版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
最近看到好多人问怎么爬取淘宝的评论,可能是由于淘宝的API改了吧,原来的很多人写的教程不能用了,我这里更新一下
第一步——抓包:找到获取评论的请求
浏览器F12——NetWork——刷新——找请求
这里我翻了一下,没有找到,可能是动态加载的
然后我点击了页面上的【累计评论】按钮,也没有发现请求,直到我翻页的时候,终于找到了这个请求
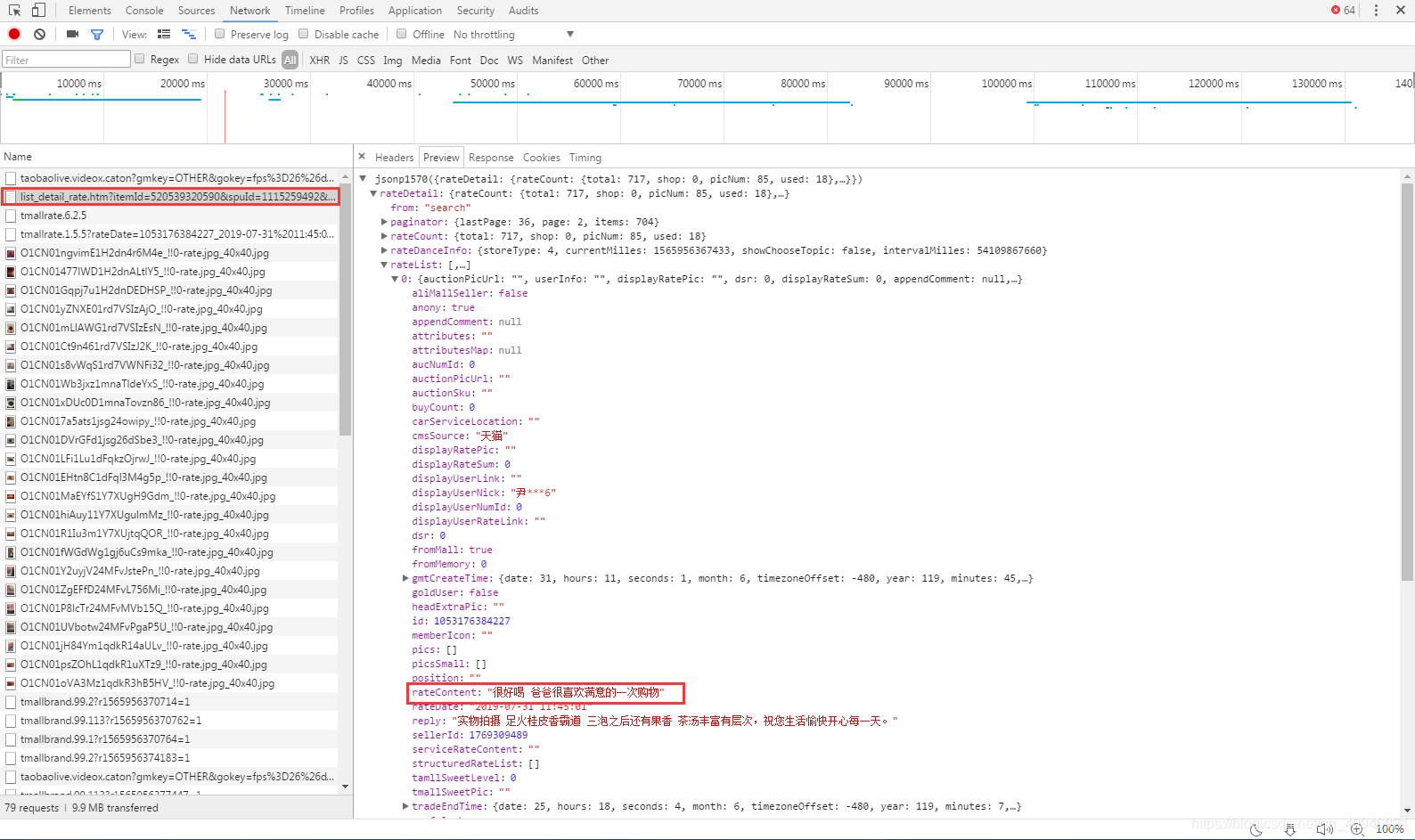
第二步——照猫画虎:模拟这个请求

请求网址: https://rate.tmall.com/list_detail_rate.htm(萌新注意,问号后面可以不加,等下加在另一个地方)
方式:get
Headers:
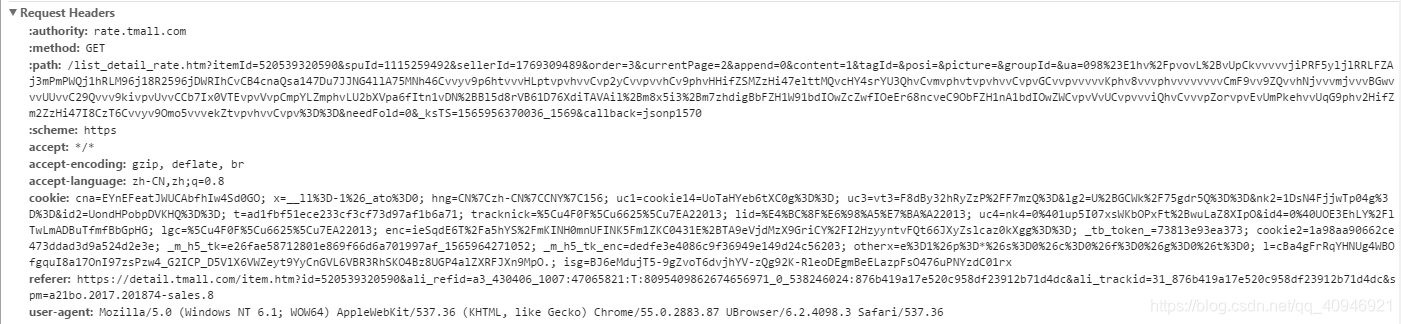
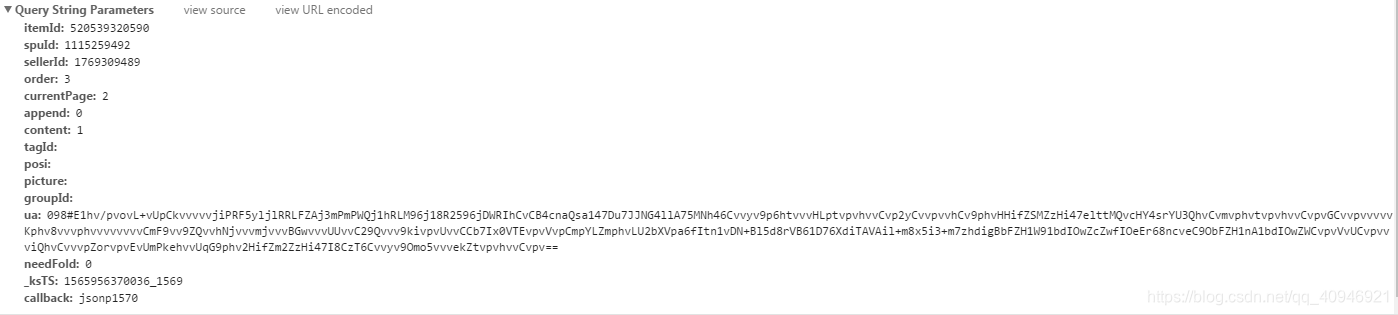
Params:也就是请求网址问号后面的部分
第三步——爬虫开工:码代码
注意:这里我已经去除了无用的参数
import requests
import json
url="https://rate.tmall.com/list_detail_rate.htm"
header={
"cookie":"cna=EYnEFeatJWUCAbfhIw4Sd0GO; x=__ll%3D-1%26_ato%3D0; hng=CN%7Czh-CN%7CCNY%7C156; uc1=cookie14=UoTaHYecARKhrA%3D%3D; uc3=vt3=F8dBy32hRyZzP%2FF7mzQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&nk2=1DsN4FjjwTp04g%3D%3D&id2=UondHPobpDVKHQ%3D%3D; t=ad1fbf51ece233cf3cf73d97af1b6a71; tracknick=%5Cu4F0F%5Cu6625%5Cu7EA22013; lid=%E4%BC%8F%E6%98%A5%E7%BA%A22013; uc4=nk4=0%401up5I07xsWKbOPxFt%2BwuLaZ8XIpO&id4=0%40UOE3EhLY%2FlTwLmADBuTfmfBbGpHG; lgc=%5Cu4F0F%5Cu6625%5Cu7EA22013; enc=ieSqdE6T%2Fa5hYS%2FmKINH0mnUFINK5Fm1ZKC0431E%2BTA9eVjdMzX9GriCY%2FI2HzyyntvFQt66JXyZslcaz0kXgg%3D%3D; _tb_token_=536fb5e55481b; cookie2=157aab0a58189205dd5030a17d89ad52; _m_h5_tk=150df19a222f0e9b600697737515f233_1565931936244; _m_h5_tk_enc=909fba72db21ef8ca51c389f65d5446c; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; l=cBa4gFrRqYHNUtVvBOfiquI8a17O4IJ51sPzw4_G2ICP9B5DeMDOWZezto8kCnGVL6mpR3RhSKO4BYTKIPaTlZXRFJXn9MpO.; isg=BI6ORhr9X6-NrOuY33d_XmZFy2SQp1Ju1qe4XLjXJRHsGyp1IJ9IG0kdUwfSA0oh",
"referer":"https://detail.tmall.com/item.htm",
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36",
}
params={ #必带信息
"itemId":"596285864342", #商品id
"sellerId":"2616970884",
"currentPage":"2", #页码
