https://blog.csdn.net/u011781521/article/details/70194744?locationNum=4&fps=1
一、手动更新IP池
1.在settings配置文件中新增IP池:
-
IPPOOL=[ -
{"ipaddr":"61.129.70.131:8080"}, -
{"ipaddr":"61.152.81.193:9100"}, -
{"ipaddr":"120.204.85.29:3128"}, -
{"ipaddr":"219.228.126.86:8123"}, -
{"ipaddr":"61.152.81.193:9100"}, -
{"ipaddr":"218.82.33.225:53853"}, -
{"ipaddr":"223.167.190.17:42789"} -
]
这些IP可以从这个几个网站获取:快代理、代理66、有代理、西刺代理、guobanjia。如果出现像下面这种提示:"由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败"或者是这种," 由 于目标计算机积极拒绝,无法连接。". 那就是IP的问题,更换就行了。。。。发现上面好多IP都不能用。。
-
2017-04-16 12:38:11 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://news.sina.com.cn/> (failed 1 times): TCP connection timed out: 10060: 由于连接方在 一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。. -
this is ip:182.241.58.70:51660 -
2017-04-16 12:38:32 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://news.sina.com.cn/> (failed 2 times): TCP connection timed out: 10060: 由于连接方在 一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。. -
this is ip:49.75.59.243:28549 -
2017-04-16 12:38:33 [scrapy.crawler] INFO: Received SIGINT, shutting down gracefully. Send again to force -
2017-04-16 12:38:33 [scrapy.core.engine] INFO: Closing spider (shutdown) -
2017-04-16 12:38:50 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) -
2017-04-16 12:38:53 [scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET http://news.sina.com.cn/> (failed 3 times): TCP connection timed out: 10060: 由于 连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。. -
2017-04-16 12:38:54 [scrapy.core.scraper] ERROR: Error downloading <GET http://news.sina.com.cn/> -
Traceback (most recent call last): -
File "f:\software\python36\lib\site-packages\twisted\internet\defer.py", line 1299, in _inlineCallbacks -
result = result.throwExceptionIntoGenerator(g) -
File "f:\software\python36\lib\site-packages\twisted\python\failure.py", line 393, in throwExceptionIntoGenerator -
return g.throw(self.type, self.value, self.tb) -
File "f:\software\python36\lib\site-packages\scrapy\core\downloader\middleware.py", line 43, in process_request -
defer.returnValue((yield download_func(request=request,spider=spider))) -
twisted.internet.error.TCPTimedOutError: TCP connection timed out: 10060: 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。.
在Scrapy中与代理服务器设置相关的下载中间件是HttpProxyMiddleware,对应的类为:
scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware
2.修改中间件文件middlewares.py
-
# -*- coding: utf-8 -*- -
# Define here the models for your spider middleware -
# -
# See documentation in: -
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html -
import random -
from scrapy import signals -
from myproxies.settings import IPPOOL -
class MyproxiesSpiderMiddleware(object): -
def __init__(self,ip=''): -
self.ip=ip -
def process_request(self, request, spider): -
thisip=random.choice(IPPOOL) -
print("this is ip:"+thisip["ipaddr"]) -
request.meta["proxy"]="http://"+thisip["ipaddr"]
3.在settings中设置DOWNLOADER_MIDDLEWARES
-
DOWNLOADER_MIDDLEWARES = { -
# 'myproxies.middlewares.MyCustomDownloaderMiddleware': 543, -
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':543, -
'myproxies.middlewares.MyproxiesSpiderMiddleware':125 -
}
4.爬虫文件为
-
# -*- coding: utf-8 -*- -
import scrapy -
class ProxieSpider(scrapy.Spider): -
def __init__(self): -
self.headers = { -
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', -
'Accept-Encoding':'gzip, deflate', -
