1.登录和识别验证码过程
我使用的Google浏览器,编译器是PyCharm2017.2.4,首先进入教务处主页,如下所示:
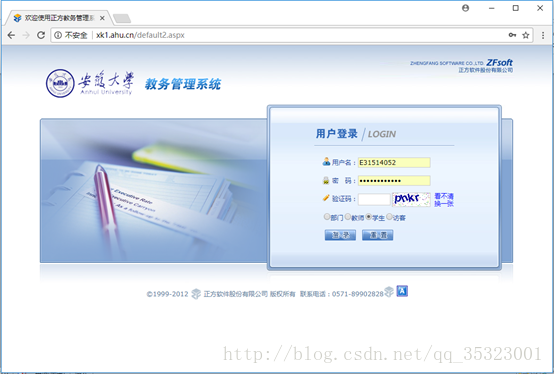
在登陆界面发现需要用户进行填写的选项主要有用户名(学号),密码,验证码以及身份的选择,其中身份默认是学生,那么显然在登录过程中我们所需要做的显然就是填写这些信息来实现登陆的操作。
为了了解这些属性在登陆界面的网页中的情况,我们先使用一次错误的登录请求,使用开发者工具检查网页的状态,如下所示:
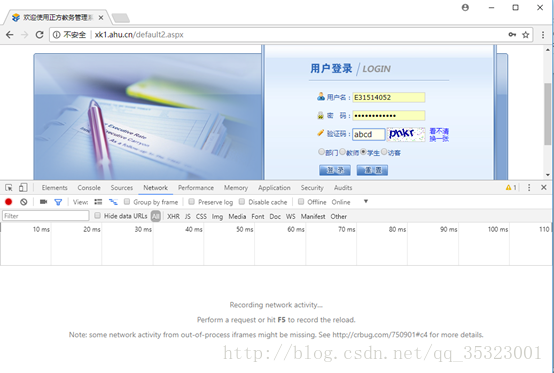
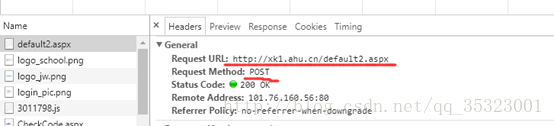
可以看到返回的是验证码不正确的请求,再检查在刚才的登录过程中网络中发送的包,可以找到在名为default2.aspx的请求里面发现了在登录过程中用户输入的信息,诸如用户名、密码、验证码,如下所示:
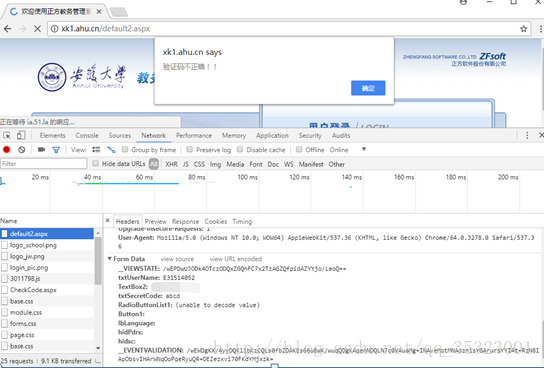
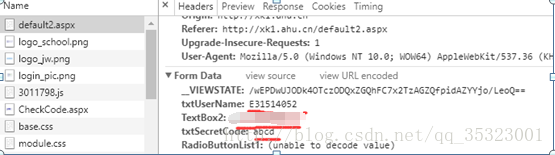
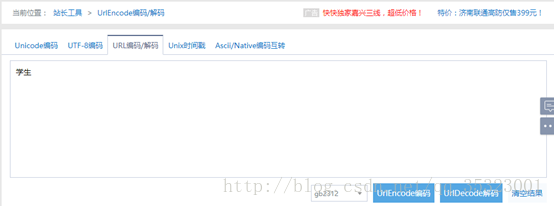
在From Data中还有一个RadioButtonList1属性,但是他后面的值显示的是不能被解码,再检验一下viewsource,发现RadioButtonList1的值为一串编码,值为%D1%A7%C9%FA,如下所示:
放到站长工具[1]里面进行gb2312解码后发现对应的值是学生,如下所示:
此外,还能发现登陆界面发送的请求为post请求,如下所示:
那么构建表单时可以很清楚的知道用户名,密码,以及身份都可以直接写进去,但是验证码是动态变化的,接下来要做的就是如何处理自动识别登陆界面的验证码问题。
Q1:如何找到验证码?
