教务处爬虫(提交表单模拟登录)
1.尝试分析登陆方式
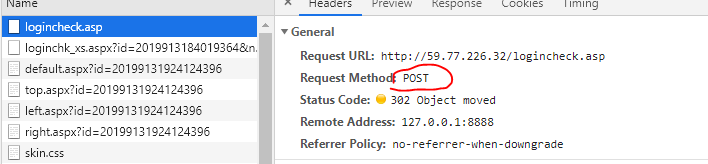
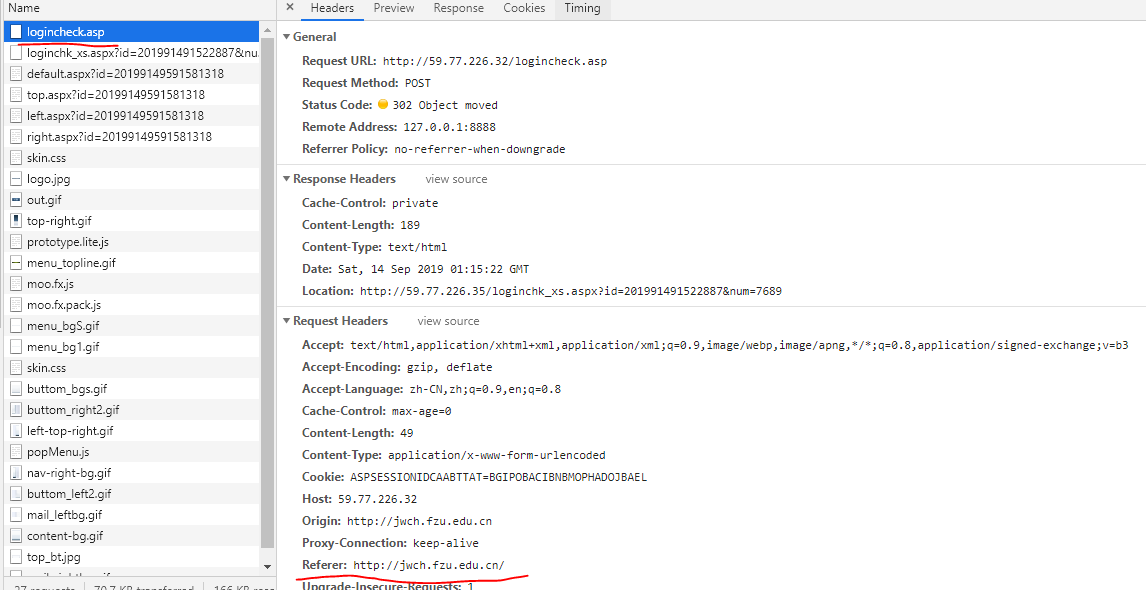
发现教务处是POST,请求表单的方式获得账号密码.
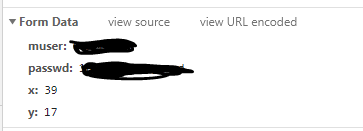
查看表单格式:
Form Data={
muser:学号,(明文显示)
passwd:密码,(明文显示)
x:点击处横坐标,
y:点击处纵坐标
}
x,y这两个数据是这个图中LOGIN按钮上的坐标,你鼠标点击它的时候,坐标会发给服务器.

2.用最简单的requests库实现模拟登录进教务处
首先创建一个会话session,使用post方式发给登录接口('http://59.77.226.32/logincheck.asp')
import requests
headers={
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Origin': 'http//jwch.fzu.edu.cn',
'Proxy-Connection': 'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Referer': 'http://jwch.fzu.edu.cn/',
}
formData = {
'muser': '你的账号',
'passwd': '你的密码',
'x':23,
'y':23,#(x,y)是按钮的确定框的坐标
}
def request():
url = 'http://59.77.226.32/logincheck.asp'
session=requests.session() #创建一个会话
response=session.post(url,headers=headers,data=formData) #post请求提交表单
print(response.status_code)#返回状态码
print(response.text)#返回html文本
if __name__=='__main__':
request()运行结果应如下:
{{图4.PNG(uploading...)}}
对代码观察发现,登陆后的教务处是由多个内嵌页面组成.所以我们继续再会话后面追加请求.我们只要分析出这些内嵌页面的api即可完成.