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36' -
} -
name = "proxie" -
allowed_domains = ["sina.com.cn"] -
start_urls = ['http://news.sina.com.cn/'] -
def parse(self, response): -
print(response.body)
5.运行爬虫
scrapy crawl proxie
输出结果为:
-
G:\Scrapy_work\myproxies>scrapy crawl proxie -
2017-04-16 12:23:14 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myproxies) -
2017-04-16 12:23:14 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myproxies', 'NEWSPIDER_MODULE': 'myproxies.spiders', 'SPIDER_MODULES': ['myproxies.spiders']} -
2017-04-16 12:23:14 [scrapy.middleware] INFO: Enabled extensions: -
['scrapy.extensions.corestats.CoreStats', -
'scrapy.extensions.telnet.TelnetConsole', -
'scrapy.extensions.logstats.LogStats'] -
2017-04-16 12:23:14 [py.warnings] WARNING: f:\software\python36\lib\site-packages\scrapy\utils\deprecate.py:156: ScrapyDeprecationWarning: `scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware` class is deprecated, use `scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware` instead -
ScrapyDeprecationWarning) -
2017-04-16 12:23:14 [scrapy.middleware] INFO: Enabled downloader middlewares: -
['myproxies.middlewares.MyproxiesSpiderMiddleware', -
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', -
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', -
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', -
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', -
'scrapy.downloadermiddlewares.retry.RetryMiddleware', -
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', -
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', -
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', -
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', -
'scrapy.downloadermiddlewares.stats.DownloaderStats'] -
2017-04-16 12:23:14 [scrapy.middleware] INFO: Enabled spider middlewares: -
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', -
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', -
'scrapy.spidermiddlewares.referer.RefererMiddleware', -
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', -
'scrapy.spidermiddlewares.depth.DepthMiddleware'] -
2017-04-16 12:23:14 [scrapy.middleware] INFO: Enabled item pipelines: -
[] -
2017-04-16 12:23:14 [scrapy.core.engine] INFO: Spider opened -
2017-04-16 12:23:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) -
2017-04-16 12:23:14 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 -
this is ip:222.92.111.234:1080 -
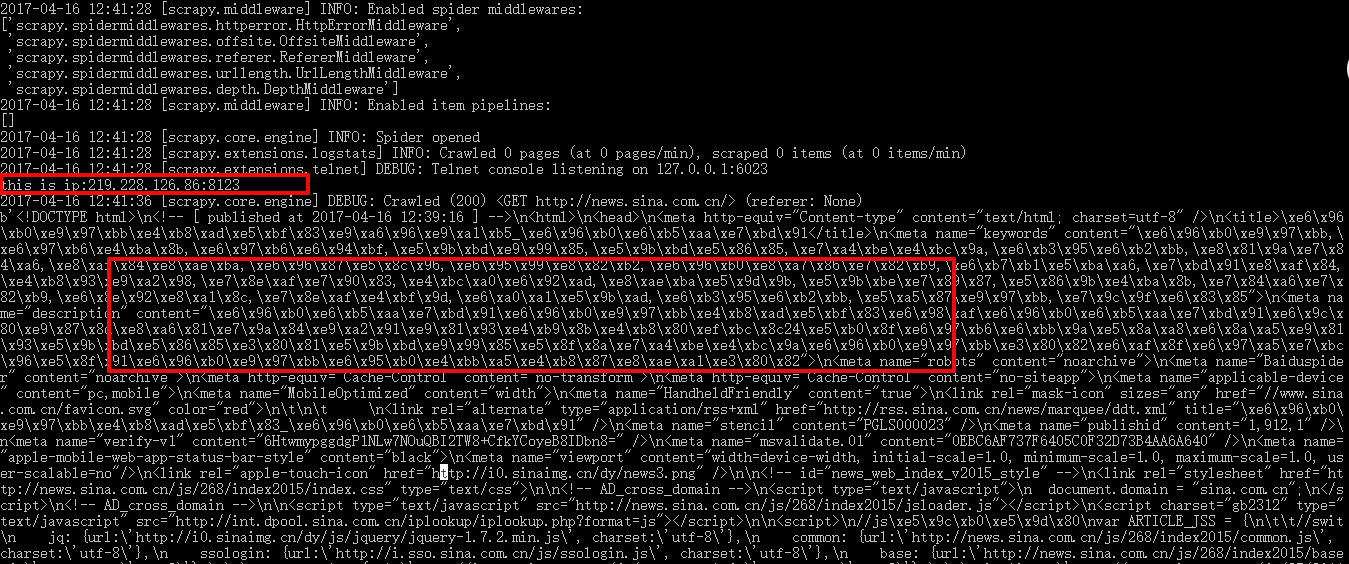
2017-04-16 12:23:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://news.sina.com.cn/> (referer: None) -
b'<html>\n<head>\n<meta http-equiv="Pragma" content="no-cache">\n<meta http-equiv="Expires" content="-1">\n<meta http-equiv="Cache-Control" content="no-cache">\n<link rel="SHORTCUT ICON" href="/favicon.ico">\n\n<title>Login</title>\n<script language="JavaScript">\n\nvar base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";\nvar base64DecodeChars = new Array(\n -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,\n -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,\n -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,\n 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,\n -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,\n 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,\n -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,\n 