继续在刚刚发送的那些包里面,在default2.aspx下面我们发现了一个名为CheckCode.aspx的请求包,发现他返回的内容没有任何东西,如下所示:
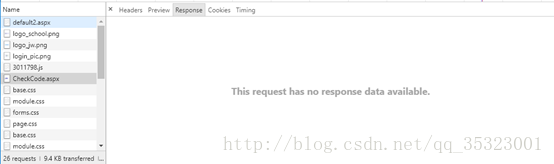
此外,还发现他的请求地址是http://xk1.ahu.cn/CheckCode.aspx,如下所示:
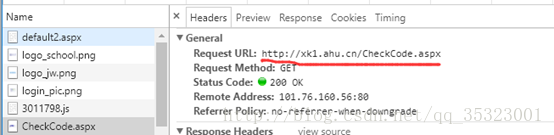
打开这个地址发现那个网页里面全是一个个在教务处网页里面所需要的验证码图片,如下所示:
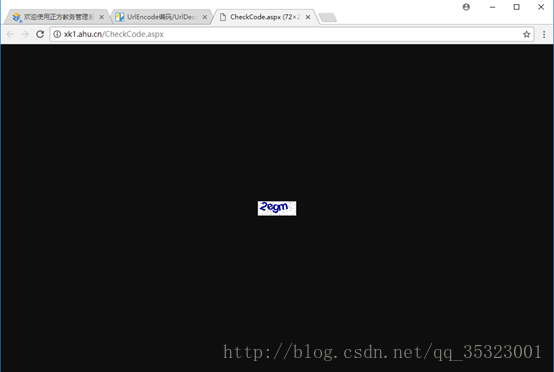
显然我们找到了登陆界面验证码所在的位置,下面的任务就是如何识别验证码图片中的值用来构造post请求表单。
Q2:如何识别验证码?
在处理验证码的这一块,我首先尝试的是调用pytesser3来识别验证码,但是进过测试发现他只能识别那些简单的没有任何偏转的纯数字的验证码,显然不符合教务处网站的验证码。在网上查阅相关资料后,发现百度云平台开放了接口来实现识别验证码[2],用户只需要安装相应的Python SDK,并在需要调用的代码中新建一个OCR的Python SDK客户端AipOcr,就可以直接调用百度云api的接口来识别验证码了,经过几天的测试,发现识别的准确率在8%~11%之间,虽然有待改进但是已经足够爬虫的所需了。
此外,在调用接口之前还需要在个人的百度云[3]控制台中创建APP_ID,用以标识用户,为访问做签名验证,单个用户每天可以调用各个接口的数目共为1700次,(在代码中提供了两套账号,均可使用),如下所示:

到这里,我们登陆所需要的所有的信息都已经准备好了,下面的任务是如何实现登陆。
Q3:如何实现登陆?
为了维护服务器和浏览器之间的关系,选择开启一个session,这样就能保证在登陆过后进入查询成绩页面的过程中cookie信息不变,在登录过程中,先进入验证码界面,将验证码下载到本地,然后调用百度api的接口进行识别,在这里我遇到了第一个问题,直接将图片下载到本地时图片是8位图,而百度api只能识别24位图,所以我又调用了PIL模块来对图片进行处理,转换成所需要的格式来进行识别,然后将获取到的验证码添加到post请求表单中,与用户名,密码,身份等信息一起发送给登陆界面,即可实现登录操作。
2.获取成绩
登陆成功后,进行一系列的操作进入历年成绩界面,如下所示:
第一感觉是这些成绩应该放在网页源代码中,但是在审查了网页的源代码之后发现并没有任何关于成绩的信息,于是便在刚在进入这个界面的过程中发送的包中找到了一个名为xscjcx.aspx?xh=E31514052&xm=%u5218%u78ca&gnmkdm=N121605的请求包中发现了成绩的踪迹,如下所示:
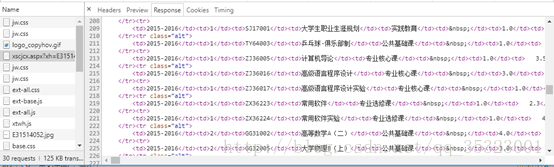
显然我们所需要的成绩放在这里面,检查他的请求和发送的数据如下所示:

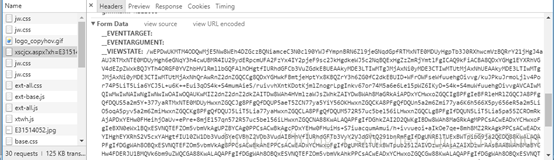
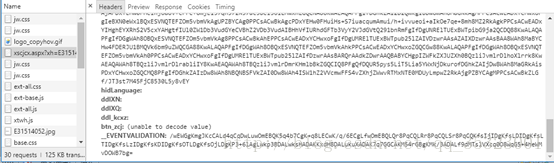
可以找到他发出请求的url以及发送的post请求的表达数据,发现只有三个不为空,分别为__VIEWSTATE,btn_zcj,__EVENTVALIDATION,其中__VIEWSTATE和__EVENTVALIDATION的信息都是明文显示,btn_zcj的信息显示是不能被解码显示的值,检验view source中的信息可以发现btn_zcj的值为一连串的字符,为%C0%FA%C4%EA%B3%C9%BC%A8,如下所示:

经过站长工具gb2312解码后的值是历年成绩,如下所示:
关于__VIEWSTATE和__EVENTVALIDATION的信息,在下面的分析中会有提到,这里不再讨论。
我们用审查网页元素来分析成绩页面的结构,发现刚才在审查网页源代码中找不到的成绩信息可以顺利的找到,如下所示:
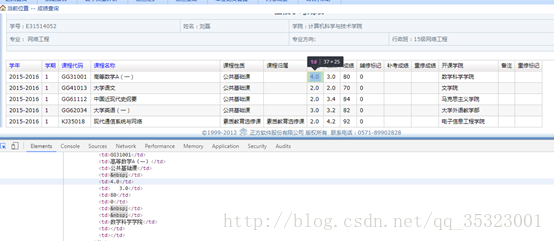
右键发现会弹出查看网页源代码、查看框架源代码等选项,刚刚查看网页源代码中发现并没有找到成绩的相关信息,所以现在选择尝试一下查看框架的源代码,如下所示:
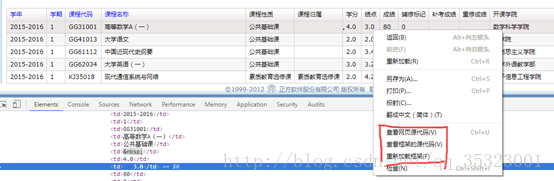
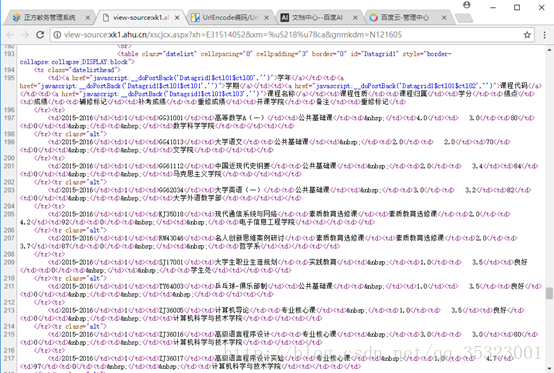
发现在框架的源代码中能够找到成绩的相关信息,此外还可以发现刚刚分析抓包请求的过程中的__VIEWSTATE和__EVENTVALIDATION的信息也可以在框架的源代码中找到,如下所示:
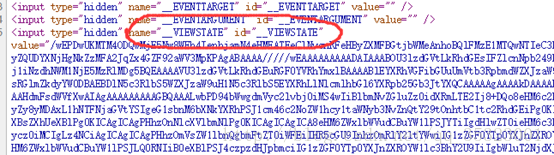
使用Beautifulsoup库可以很容易的提取出这两个数据,与btn_zcj一起构成表单数据post请求给框架的url便可以得到成绩的相关信息,然后用正则便可以提取到成绩的相关信息:

3.发送邮件给用户
用列表保存成绩的信息,每次成功爬取到成绩的信息之后便与前一次成功爬取到的成绩做对比,挑选出新出现的成绩信息,作为邮件内容发送给用户,需要注意的是教务处每次新出来成绩并不一定就排在成绩列表的最后,所以一定要先保存前一次的成绩信息,两次做对比来挑选出新的成绩信息,最后发送给用户,发送邮件的参考链接如[4]所示。
4.兼容性设计
由于以上的开发过程都是根据我本人的账号密码进行设计,为了满足其他人也可以使用我的代码进行爬取教务处的成绩,需要进行一些兼容性的设计,分析查询成绩的url:
http://xk1.ahu.cn/xscjcx.aspx?xh=E31514052&xm=%u5218%u78ca&gnmkdm=N121605
里面的xh=E31514052,后面跟的是用户的学号,为明文显示,可以很简单的替换,xm=%u5218%u78ca,分析后面的%u5218%u78ca,经过gb2312解码后是我的姓名,如下所示:
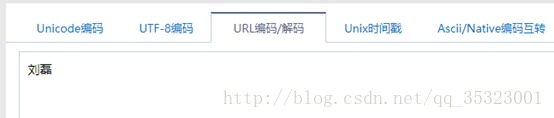
gnmkdm=N121605这一串信息,在测试了我室友的账号之后发现每个人都是一样,没有改变。
综上所述,每个用户在使用我的代码进行爬取教务处成绩的信息时,只需要提供学号、密码、姓名、接收邮件的信箱这四项信息,便可以顺利的运行。
5.测试
需要先安装以下模块,图像处理模块PIL(pip install pillow),百度api模块(pip install baidu-aip),BeautifulSoup模块。
由于每次爬取得过程中都有可能遇到这样或那样的错误,但是我需要的是隔一段时间就要重新爬取一次信息,所以在每一个可能会发生异常的地方都设置了异常处理来保证程序可以一直不停的运行。