3.分析内嵌页面的api
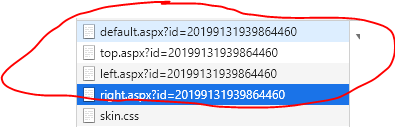
这四个文件aspx文件,就是我们要找的文件,接口地址分别是:
| http://59.77.226.35/default.aspx?id=20199131939864460 |
| http://59.77.226.35/top.aspx?id=20199131939864460 |
| http://59.77.226.35/left.aspx?id=20199131939864460 |
| http://59.77.226.35/right.aspx?id=20199131939864460 |
对着四个地址格式进行分析:
固定地址+文件名.aspx+id
id的值应该是请求时间如2019/9/13/19:39:86:44:60
这个时间的生成是不需要我们操作的,如果我们仔细观察网页源代码,即可发现,模拟登录时,网站已经返回给我们参数了.
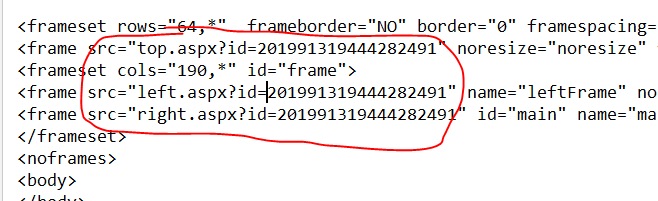
使用正则表示式提取.
4.会话下请求内嵌页面
通过正则表达式提取时间id,然后组装成aspx地址
default: http://59.77.226.35/default.aspx?id=20199149551280317
top: http://59.77.226.35/top.aspx?id=20199149551280317
left: http://59.77.226.35/left.aspx?id=20199149551280317
right: http://59.77.226.35/right.aspx?id=20199149551280317
然后紧接前面的会话下,对上面的四个地址进行get请求,得到返回.
