在寒假期间,导师问我能不能自己用爬虫爬进学校教务系统,并且发了一个别人写好的工程,让我研究。但其实,那个代码并不能成功登录我们学校的教务系统,不知道别的学校的时不时的。在那段时间,对于那个项目代码苦苦研究了很久,也没发现什么问题。前几日,突然回想起这件事,就又试着去爬一下,没想到竟然成功了,那么就分享出来,大家一起进步!
首先,观察一下我们要爬取得网站:
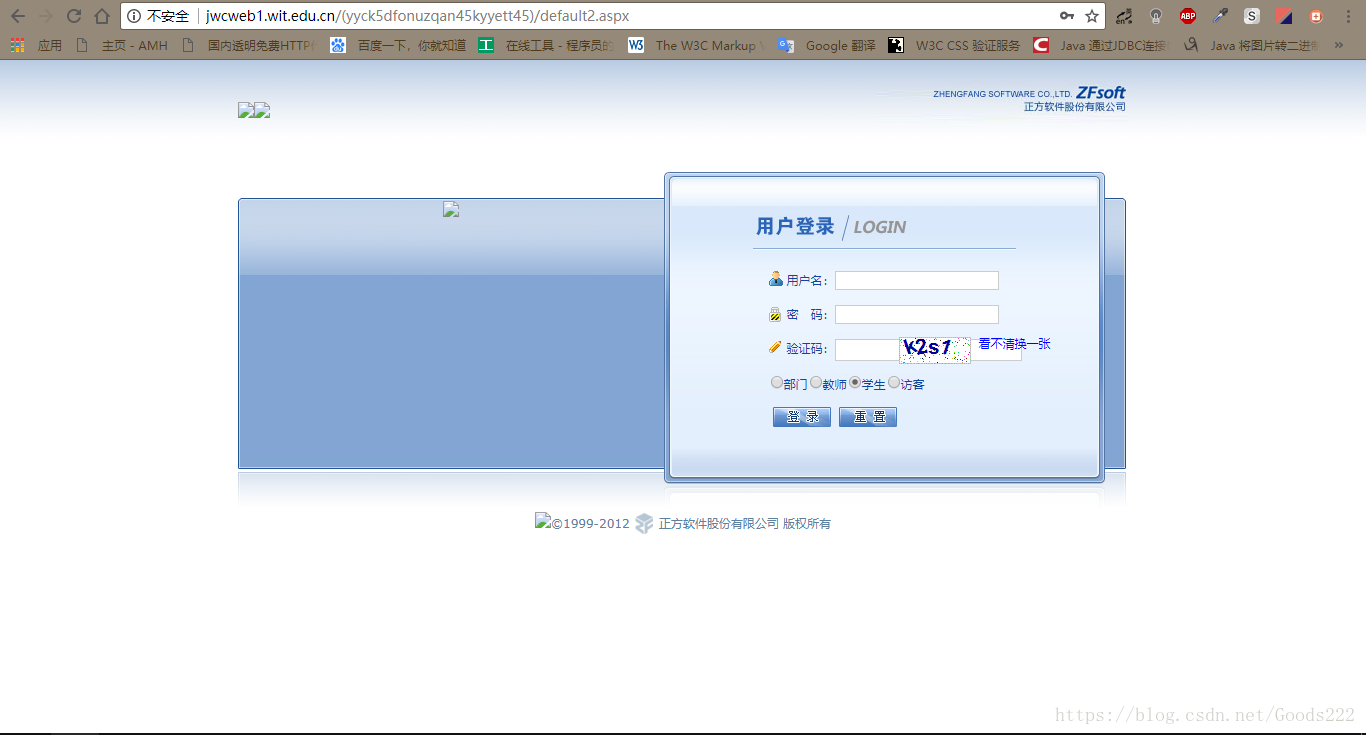
从图中可以看出,我们要爬的网址是jwcweb1.wit.edu.cn,登录页面是default2.aspx。中间加括号的部分,在第一次爬时,我也没注意过,到最后怎么也爬不成功,具体的,我们之后再说。
首先,做一些常规处理,建一个SpiderMain类,用来进行爬虫的主要处理。
class Spider:
def __init__(self):
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",
"Content-Type": "image/Gif; charset=gb2312"
}观察下登录页面的html,

可以看出验证码是从CheckCode.aspx页面获取的。
所以再建一个类,用来储存相关的url。
class URL:
urlStart = "http://jwcweb1.wit.edu.cn/"
urlLogin = "default2.aspx"
urlImage = "CheckCode.aspx"
def __init__(self, session):
self.session = session
self.url = self.urlStart + session + "/" + self.urlLogin
self.ImageUrl = self.urlStart + session + "/" + self.urlImage
def getURL(self):
return self.url
def getImageUrl(self):
return self.ImageUrl再来看看登录界面地址中间带括号的部分,在起初,我并没有去处理它,而是直接加上default2.aspx,没想到怎么爬都是有问题的。仔细想一想,这可能是服务器储存的session的ID。这应该是在首次打开这个界面,服务器自己生成的。之后,我做了个实验,在输入网址时,自己造一个session ID发送过去,让服务器为我们在以此为ID,生产一个session。你可能会问,为什么不在代码中获取此,而是自己造。原因是我试过,这一部分在URL中是隐藏的,并不能获取。好了,让我们再生成一个类,来生成我们自己的session ID。
import random
class RandomSessionID:
sessionID = "("
def __init__(self):
counter = 24
while counter:
number = int(random.random() * 26)
c = chr(number + 97)
