在Scrapy中,引擎和下载器之间有一个组件,叫下载中间件(Downloader Middlewares)。因它是介于Scrapy的request/response处理的钩子,所以有2方面作用:
(1)引擎将请求传递给下载器过程中,下载中间件可以对Requests进行一系列处理。比如设置请求的 User-Agent,设置代理ip等
(2)在下载器完成将Response传递给引擎中,下载中间件可以对Responses进行一系列处理。比如进行gzip解压等。
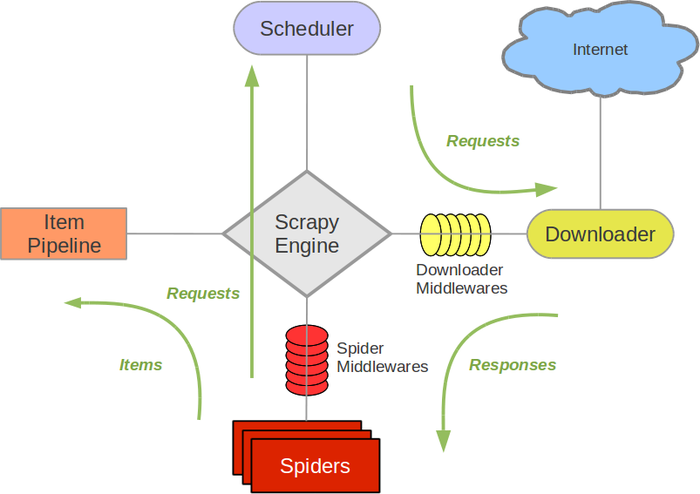
爬虫中,主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理ip。目的在于防止爬取网站的反爬虫策略。
一、UA池:User-Agent池
- 作用:尽可能多的将scrapy工程中的请求伪装成不同类型的浏览器身份。
- 操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的请求头信息中的UA进行篡改伪装
3.在配置文件中开启下载中间件
Middleware.py中部分代码展示:
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware #导包 import random #UA池代码的编写(单独给UA池封装成一个类) class RandomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = random.choice(user_agent_list) request.headers.setdefault('User-Agent',ua) # 当前拦截到请求的ua的写入操作 user_agent_list = [ "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " ]
二、代理池
- 作用:尽可能多的将scrapy工程中的请求的IP设置成不同的。
- 操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件中开启下载中间件
Middleware代码展示:批量对拦截到的请求进行ip更换, 单独封装下载中间件类
class Proxy(object): def process_request(self, request, spider): # 对拦截到请求的url进行判断(协议头到底是http还是https), request.url返回值:http://www.xxx.com h = request.url.split(':')[0] #请求的协议头 if h == 'https': ip = random.choice(PROXY_https) request.meta['proxy'] = 'https://'+ip else: ip = random.choice(PROXY_http) request.meta['proxy'] = 'http://' + ip #可被选用的代理IP PROXY_http = [ '153.180.102.104:80', '195.208.131.189:56055', ] PROXY_https = [ '120.83.49.90:9000', '95.189.112.214:35508', ]
代理ip一般都是在发送请求不成功的时候进行的,所以,我们以后可以将代理ip写到process_exception中。
三、UA池和代理池在中间件中的使用示例
以麦田房产为例,将代码展示在下方,详细展示了如何在Scrapy框架中使用UA池和代理池。
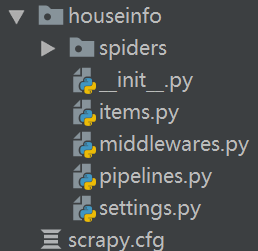
爬虫文件:maitian.py
import scrapy from houseinfo.items import HouseinfoItem # 将item导入 class MaitianSpider(scrapy.Spider): name = 'maitian' # start_urls = ['http://bj.maitian.cn/zfall/PG{}'.format(page for page in range(1,101))] start_urls = ['http://bj.maitian.cn/zfall/PG100'] #解析函数 def parse(self, response): li_list = response.xpath('//div[@class="list_wrap"]/ul/li') for li in li_list: item = HouseinfoItem( title = li.xpath('./div[2]/h1/a/text()').extract_first().strip(), price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip(), square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡',''), area = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('\xa0')[0], adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('\xa0')[2] ) yield item # 提交给管道,然后管道定义存储方式
items文件:items.py
import scrapy class HouseinfoItem(scrapy.Item): title = scrapy.Field() #存储标题,里面可以存储任意类型的数据 price = scrapy.Field() square = scrapy.Field() area = scrapy.Field() adress = scrapy.Field()
管道文件:pipelines.py
class HouseinfoPipeline(object): def __init__(self): self.file = None #开始爬虫时,执行一次 def open_spider(self,spider): self.file = open('maitian.csv','a',encoding='utf-8') # 选用了追加模式 self.file.write(",".join(["标题","月租金","面积","区域","地址","\n"])) print("开始爬虫") # 因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。 def process_item(self, item, spider): content = [item["title"], item["price"], item["square"], item["area"], item["adress"], "\n"] self.file.write(",".join(content)) return item # 结束爬虫时,执行一次 def close_spider(self,spider): self.file.close() print("结束爬虫")
中间件文件Middlewares.py
from scrapy import signals class HouseinfoDownloaderMiddleware(object): #UA池 user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] PROXY_http = [ '153.180.102.104:80', '195.208.131.189:56055', ] PROXY_https = [ '120.83.49.90:9000', '95.189.112.214:35508', ] def process_request(self, request, spider): #使用UA池设置请求的UA request.headers['User-Agent'] = random.choice(self.user_agent_list) return None def process_response(self, request, response, spider): return response #拦截发生异常的请求对象 def process_exception(self, request, exception, spider): if request.url.split(':')[0] == 'http': request.meta['proxy'] = 'http://'+random.choice(self.PROXY_http) else: request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
配置文件:settings.py
# -*- coding: utf-8 -*- BOT_NAME = 'houseinfo' SPIDER_MODULES = ['houseinfo.spiders'] NEWSPIDER_MODULE = 'houseinfo.spiders'
# Obey robots.txt rules ROBOTSTXT_OBEY = False #开启管道 ITEM_PIPELINES = { 'houseinfo.pipelines.HouseinfoPipeline': 300, #数值300表示为优先级,值越小优先级越高 }
#开启下载中间件 DOWNLOADER_MIDDLEWARES = { 'houseinfo.middlewares.HouseinfoDownloaderMiddleware': 543, }