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);\n\nfunction base64encode(str) {\n var out, i, len;\n var c1, c2, c3;\n\n len = str.length;\n i = 0;\n out = "";\n while(i < len) {\n\tc1 = str.charCodeAt(i++) & 0xff;\n\tif(i == len)\n\t{\n\t out += base64EncodeChars.charAt(c1 >> 2);\n\t out += base64EncodeChars.charAt((c1 & 0x3) << 4);\n\t out += "==";\n\t break;\n\t}\n\tc2 = str.charCodeAt(i++);\n\tif(i == len)\n\t{\n\t out += base64EncodeChars.charAt(c1 >> 2);\n\t out += base64EncodeChars.charAt(((c1 & 0x3)<< 4) | ((c2 & 0xF0) >> 4));\n\t out += base64EncodeChars.charAt((c2 & 0xF) << 2);\n\t out += "=";\n\t break;\n\t}\n\tc3 = str.charCodeAt(i++);\n\tout += base64EncodeChars.charAt(c1 >> 2);\n\tout += base64EncodeChars.charAt(((c1 & 0x3)<< 4) | ((c2 & 0xF0) >> 4));\n\tout += base64EncodeChars.charAt(((c2 & 0xF) << 2) | ((c3 & 0xC0) >>6));\n\tout += base64EncodeChars.charAt(c3 & 0x3F);\n }\n return out;\n}\n\nfunction base64decode(str) {\n var c1, c2, c3, c4;\n var i, len, out;\n\n len = str.length;\n i = 0;\n out = "";\n while(i < len) {\n\t/* c1 */\n\tdo {\n\t c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff];\n\t} while(i < len && c1 == -1);\n\tif(c1 == -1)\n\t break;\n\n\t/* c2 */\n\tdo {\n\t c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff];\n\t} while(i < len && c2 == -1);\n\tif(c2 == -1)\n\t break;\n\n\tout += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4));\n\n\t/* c3 */\n\tdo {\n\t c3 = str.charCodeAt(i++) & 0xff;\n\t if(c3 == 61)\n\t\treturn out;\n\t c3 = base64DecodeChars[c3];\n\t} while(i < len && c3 == -1);\n\tif(c3 == -1)\n\t break;\n\n\tout += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2));\n\n\t/* c4 */\n\tdo {\n\t c4 = str.charCodeAt(i++) & 0xff;\n\t if(c4 == 61)\n\t\treturn out;\n\t c4 = base64DecodeChars[c4];\n\t} while(i < len && c4 == -1);\n\tif(c4 == -1)\n\t break;\n\tout += String.fromCharCode(((c3 & 0x03) << 6) | c4);\n }\n return out;\n}\n \t \n\n\n/*\nif (window.opener) {\n\twindow.opener.location.href = document.location.href;\n\tself.close();\n}\t\n*/\n\nif (top.location != document.location) top.location.href = document.location.href;\n\nvar is_DOM = (document.getElementById)? true : false;\nvar is_NS4 = (document.layers && !is_DOM)? true : false;\n\nvar sAgent = navigator.userAgent;\nvar bIsIE = (sAgent.indexOf("MSIE") > -1)? true : false;\nvar bIsNS = (is_NS4 || (sAgent.indexOf("Netscape") > -1))? true : false;\nvar bIsMoz5 = ((sAgent.indexOf("Mozilla/5") > -1) && !bIsIE)? true : false;\n\nif (is_NS4 || bIsMoz5)\t{\n document.writeln("<style type=\\"text/css\\">");\n document.writeln(".spacer { background-image : url(\\"/images/tansparent.gif\\"); background-repeat : repeat; }");\n document.writeln(".operadummy {}");\n document.writeln("</style>");\n}else if (is_DOM) {\n document.writeln("<style type=\\"text/css\\">");\n document.writeln("body {");\n document.writeln("\tfont-family: \\"Verdana\\", \\"Arial\\", \\"Helvetica\\", \\"sans-serif\\";");\n //document.writeln("\tfont-size: x-small;");\n document.writeln("\tbackground-color : #FFFFFF;");\n document.writeln("\tbackground-image: URL(\\"/images/logon.gif\\");");\n document.writeln("\tbackground-repeat: no-repeat;");\n\tdocument.writeln("\tbackground-position: center;");\n document.writeln("}");\n document.writeln(".spacer {}");\n document.writeln(".operadummy {}");\n document.writeln("</style>");\n//} else if (document.all) {\n// document.write(\'<link rel="stylesheet" href="ie4.css" type="text/css">\');\n}\n\t \nfunction stripSpace(x)\n{\n\treturn x.replace(/^\\W+/,"");\n}\n\nfunction toggleDisplay(style2)\n{\n\tif (style2.display == "block") {\n\t\tstyle2.display = "none";\n\t\tstyle2.visibility = "hidden";\n\t} else {\n\t\tstyle2.display = "block";\n\t\tstyle2.visibility = "";\n\t}\n}\n\nfunction toggleLayer(whichLayer)\n{\n\tif (document.getElementById)\n\t{\n\t\t// this is the way the standards work\n\t\tvar style2 = document.getElementById(whichLayer).style;\n\t\ttoggleDisplay(style2);\n\t}\n\telse if (document.all)\n\t{\n\t\t// this is the way old msie versions work\n\t\tvar style2 = document.all[whichLayer].style;\n//\t\tstyle2.display = style2.display? "":"block";\n\t\ttoggleDisplay(style2);\n\t}\n\telse if (document.layers)\n\t{\n\t\t// this is the way nn4 works\n\t\tvar style2 = document.layers[whichLayer].style;\n//\t\tstyle2.display = style2.display? "":"block";\n\t\ttoggleDisplay(style2);\n\t}\n}\n\nvar today = new Date();\nvar expires = new Date(today.getTime() + (365 * 24 * 60 * 60 * 1000));\nvar timer = null; \nvar nlen = 0;\n\t\t\t\nfunction Set_Cookie(name,value,expires,path,domain,secure) \n{\n document.cookie = name + "=" +escape(value) +\n ( (expires) ? ";expires=" + expires.toGMTString() : "") +\n ( (path) ? ";path=" + path : "") + \n ( (domain) ? ";domain=" + domain : "") +\n ( (secure) ? ";secure" : "");\n}\n\nSet_Cookie("has_cookie", "1", expires);\nvar has_cookie = Get_Cookie("has_cookie") == null ? false : true; \n\t\nfunction Get_Cookie(name)\n{\n var start = document.cookie.indexOf(name+"=");\n var len = start+name.length+1;\n if ((!start) && (name != document.cookie.substring(0,name.length))) return null;\n if (start == -1) return null;\n var end = document.cookie.indexOf(";",len);\n if (end == -1) end = document.cookie.length;\n return unescape(document.cookie.substring(len,end));\n}\n \n \t\t\t\t\nfunction save_cookies() \n{\n\tvar fm = document.forms[0];\n\t\n\tcookie_name = "mingzi";\n if (has_cookie && fm.save_username_info.checked) {\n Set_Cookie(cookie_name, fm.un.value, expires);\n\t} else if (Get_Cookie(cookie_name)) {\n\t\tdocument.cookie = cookie_name + "=" +\n\t\t\t\t\t\t "; expires=Thu, 01-Jan-70 00:00:01 GMT";\n\t}\n \n\tcookie_name = "kouling";\n if (has_cookie && fm.save_username_info.checked) {\n Set_Cookie(cookie_name, fm.pw.value, expires);\n\t} else if (Get_Cookie(cookie_name)) {\n\t\tdocument.cookie = cookie_name + "=" +\n\t\t\t\t\t\t "; expires=Thu, 01-Jan-70 00:00:01 GMT";\n\t}\n}\n\nvar admin_pw = null;\nfunction get_cookies() \n{\n\tvar fm = document.forms[0];\n admin_id = Get_Cookie("mingzi");\t\n if (admin_id != null) {\n fm.admin_id.value = base64decode(admin_id);\n fm.save_username_info.checked = true;\n }\n admin_pw = Get_Cookie("kouling");\n if (admin_pw != null) {\n fm.admin_pw.value = base64decode(admin_pw);\n fm.save_username_info.checked = true;\n nlen = fm.admin_pw.value.toString().length;\n\t\tstar = "***********************************";\n\t\tfm.admin_pw.value += star.substring(0, 31 - nlen);\n } else {\n\t\tfm.admin_pw.value = "";\n\t}\n fm.pw.value = fm.admin_pw.value;\n\tfm.admin_id.select();\n\tfm.admin_id.focus();\n}\n\nfunction checkPassword()\n{\n var fm = document.forms[0];\n if (fm.admin_pw.value != fm.pw.value) {\n\t nlen = fm.admin_pw.value.toString().length;\n\t if (nlen>31) nlen = 31;\n }\n}\t \n\n\nfunction acceptCheckIt(ok)\n{\n\tif (!eval(ok)) {\n top.location.href = "/index.html";\n\t\treturn;\n\t}\n\tvar fm = document.forms[0];\n\tvar d = new Date();\n\tfm.time.value = d.getTime().toString().substring(4,13);\n\tname = fm.admin_id.value; //stripSpace(fm.admin_id.value);\n\tpass = fm.admin_pw.value; //stripSpace(fm.admin_pw.value);\n\tif ( (name.length > 0) \n\t\t&& (pass.length > 0)\n\t ) { \n\t\t\t fm.un.value=base64encode(name);\n\t\t\t if (pass != fm.pw.value) { // password changed\n\t\t\t\t fm.pw.value=base64encode(pass);\n\t\t\t } else {\n\t\t\t\t fm.pw.value=base64encode(pass.substring(0,nlen));\n\t\t\t }\n\t\t\t save_cookies();\n\t\t\t fm.admin_id.value="";\n\t\t\t fm.admin_pw.value="";\n\t\t\t fm.submit();\n\t }\n}\n\nfunction checkIt() \n{\n \n\t\tacceptCheckIt(true);\n \n} \n \t\nfunction cancelIt() \n{\n return false;\n}\t\t\n\n \nfunction auto_submit() \n{\n var fm = document.forms[0];\n get_cookies();\n fm.admin_id.select();//focus(); \n\n return checkIt();\n}\t\n\t\nfunction testSelect()\n{\n\tdocument.forms[0].admin_pw.select();\n}\t\n\n\nfunction write_one_check_box(txt)\n{\n if (has_cookie) {\n\t document.writeln("<tr align=\'center\' valign=\'middle\'>");\n\t document.writeln("<td align=\'center\' colspan=\'2\' style=\'color:white;font-size:10pt;\'>");\n\t document.writeln("<in"+"put name=\'"+txt+"\' type=\'checkbox\' tabindex=\'3\'>");\n\t document.writeln("Remember my name and password</td></tr>");\n }\n} \n \n\t\nfunction reloadNow()\n{\n document.location = document.location;\n}\n\nvar margin_top = 0; \nif (document.layers || bIsMoz5) {\n\tmargin_top = (window.innerHeight - 330) / 2;\n\tif (margin_top < 0) margin_top = 0;\n\t\n\twindow.onResize = reloadNow;\n} \n\t\n</script> \n</head>\n\n<body bgcolor="White" link="Black" onLoad="get_cookies();">\n\n<noscript>\n<h1>This WebUI administration tool requires scripting support.</h1>\n<h2>Please obtain the latest version of browsers which support the Javascript language or\nenable scripting by changing the browser setting \nif you are using the latest version of the browsers.\n</h2>\n</noscript>\t\n \n<div id="div1" style="display:block">\n<FORM method="POST" name="login" autocomplete="off" ACTION="/index.html"> \n<script language="javascript">\n\tif (bIsMoz5 && (margin_top > 0)) {\n\t\tdocument.writeln("<table width=\'100%\' border=\'0\' cellspacing=\'0\' cellpadding=\'0\' style=\'margin-top: " + margin_top + "px;\'>");\n\t} else {\n\t\tdocument.writeln("<table width=\'100%\' height=\'100%\' border=\'0\' cellspacing=\'0\' cellpadding=\'0\'>");\n\t}\n</script>\n\n<tr align="center" valign="middle" style="width: 471px; height: 330px;">\n<td align="center" valign="middle" scope="row">\n\n\t<script language="javascript">\n\tif (is_NS4 || bIsMoz5) {\n\t\tdocument.writeln("<table background=\'/images/logon.gif\' width=\'471\' height=\'330\' border=\'0\' cellpadding=\'0\' cellspacing=\'0\'>");\n\t} else {\n\t\tdocument.writeln("<table border=\'0\' cellpadding=\'0\' cellspacing=\'0\'>");\n\t}\n\t</script>\n \n\t<tr align="center" valign="middle">\n\t<script language="javascript">\n\t\tdocument.writeln("<td width=\'100%\' align=\'center\' valign=\'middle\'>");\n\t</script>\n\n \t\t<table bgcolor=\'\' background=\'\' border=\'0\'>\n\t\t<tr align="center" valign="middle">\n\t\t\t<th align="right" style="color:white;font-size:10pt;">Admin Name: </th>\n\t\t\t<td