self.sessionID += c
counter -= 1
self.sessionID += ')'
def getSessionID(self):
return self.sessionID哈哈,我用的全是小写的,你也可以大写小写数字全部混合,没什么问题。
一切准本就绪,我们来开始我们的操作。
在SpiderMain类中实现一个方法,用来登录。
self.stuID = input("请输入你的学号:")
self.stuPSW = input("请输入你的密码:")
s = requests.Session()
post = s.post(self.addr)
soup = BeautifulSoup(post.content, "html.parser")
print(soup.find("title").string)先获取要登录的学号和密码。再生成一个session,接下来就在这个session进行post和get操作。先post下,让服务器中生成这个session。连接上去后,将title中的内容显示出来,这是我们用来判断是否成功的一个标志。
再成功登录一次,观察下我们发送的data都有些什么内容。
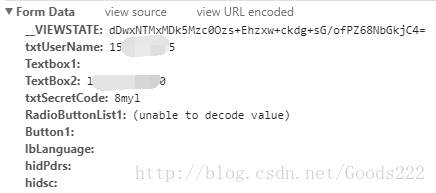
可以看到,发送过去的data内容就是这些。那么,我们再把验证码下载下来,手动输入后,将他们一起发送过去。再一次获取title内容,可以看到,就成功了。
self.code = input("请输入验证码:")
RadioButtonList1 = u"学生".encode('gb2312', 'replace')
data = {
"__VIEWSTATE": self.__VIEWSTATE,
"txtUserName": self.stuID,
"Textbox1": "",
"TextBox2": self.stuPSW,
"txtSecretCode": self.code,
"RadioButtonList1": RadioButtonList1,
"Button1": "",
"lbLanguage": "",
"hidPdrs": "",
"hidsc": ""
}
str = self.addr + self.encodeHeader(**data)
req = s.get(str)
soup = BeautifulSoup(req.content, "html.parser")
print(soup.find("span", id="Label3").string + soup.find("span", id="xhxm").string)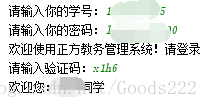
好了,这篇博客主要是记录下我自己这次爬虫的一次教训和经验。如果能帮到你,那我很高兴。代码并没有全部提供,只是为了给一个思路。如果你想研究全部代码,可以在这下载:https://download.csdn.net/download/goods222/10364139