在发送邮件部分,可能会出现网络原因或者其他原因导致邮件发送失败,如果不管他成功与否都转到下一次爬取的话,就会由于数据的更新导致用户接收到的课程信息丢失一部分,所以我使用了一个while循环直到邮件发送成功为止。
相关的计算:
每一天供用户调用的百度api接口的次数加起来有1700次,为了避免种种意外情况,每个接口我都少调用5次,所以一共可以利用的次数为1675次,成功率为8%~11%,假设所有成功的次数为150次,每天可能出现新的成绩的时间大约为8:00~22:00,共14个小时,平均一下每个小时成功查询的次数为10.7次,约5min~6min成功查询一次,符合我们的日常需求,每个小时大约爬取120次,30s一次,故每次查询睡眠30s。
运行结果:
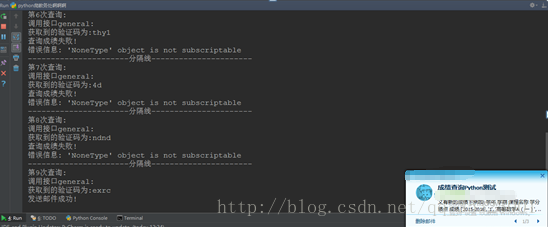
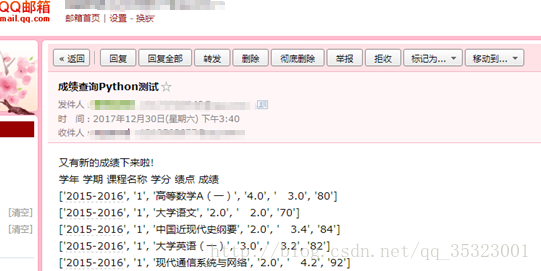
[1]站长工具解码、编码工具链接: http://tool.chinaz.com/tools/urlencode.aspx
[2]百度云识别验证码链接: https://ai.baidu.com/docs#/OCR-Python-SDK/top
[3]百度云链接: https://cloud.baidu.com/
[4]自动发送邮件的参考链接: https://www.cnblogs.com/xshan/p/7954317.html
[5]有关爬取教务处的相关参考资料链接:
http://blog.csdn.net/nghuyong/article/details/51622888
http://blog.csdn.net/zq602316498/article/details/37834103
https://www.cnblogs.com/lovealways/p/7601869.html
源代码:
import urllib.request #url模块中用于打开和读取url
import urllib.parse #url模块中用于解析url
import urllib.error #url模块中用于处理异常
import http.cookiejar #用于处理登录时的Cookie信息
import re #正则模块
from time import sleep#由于是循环爬取,所以设置休眠时间
from PIL import Image #PIL模块,用来处理验证码图片
from aip import AipOcr#百度云中用来识别验证码的模块
import requests #requests模块
from bs4 import BeautifulSoup #bs4模块用来解析爬取下来的网页数据
import smtplib #邮件模块
from email.mime.text import MIMEText #邮件模块
class ScoreCrawl():
def __init__(self, txtUserName = "XXXXXXXXX" , TextBox2="XXXXXXXXX" ,
mailto="XXXXXXXXX", name='XXXXXXXXX', identity='学生',
mailfrom ='XXXXXXXXX', mailpassword='XXXXXXXXX'):
#初始化__init__中的参数分别代表:登录学号,登录密码,用以收邮件的用户邮箱,用户姓名(与教务处的保持一致),
#用户身份(部门/教师/学生/访客),用于发送邮件的qq邮箱,以及该邮箱的授权码
self.txtUserName = txtUserName#用户账号
self.TextBox2 = TextBox2 #登录密码
self.xm1 = name.encode('gbk') #此处是为了得到爬取课表页面时url中所需要的用户姓名的编码,下一行同
self.xm2 = urllib.parse.quote(self.xm1, safe='/:?=')
self.xm3 = list(name.encode('unicode-escape').decode('utf-8'))#此处是为了得到爬取成绩页面
# 时url中所需要的用户姓名的编码,下四行同
for i in range(len(self.xm3)):
if self.xm3[i] == '\\':
self.xm3[i] = '%'
self.xm4 = '%s'*len(self.xm3) % tuple(self.xm3)
self.loginurl = "http://xk1.ahu.cn/default2.aspx" #教务处登陆界面的url
self.imageurl = "http://xk1.ahu.cn/CheckCode.aspx"#验证码界面的url