align="left" style="color:white;font-size:10pt;"><INPUT type=text name="admin_id" tabindex="1" SIZE="21" MAXLENGTH="31" VALUE="">\n\t\t\t</td>\n\t\t</tr>\n\t\t<tr align="center" valign="middle">\n\t\t\t<th align="right" style="color:white;font-size:10pt;">Password: </th>\n\t\t\t<td align="left" style="color:white;font-size:10pt;"><INPUT type="password" name="admin_pw" tabindex="2" onFocus="testSelect();" onChange="checkPassword();" SIZE="21" MAXLENGTH="31" VALUE=""> \n\t\t\t</td>\n\t\t</tr>\n\t\t\n\t\t<script language="javascript">\n\t\t\twrite_one_check_box("save_username_info");\n\t\t</script>\t\n\t\t\n\t\t<tr align="center" valign="middle">\n\t\t\t<td> </td>\n\t\t\t<td align="left">\n\t\t\t<INPUT type="button" value=" Login " onClick="checkIt();" tabindex=\\ "4\\">\n\t\t\t</td>\n\t\t</tr>\n\t\t\n\t\t</table>\n\t\t\n\t</td>\n\n\t</tr>\n\t</table>\n\n</td>\n</tr>\n</table>\n<INPUT type="hidden" name="time" VALUE="0">\n<INPUT type="hidden" name="un" VALUE="">\n<INPUT type="hidden" name="pw" VALUE="">\n</FORM>\n</div>\n\n<div id="div2" style="display:none">\n<pre>\n \n</pre>\n<bar />\n<center>\n<FORM name="additional">\n\t<INPUT type="button" value="Accept" onclick="acceptCheckIt(true);">\n\t \n\t<INPUT type="button" value="Decline" onclick="acceptCheckIt(false);">\n</FORM>\n\n</center>\n</div>\n\n</body>\n</html>\n\n\n' -
2017-04-16 12:23:15 [scrapy.core.engine] INFO: Closing spider (finished) -
2017-04-16 12:23:15 [scrapy.statscollectors] INFO: Dumping Scrapy stats: -
{'downloader/request_bytes': 214, -
'downloader/request_count': 1, -
'downloader/request_method_count/GET': 1, -
'downloader/response_bytes': 12111, -
'downloader/response_count': 1, -
'downloader/response_status_count/200': 1, -
'finish_reason': 'finished', -
'finish_time': datetime.datetime(2017, 4, 16, 4, 23, 15, 198955), -
'log_count/DEBUG': 2, -
'log_count/INFO': 7, -
'log_count/WARNING': 1, -
'response_received_count': 1, -
'scheduler/dequeued': 1, -
'scheduler/dequeued/memory': 1, -
'scheduler/enqueued': 1, -
'scheduler/enqueued/memory': 1, -
'start_time': datetime.datetime(2017, 4, 16, 4, 23, 14, 706603)} -
2017-04-16 12:23:15 [scrapy.core.engine] INFO: Spider closed (finished) -
G:\Scrapy_work\myproxies>
示例:http://download.csdn.net/detail/u011781521/9815663
二、自动更新IP池
这里写个自动获取IP的类proxies.py,执行一下把获取的IP保存到txt文件中去:
-
# *-* coding:utf-8 *-* -
import requests -
from bs4 import BeautifulSoup -
import lxml -
from multiprocessing import Process, Queue -
import random -
import json -
import time -
import requests -
class Proxies(object): -
"""docstring for Proxies""" -
def __init__(self, page=3): -
self.proxies = [] -
self.verify_pro = [] -
self.page = page -
self.headers = { -
'Accept': '*/*', -
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36', -
'Accept-Encoding': 'gzip, deflate, sdch', -
'Accept-Language': 'zh-CN,zh;q=0.8' -
} -
self.get_proxies() -
self.get_proxies_nn() -
def get_proxies(self): -
page = random.randint(1,10) -
page_stop = page + self.page -
while page < page_stop: -
url = 'http://www.xicidaili.com/nt/%d' % page -
html = requests.get(url, headers=self.headers).content -
soup = BeautifulSoup(html, 'lxml') -
ip_list = soup.find(id='ip_list') -
for odd in ip_list.find_all(class_='odd'): -
protocol = odd.find_all('td')[5].get_text().lower()+'://' -
self.proxies.append(protocol + ':'.join([x.get_text() for x in odd.find_all('td')[1:3]])) -
page += 1 -