"callback":"jsonp2359",
}
req=requests.get(url,params,headers=header)
print(req)第四步——处理数据:
在print(req)设置断点,查看req的结构,发现req.contents为bytes数据,所以需要解码
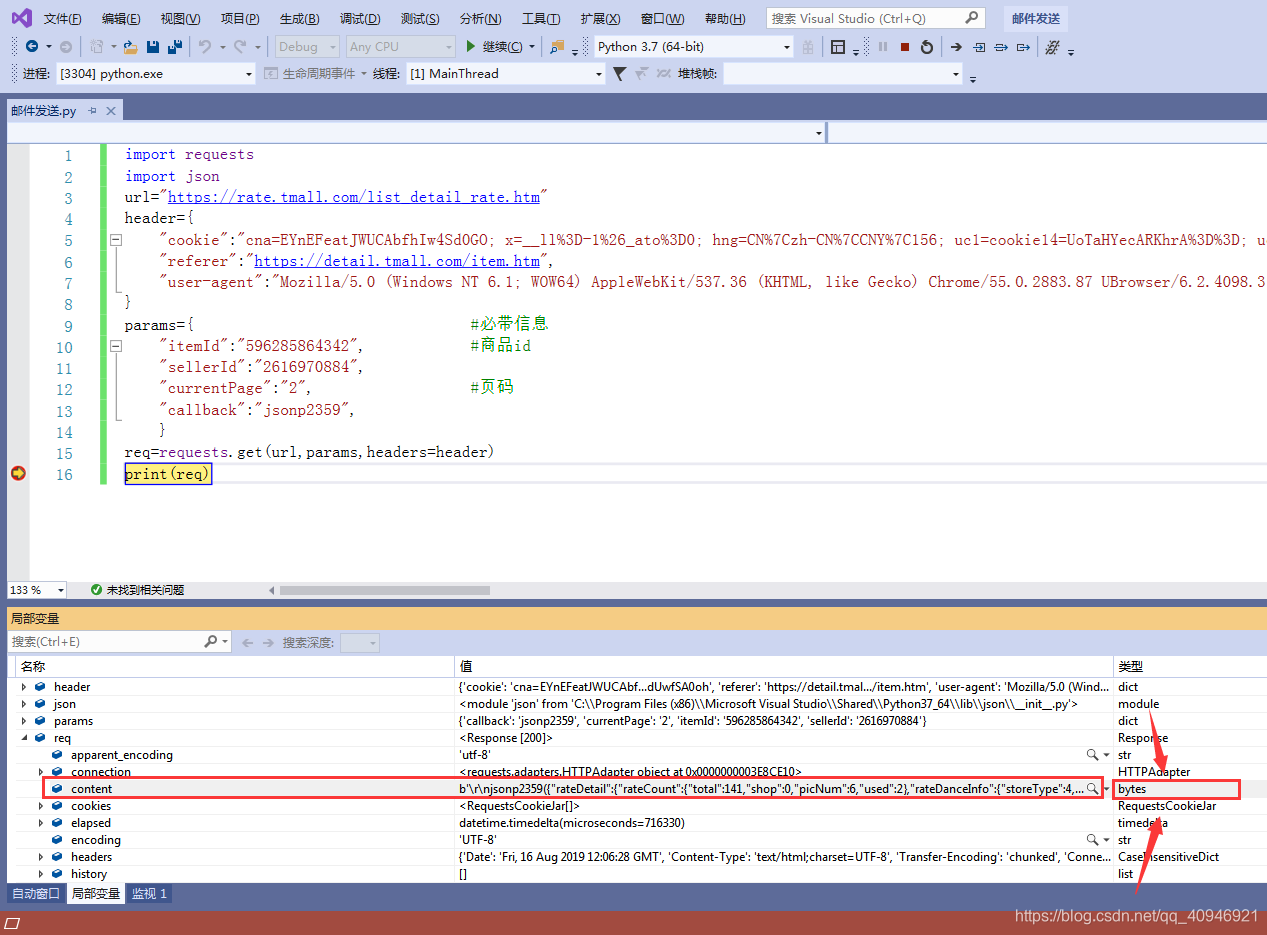
使用utf-8解码后获得的文本外层嵌套了'\r\njson2359()',会导致无法转换为json对象,去除这部分字符,转换为json,就可以得到我们需要的数据,因此修改代码为:
import requests
import json
url="https://rate.tmall.com/list_detail_rate.htm"
header={
"cookie":"cna=EYnEFeatJWUCAbfhIw4Sd0GO; x=__ll%3D-1%26_ato%3D0; hng=CN%7Czh-CN%7CCNY%7C156; uc1=cookie14=UoTaHYecARKhrA%3D%3D; uc3=vt3=F8dBy32hRyZzP%2FF7mzQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&nk2=1DsN4FjjwTp04g%3D%3D&id2=UondHPobpDVKHQ%3D%3D; t=ad1fbf51ece233cf3cf73d97af1b6a71; tracknick=%5Cu4F0F%5Cu6625%5Cu7EA22013; lid=%E4%BC%8F%E6%98%A5%E7%BA%A22013; uc4=nk4=0%401up5I07xsWKbOPxFt%2BwuLaZ8XIpO&id4=0%40UOE3EhLY%2FlTwLmADBuTfmfBbGpHG; lgc=%5Cu4F0F%5Cu6625%5Cu7EA22013; enc=ieSqdE6T%2Fa5hYS%2FmKINH0mnUFINK5Fm1ZKC0431