self.scoreurl = "http://xk1.ahu.cn/xscjcx.aspx?xh="+txtUserName+"&xm="+\
self.xm4+"&gnmkdm=N121605"#成绩界面的url,每一个用户是不一样的,所以我在上面
# 进行了对用户名的不同编码,下一行同
self.cookieJar = http.cookiejar.CookieJar() #处理Cookie信息
self.response = requests.session()#开启一个session,session()会话对象让你能够跨请求
# 保持某些参数。它也会在同一个session实例发出的所有请求之间保持cookie
self.score = [] #用列表保存成绩信息,初始化为空
self.App_ID ='XXXXXXXXX' #百度云参数
self.App_Key ='XXXXXXXXX' #百度云参数
self.SECRET_KEY ='XXXXXXXXX ' #百度云参数
self.aipOcr = AipOcr(self.App_ID, self.App_Key, self.SECRET_KEY) #调用百度包
self.options = { #设置百度包中的general的参数变量
'language_type': 'ENG', #英语
'detect_direction': 'true' #支持方向检测
}
self.RadioButtonList1 = identity.encode('gb2312', 'replace')#解码身份
self.flag = True #一个标记为用来判断有没有成功的将成绩爬取下来
self.mesfrom = mailfrom #发件人的邮箱
self.mespassword = mailpassword#发件人的邮箱密码,用以登陆,其实是一个授权码,通过第三方
# 进行登录以及邮件的发送
self.mesto = mailto #收件人的邮箱
self.startnum = 0 #初始化上一次成功爬取到的成绩的个数
self.oldname = [] #初始化上一次成功爬取到的成绩的课程名称列表,用以查找新出的成绩
self.crawlnum = 0 #初始化已经调用百度api的次数,以此来决定要调用哪个接口
def get_file_content(self, filePath):#读取图片
with open(filePath, 'rb') as f:
return f.read()
def get_img_code(self, filePath):#识别验证码部分,返回验证码字符串
try:
#调用以下文字识别接口,返回读取的图片信息,均为字典类型
if self.crawlnum <= 495:#通用文字识别(含位置信息版)
print('调用接口general:')
result = self.aipOcr.general(
self.get_file_content(filePath), self.options)
elif self.crawlnum <= 990:#通用文字识别
print('调用接口basicGeneral:')
result = self.aipOcr.basicGeneral(
self.get_file_content(filePath), self.options)
elif self.crawlnum <= 1035:#通用文字识别高精度版
print('调用接口basicAccurate:')
result = self.aipOcr.basicAccurate(self.get_file_content(filePath))
elif self.crawlnum <= 1180:#通用文字识别高精度版(含位置信息版)
print('调用接口accurate:')
result = self.aipOcr.accurate(self.get_file_content(filePath))
elif self.crawlnum <= 1675:#网络图片文字文字识别接口
print('调用接口webImage:')
result = self.aipOcr.webImage(
self.get_file_content(filePath), self.options)
#result是调用接口得到的一个字典,以下部分用来提取字典中的验证码字符串
word = result.get('words_result')
res = re.findall('[a-zA-Z0-9]+', word[0].get('words'))[0]
if len(res) > 4: #教务系统所有的验证码都是四位的,若大于四位,则挑选前四位
res = res[0:4]
return res
except Exception as e:#若发生异常,则返回error
res = 'error'
print('获取验证码失败!')