def get_proxies_nn(self): -
page = random.randint(1,10) -
page_stop = page + self.page -
while page < page_stop: -
url = 'http://www.xicidaili.com/nn/%d' % page -
html = requests.get(url, headers=self.headers).content -
soup = BeautifulSoup(html, 'lxml') -
ip_list = soup.find(id='ip_list') -
for odd in ip_list.find_all(class_='odd'): -
protocol = odd.find_all('td')[5].get_text().lower() + '://' -
self.proxies.append(protocol + ':'.join([x.get_text() for x in odd.find_all('td')[1:3]])) -
page += 1 -
def verify_proxies(self): -
# 没验证的代理 -
old_queue = Queue() -
# 验证后的代理 -
new_queue = Queue() -
print ('verify proxy........') -
works = [] -
for _ in range(15): -
works.append(Process(target=self.verify_one_proxy, args=(old_queue,new_queue))) -
for work in works: -
work.start() -
for proxy in self.proxies: -
old_queue.put(proxy) -
for work in works: -
old_queue.put(0) -
for work in works: -
work.join() -
self.proxies = [] -
while 1: -
try: -
self.proxies.append(new_queue.get(timeout=1)) -
except: -
break -
print ('verify_proxies done!') -
def verify_one_proxy(self, old_queue, new_queue): -
while 1: -
proxy = old_queue.get() -
if proxy == 0:break -
protocol = 'https' if 'https' in proxy else 'http' -
proxies = {protocol: proxy} -
try: -
if requests.get('http://www.baidu.com', proxies=proxies, timeout=2).status_code == 200: -
print ('success %s' % proxy) -
new_queue.put(proxy) -
except: -
print ('fail %s' % proxy) -
if __name__ == '__main__': -
a = Proxies() -
a.verify_proxies() -
print (a.proxies) -
proxie = a.proxies -
with open('proxies.txt', 'a') as f: -
for proxy in proxie: -
f.write(proxy+'\n')
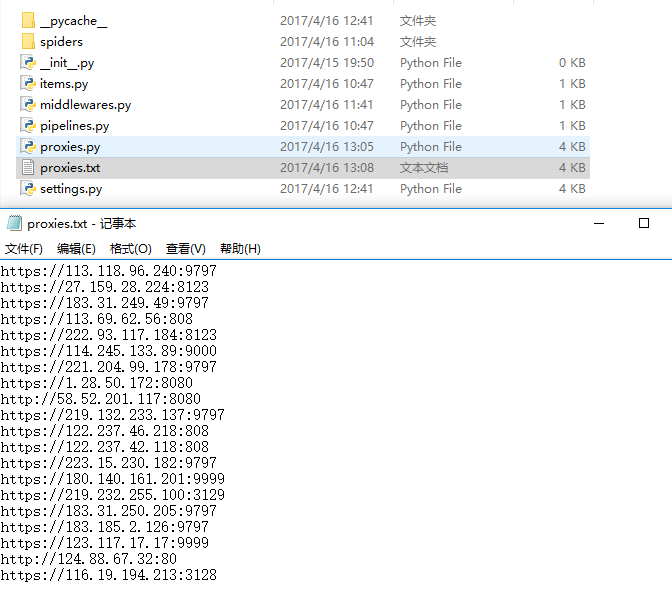
执行一下: python proxies.py

这些IP就会保存到proxies.txt文件中去
修改代理文件middlewares.py的内容为如下:
-
import random -
import scrapy -
from scrapy import log -
# logger = logging.getLogger() -
class ProxyMiddleWare(object): -
"""docstring for ProxyMiddleWare""" -
def process_request(self,request, spider): -
'''对request对象加上proxy''' -
proxy = self.get_random_proxy() -
print("this is request ip:"+proxy) -
request.meta['proxy'] = proxy -
def process_response(self, request, response, spider): -
'''对返回的response处理''' -
# 如果返回的response状态不是200,重新生成当前request对象 -
if response.status != 200: -
proxy = self.get_random_proxy() -
print("this is response ip:"+proxy) -
# 对当前reque加上代理 -
request.meta['proxy'] = proxy -
return request -
return response -
def get_random_proxy(self): -
'''随机从文件中读取proxy''' -
while 1: -
with open('G:\\Scrapy_work\\myproxies\\myproxies\\proxies.txt', 'r') as f: -
proxies = f.readlines() -
if proxies: -
break -
else: -
time.sleep(1) -
proxy = random.choice(proxies).strip() -
return proxy
修改下settings文件
-
DOWNLOADER_MIDDLEWARES = { -
# 'myproxies.middlewares.MyCustomDownloaderMiddleware': 543, -
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':None, -
'myproxies.middlewares.ProxyMiddleWare':125, -
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware':None -
}
运行爬虫:
scrapy crawl proxie
输出结果为:

示例:http://download.csdn.net/detail/u011781521/9815729
三、利用crawlera神器(收费)
Crawlera是Scrapinghub公司提供的一个下载的中间件,其提供了很多服务器和ip,scrapy可以通过Crawlera向目标站点发起请求。
crawlera官方网址:http://scrapinghub.com/crawlera/
crawlera帮助文档:http://doc.scrapinghub.com/crawlera.html
一、crawlera平台注册
首先申明,注册是免费的,使用的话除了一些特殊定制外都是free的。
1、登录其网站 https://dash.scrapinghub.com/account/signup/
填写用户名、密码、邮箱,注册一个crawlera账号并激活


新建一个项目
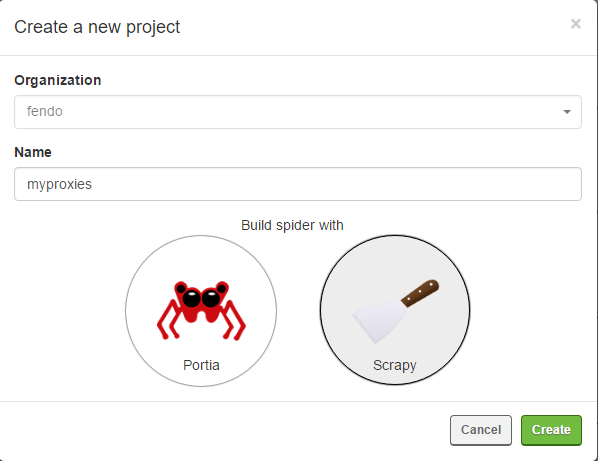
选择Scrapy....
