str1):
count = Counter(str1.split())
print("total:",len(list(count.elements())))
list1 = count.most_common(10)
for each in list1:
print(each[0],each[1])
执行效果图:

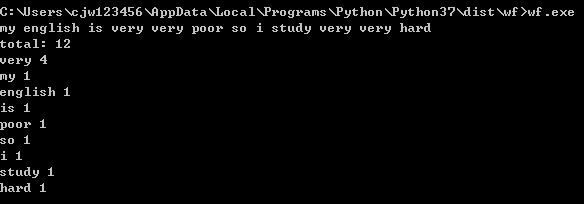
二、PSP
| 类别 | 预计花费时间(min) | 实际花费时间(min) | 分析差距原因 |
| 功能一 | 30 | 50min | 刚开始对题目没有很好的理解,但经过反复试验后找到了很好的可行方式。 |
| 功能二 | 60 | 90min | 在该功能中重新写了输出total的函数 在作业要求里反复查看发现, 除了功能一之外 total均要返回单词总数。 |
| 功能三 | 50 | 120min | 在该功能中不了解获取当前目录以及以下的文件 相对知识欠缺是 费时的最大原因 |
| 功能四 | 60 | 180min | 在该功能中实现通过命令行读取文件中的全部内容比较耗时 |
| 测试/调试 | 100 | 180min | 在各功能实现后发现细节错误很多,初期没有考虑全面。自己写的代码易读性较差,自己修改时 比较费劲。 |
三、总结
经过该程序的锻炼学会了很多东西。学会了怎样通过查资料来解决没遇见过的问题, 本次训练也对以前的知识加以巩固,同时也让自己感到自己编程很菜、思路不清晰、代码自己看着都蒙。相信在通过大量练习之后会有所提高。最后 感觉写博客比编程序更难。