print('错误信息:', e)
return res
def getImagecodeandCookie(self):#得到验证码和Cookie信息
request1 = self.response.get(self.imageurl, stream=True, timeout=100)#获取验证码并下载到本地,
#同时得到Cookie信息
image = request1.content
try:
with open('code.jpg', "wb") as jpg:
jpg.write(image)#将验证码图片保存到本地
im = Image.open('code.jpg')#由于直接保存到本地的图片是8-bit-color,
#不能直接调用接口进行识别,所以要把他转换成24-bit-color
new_im = im.convert("RGB")#将验证码图片转换成24位图片
new_im.save('code1.jpg')#将24位图片保存到本地
self.code = self.get_img_code('code1.jpg')#调用识别验证码的接口识别验证码
print('获取到的验证码为:'+self.code)#打印验证码
except Exception as e:
print('获取验证码图片失败!')#打印提示信息
print('错误信息:', e)
def login(self):#登陆操作
self.getImagecodeandCookie()#获取验证码并保存Cookie信息
# 构建表单数据
postdata = {#此处不能使用urllib.parse.urlencode().encode('utf-8')编码,否则不能成功访问
"__VIEWSTATE": '/wEPDwUJODk4OTczODQxZGQhFC7x2TzAGZQfpidAZYYjo/LeoQ==',
"txtUserName": self.txtUserName,
"TextBox2": self.TextBox2,
"txtSecretCode": self.code,
"RadioButtonList1": self.RadioButtonList1,
"Button1": "",
"lbLanguage": "",
"hidPdrs": "",
"hidsc": "",
"__EVENTVALIDATION": "/wEWDgKX/4yyDQKl1bKzCQLs0fbZDAKEs66uBwK/"
"wuqQDgKAqenNDQLN7c0VAuaMg+INAveMotMNAoznis"
"YGArursYYIAt+RzN8IApObsvIHArWNqOoPqeRyuQR+"
"OEZezxvi70FKdYMjxzk="
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/"
"537.36"
}
try:
#post请求,添加表单信息和头信息进行登录操作
request2 = self.response.post(
self.loginurl, data=postdata, headers=headers, timeout=100)
except Exception as e:#若出现异常,则返回登录失败信息
self.flag = False #若登录失败,则代表此时爬去成绩失败,将flag置为false
print('登录失败!') #打印提示信息
print('错误信息:', e)
def getScore(self): #爬取成绩操作
#构建表单数据
postdata = {#此处表单数据也不能使用urllib.parse.urlencode().encode('utf-8')编码,否则会登陆失败
'btn_zcj': '%C0%FA%C4%EA%B3%C9%BC%A8',#解码出来是历年成绩
"__EVENTTARGET": "",
"__EVENTARGUMENT": "",
"__VIEWSTATE": "",
"hidLanguage": "",
"ddlXN": "",
"ddlXQ": "",
"ddl_kcxz": "",
"__EVENTVALIDATION": ""
}
#构建头部信息
headers = {
"Referer": "http://xk1.ahu.cn/xscjcx.aspx?xh="+self.txtUserName+
"&xm="+self.xm2+"&gnmkdm=N121605",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/"
"537.36",
"Host": "xk1.ahu.cn",
"Origin": "http://xk1.ahu.cn",
"Upgrade-Insecure-Requests": "1"
}
try:
#从框架源代码中提取__EVENTARGUMENT和__VIEWSTATE信息作为post的内容进行下一步
request4 = self.response.get(self.scoreurl,
headers=headers, timeout=100).content.decode('gb2312')
soup = BeautifulSoup(request4, 'lxml')
value1 = soup.find('input', id='__VIEWSTATE')['value']
value2 = soup.find('input', id='__EVENTVALIDATION')['value']
postdata['__VIEWSTATE'] = value1