二、部署到srcapy项目
1、安装scarpy-crawlera
pip install scarpy-crawlera
2、修改settings.py
如果你之前设置过代理ip,那么请注释掉,加入crawlera的代理,最重要的是需要在配置文件里,配置开启Crawlera中间件。如下所示:
-
DOWNLOADER_MIDDLEWARES = { -
# 'myproxies.middlewares.MyCustomDownloaderMiddleware': 543, -
# 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':None, -
# 'myproxies.middlewares.ProxyMiddleWare':125, -
# 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware':None -
'scrapy_crawlera.CrawleraMiddleware': 600 -
}
为了是crawlera生效,需要添加你创建的api信息(如果填写了API key的话,pass填空字符串便可)
-
CRAWLERA_ENABLED = True -
CRAWLERA_USER = '<API key>' -
CRAWLERA_PASS = ''
其中CRAWLERA_USER是注册crawlera之后申请到的API Key:

CRAWLERA_PASS则代表crawlera的password,一般默认是不填写的,空白即可。
为了达到更高的抓取效率,可以禁用Autothrottle扩展和增加并发请求的最大数量,以及设置下载超时,代码如下
-
CONCURRENT_REQUESTS = 32 -
CONCURRENT_REQUESTS_PER_DOMAIN = 32 -
AUTOTHROTTLE_ENABLED = False -
DOWNLOAD_TIMEOUT = 600
如果在代码中设置有 DOWNLOAD_DELAY的话,需要在settings.py中添加
CRAWLERA_PRESERVE_DELAY = True
如果你的spider中保留了cookies,那么需要在Headr中添加
-
DEFAULT_REQUEST_HEADERS = { -
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', -
# 'Accept-Language': 'zh-CN,zh;q=0.8', -
'X-Crawlera-Cookies': 'disable' -
}
三、运行爬虫
这些都设置好了过后便可以运行你的爬虫了。这时所有的request都是通过crawlera发出的,信息如下:
-
G:\Scrapy_work\myproxies>scrapy crawl proxie -
2017-04-16 15:49:40 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myproxies) -
2017-04-16 15:49:40 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myproxies', 'NEWSPIDER_MODULE': 'myproxies.spiders', 'SPIDER_MODULES': ['myproxies.spiders']} -
2017-04-16 15:49:40 [scrapy.middleware] INFO: Enabled extensions: -
['scrapy.extensions.corestats.CoreStats', -
'scrapy.extensions.telnet.TelnetConsole', -
'scrapy.extensions.logstats.LogStats'] -
2017-04-16 15:49:40 [scrapy.middleware] INFO: Enabled downloader middlewares: -
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', -
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', -
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', -
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', -
'scrapy.downloadermiddlewares.retry.RetryMiddleware', -
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', -
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', -
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', -
'scrapy_crawlera.CrawleraMiddleware', -
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', -
'scrapy.downloadermiddlewares.stats.DownloaderStats'] -
2017-04-16 15:49:40 [scrapy.middleware] INFO: Enabled spider middlewares: -
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', -
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', -
'scrapy.spidermiddlewares.referer.RefererMiddleware', -
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', -
'scrapy.spidermiddlewares.depth.DepthMiddleware'] -
2017-04-16 15:49:40 [scrapy.middleware] INFO: Enabled item pipelines: -
[] -
2017-04-16 15:49:40 [scrapy.core.engine] INFO: Spider opened -
2017-04-16 15:49:40 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) -
2017-04-16 15:49:40 [root] INFO: Using crawlera at http://proxy.crawlera.com:8010?noconnect (user: f3b8ff0381fc46c7b6834aa85956fc82) -
2017-04-16 15:49:40 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 -
2017-04-16 15:49:41 [scrapy.core.engine] DEBUG: Crawled (407) <GET http://www.655680.com/> (referer: None) -
2017-04-16 15:49:41 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <407 http://www.655680.com/>: HTTP status code is not handled or not allowed -
2017-04-16 15:49:41 [scrapy.core.engine] INFO: Closing spider (finished) -
2017-04-16 15:49:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats: -
{'crawlera/request': 1, -
'crawlera/request/method/GET': 1, -
'crawlera/response': 1, -
'crawlera/response/error': 1, -
'crawlera/response/error/bad_proxy_auth': 1, -
'crawlera/response/status/407': 1, -
'downloader/request_bytes': 285, -
'downloader/request_count': 1, -
'downloader/request_method_count/GET': 1, -
'downloader/response_bytes': 196, -
'downloader/response_count': 1, -
'downloader/response_status_count/407': 1, -
'finish_reason': 'finished', -
'finish_time': datetime.datetime(2017, 4, 16, 7, 49, 41, 546403), -
'log_count/DEBUG': 2, -
'log_count/INFO': 9, -
'response_received_count': 1, -
'scheduler/dequeued': 1, -
'scheduler/dequeued/memory': 1, -
'scheduler/enqueued': 1, -
'scheduler/enqueued/memory': 1, -
'start_time': datetime.datetime(2017, 4, 16, 7, 49, 40, 827892)} -
2017-04-16 15:49:41 [scrapy.core.engine] INFO: Spider closed (finished) -
G:\Scrapy_work\myproxies>
报407错误。。。。看了下文档,407没有说明。。在Google上找到了一种说法是,来自Crawlera的407错误代码是一个身份验证错误,APIKEY中可能会出现打字错误,或者您没有使用正确的错误代码。

然后又在网上找了下,发现自己创建的是Scrapy Cloud项目,而非crawlera,然后去创建crawlera发现要收费。。

收费就算了。。。网上还在以下两种策略: Scrapy+Goagent、Scrapy+Tor(高度匿名的免费代理)没有玩过。。