值得注意的一件事是:需要修改headers请求头中的'Referer'值,针对不同地址的Referer属性是不同的

修改后的代码如下:
rootUrl='http://59.77.226.35/'
def request():
url = 'http://59.77.226.32/logincheck.asp'
session=requests.session() #创建一个会话
response=session.post(url,headers=headers,data=formData) #post请求提交表单
html=response.text
#正则提取
top=re.search(r'top\.aspx\?id=\d+',html).group()
num = re.search(r'=\d+',top).group()[1:]
#拼接地址
top=rootUrl+'top.aspx?id='+num
left=rootUrl+'left.aspx?id='+num
right=rootUrl+'right.aspx?id='+num
default=rootUrl+'default.aspx?id='+num
headers_clone = headers #重新搞一个请求头
headers_clone['Referer']=left
#发送get请求
res = session.get(top, headers=headers_clone)
print(res.text)可以获得下面信息
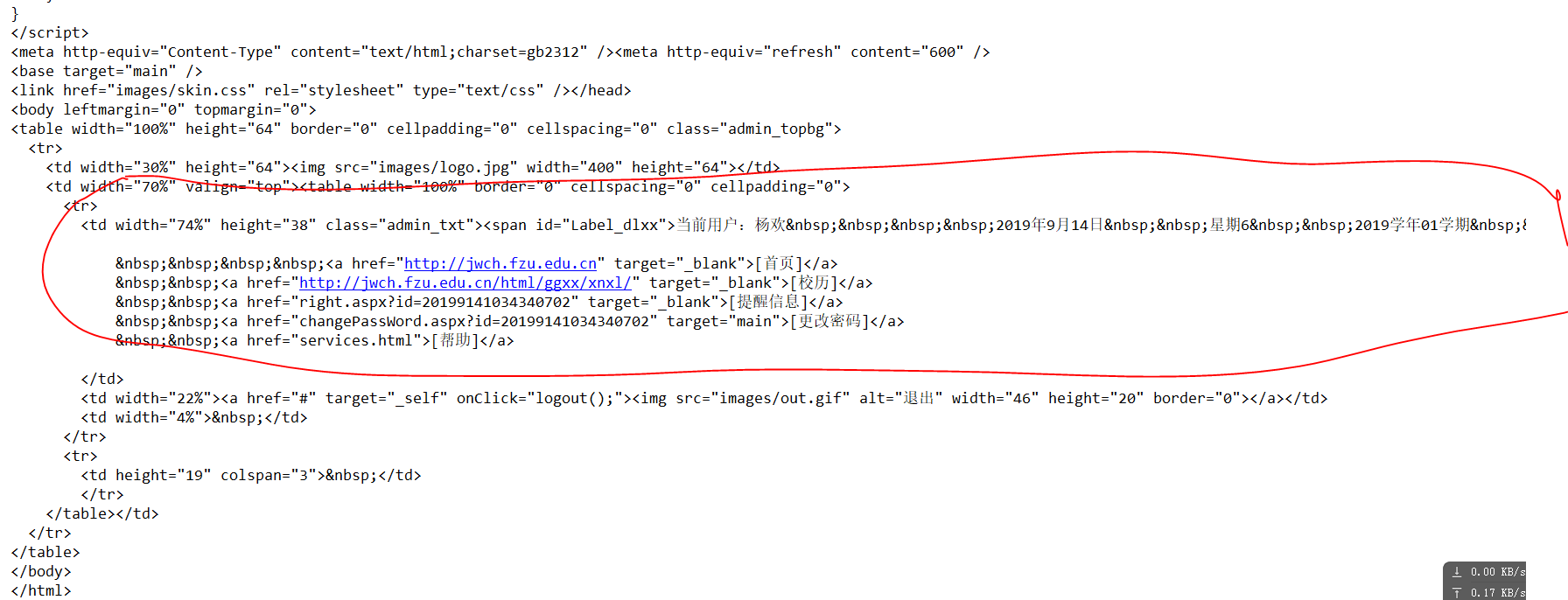
5.拿到更多信息
根据上面的代码,我们可以继续分析其他页面的地址,拿到更多的个人信息
比如拿到个人信息:
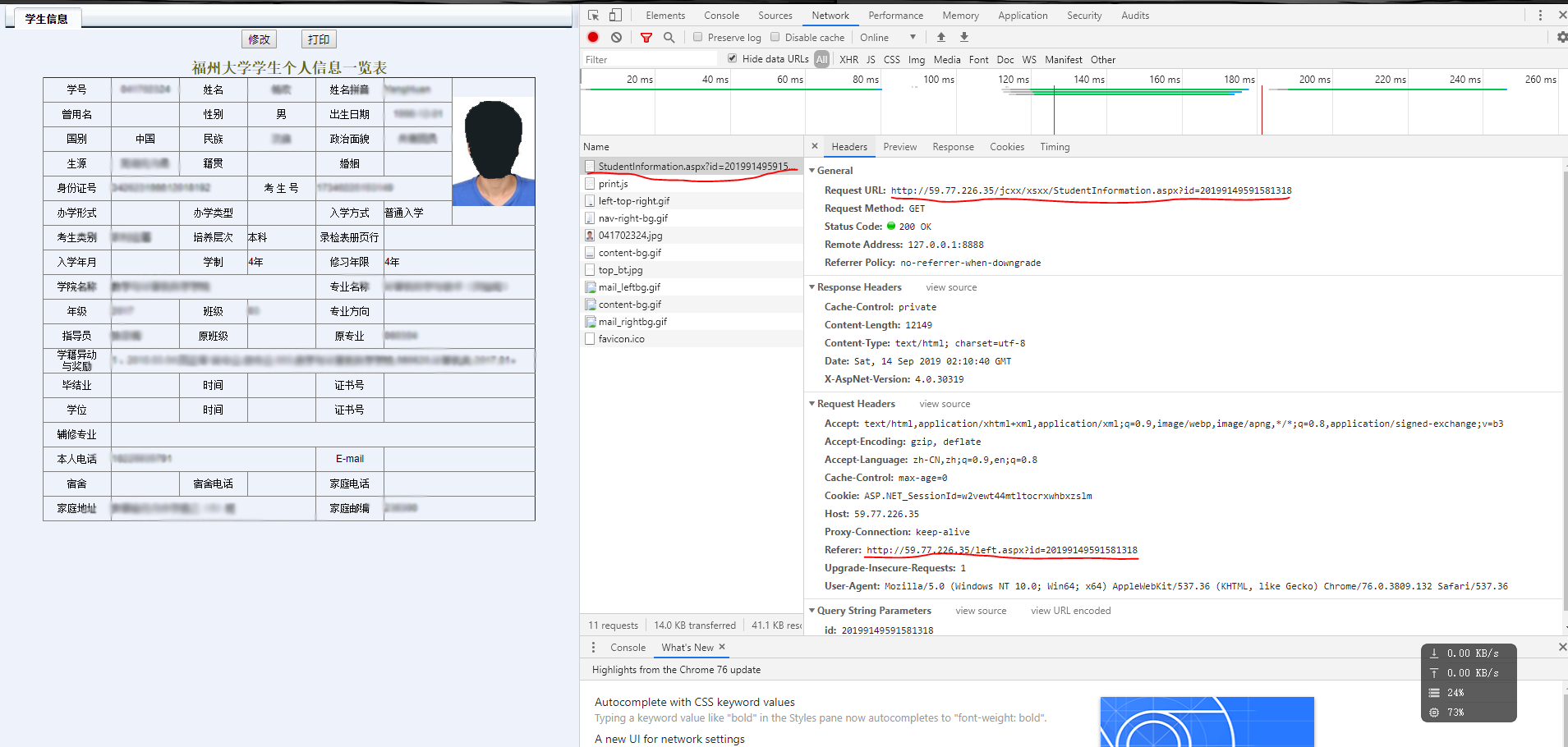
本博客仅用于学习参考.