postdata['__EVENTVALIDATION'] = value2
#将表单数据和头部信息一起post过去
request5 = self.response.post(
self.scoreurl, data=postdata, headers=headers).content.decode('gb2312')
pat1 = '<td>([0-9]{4}-[0-9]{4})</td><td>([0-9]{1})</td><td>([0-9A-Z]{7})' \
'</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>' \
'(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td>' \
'<td>(.*?)</td><td>(.*?)</td><td>(.*?)</td>'
# 使用正则表达式挑选出成绩的信息,返回一个列表
self.res = re.compile(pat1, re.S).findall(request5)
self.scorenum = len(self.res) #记录爬取下来的成绩的条数,与前一次爬取的结果做对比,
for x in range(self.scorenum): #剔除我们不需要的信息
self.res[x] = list(self.res[x])
del self.res[x][2]
del self.res[x][3]
del self.res[x][3]
del self.res[x][6]
del self.res[x][6]
del self.res[x][6]
del self.res[x][6]
del self.res[x][6]
del self.res[x][6]
except Exception as e:
print('查询成绩失败!')
print('错误信息:', e)
self.flag = False #查询失败则将flag置为false
def sendemail(self):
try:
subject = '成绩查询Python测试'
content = '又有新的成绩下来啦!'
content = content+'\n'+'学年 学期 课程名称 学分 绩点 成绩'
#将本次新出现的课程成绩加入到邮件中发送给用户
for sc in range(self.scorenum):
if self.res[sc][2] not in self.oldname:
content = content+'\n'+str(self.res[sc])
content = content+'\n'
mes = MIMEText(content)
mes['Subject'] = subject
mes['From'] = self.mesfrom
mes['To'] = self.mesto
s = smtplib.SMTP_SSL('smtp.qq.com', 465)#邮件服务器及端口号
s.login(self.mesfrom, self.mespassword)
s.sendmail(self.mesfrom, self.mesto, mes.as_string())
print('发送邮件成功!')
return True
except Exception as e:
print('发送邮件失败!')
print('错误信息:', e)
s.quit()
return False
if __name__ == '__main__':
startnum = 0 #初始化已经爬取到的成绩个数,初始化为0个
startname = [] #保存已经爬取到的每门课程的名称
starta = 0 #开始爬去的次数,第1次,第2次,第3次......
crawlnum = 0 #当前正在爬取的次数,与starta相搭配,用以计算成功率的,初始化的时候starta和
# crawlnum的值要保证相等才能正确计算
sus = 0 #成功爬取到的成绩的个数
while True:
print('----------------------分隔线----------------------')
try:
crawlnum = crawlnum+1
print('第'+str(crawlnum)+'次查询:')
scoreCrawl = ScoreCrawl()
scoreCrawl.startnum = startnum
scoreCrawl.oldname = startname
scoreCrawl.crawlnum = crawlnum
scoreCrawl.login()
scoreCrawl.getScore()
if scoreCrawl.flag == True:
sus = sus+1
if scoreCrawl.scorenum > startnum:
startnum = scoreCrawl.scorenum
#while True:#这里控制必须发送成功才退出,因为下一次爬取就会更新数据,
#如果没有成功发送用户收到的信息就会有误
scoreCrawl.sendemail()
#sleep(5)
sleep(20)
else:
startname = startname+[row[2] for row in scoreCrawl.res]
print('没有新的成绩出现!')
sleep(20)
print('查询成功率是:')
print(sus / (crawlnum - starta))
else:
sleep(20)
except Exception as e:
print('访问失败!')
print('错误信息:', e)
sleep(20)