一、代码以及版本控制
项目代码:https://git.coding.net/qiaojingyu/count_words.git
使用git的客户端为: git push
二、重点/难点以及效果截图
1.功能一——小文件输入
(1)将标点符号替换成空格
#对文本的每一行计算词频的函数 def processLine(line,wordCounts): #将标点符号替换成空格 line = replaceLine(line) words = line.split() for word in words: if word in wordCounts: wordCounts[word]+=1 else: wordCounts[word]=1 def replaceLine(line): for ch in '\r .,"' : line = line.replace(ch,' ') return line
(2)读文件,并计算词频。我在这个功能的实现上采用了将单词存入字典,根据空格数计算词频。sort()排序之后,从序列末尾开始输出。
wordCounts={} for line in infile: processLine(line.lower(), wordCounts) pairs = list(wordCounts.items()) #记录总数 print("total : %d\n"% len(pairs)) #列表中的数据对交换位置,数据对排序 items = [[a,b]for (b,a)in pairs] items.sort() #因为sort()函数是从小到大排列,所以range是从最后一项开始取 for i in range(len(items) - 1, -1 , -1): print(items[i][1] + "\t" + str(items[i][0])) data.append(items[i][0]) words.append(items[i][1]) infile.close()
(3)执行效果
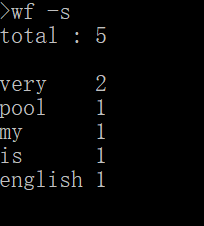
2.功能二——大文件词频统计
(1)相对于功能一,功能二对于筛选单词的条件更多,通过观察对比,需要将以下符号转化为空格进行单词量的计算:“, . ! ? ; " —— ”
...
if lastchar in [",", ".", "!", "?", ";", '"',"——"]: word2 = word1.rstrip(lastchar) word1 = word2 else: word2 = word1 break
...
(2)由于文件过大,我采用的是分块计算,建立两个字典分别计算,最后累加。
#定义文件读取函数,并且输出元素为词频的字典 def readFile(file_name): y = [] with open(file_name, 'r',encoding="utf-8") as f: x=f.readlines() for line in x: y.extend(line.split()) word_list2 = [] # 单词格式化:去掉分词之后部分英文前后附带的标点符号 for word in y: # last character of each word word1 = word # use a list of punctuation marks while True: lastchar = word1[-1:] if lastchar in [",", ".", "!", "?", ";", '"',"-","*"]: word2 = word1.rstrip(lastchar) word1 = word2 else: word2 = word1 break while True: firstchar = word2[0:] if firstchar in [",", ".", "!", "?", ";", '"',"-","*"]: word3 = word2.lstrip(firstchar) word2 = word3 else: word3 = word2 break # build a wordList of lower case modified words word_list2.append(word3) #统计词频 tf = {} for word in word_list2: word = word.lower() # print(word) word = ''.join(word.split()) if word in tf: tf[word] += 1 else: tf[word] = 1 return tf def get_counts(words): tf = {} for word in words: word = word.lower() # print(word) word = ''.join(word.split()) if word in tf: tf[word] += 1 else: tf[word] = 1 #合并两个字典 def merge2(dic1, dic2): from collections import Counter counts = Counter(dic1) + Counter(dic2) return counts
(3)代码效果
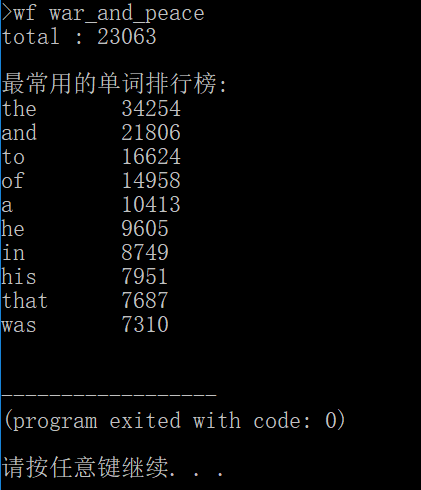
3.功能三——实现文件夹下文件词频统计
(1)提取文件夹中文件类型为.txt的文件。输出文件名,并存入列表。之后循环调用功能二中的函数。
lists = [] for i in os.listdir("..\\count_words"): if os.path.splitext(i)[1] == ".txt": print(i) lists.append(i)
(2)执行效果
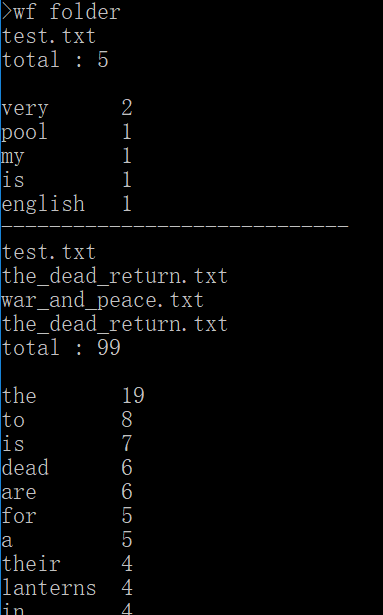
4.功能四——重定向输入输出(未实现)
二、PSP表格
| 预计花费时间 |
实际花费时间 |
花费时间差距 |
原因 |
|
| 功能一 |
60min |
76min |
16min |
对replace()方法运用不熟练,一直在修正”.”也被读成单词的问题 |
| 功能二 |
180min |
339min |
159min |
读大文件的时候,经常是数据不准确,有很多标点字符没有考虑到,不断的从word中查找各种标点字符造成数据不准确的可能性。 |
| 功能三 |
120min |
232min |
112min |
在网上搜索如何读取文件夹中的文件,以及如何循环对文件进行词频统计。 |
| 功能四 |
60min |
107min |
47min |
对于重定向还是不了解,花了很多时间去理解概念以及去完成相应的功能。但是前期进度太慢导致没有完成。 |