E%2BTA9eVjdMzX9GriCY%2FI2HzyyntvFQt66JXyZslcaz0kXgg%3D%3D; _tb_token_=536fb5e55481b; cookie2=157aab0a58189205dd5030a17d89ad52; _m_h5_tk=150df19a222f0e9b600697737515f233_1565931936244; _m_h5_tk_enc=909fba72db21ef8ca51c389f65d5446c; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; l=cBa4gFrRqYHNUtVvBOfiquI8a17O4IJ51sPzw4_G2ICP9B5DeMDOWZezto8kCnGVL6mpR3RhSKO4BYTKIPaTlZXRFJXn9MpO.; isg=BI6ORhr9X6-NrOuY33d_XmZFy2SQp1Ju1qe4XLjXJRHsGyp1IJ9IG0kdUwfSA0oh",
"referer":"https://detail.tmall.com/item.htm",
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36",
}
params={ #必带信息
"itemId":"596285864342", #商品id
"sellerId":"2616970884",
"currentPage":"2", #页码
"callback":"jsonp2359",
}
req=requests.get(url,params,headers=header).content.decode('utf-8')[12:-1]; #解码,并且去除str中影响json转换的字符(\n\rjsonp(...));
result=json.loads(req);
print(result)运行效果
第五步——筛选有用信息
由于我们获得的是json数据,可以直接索引获取有用信息,增加断点,看监视窗口
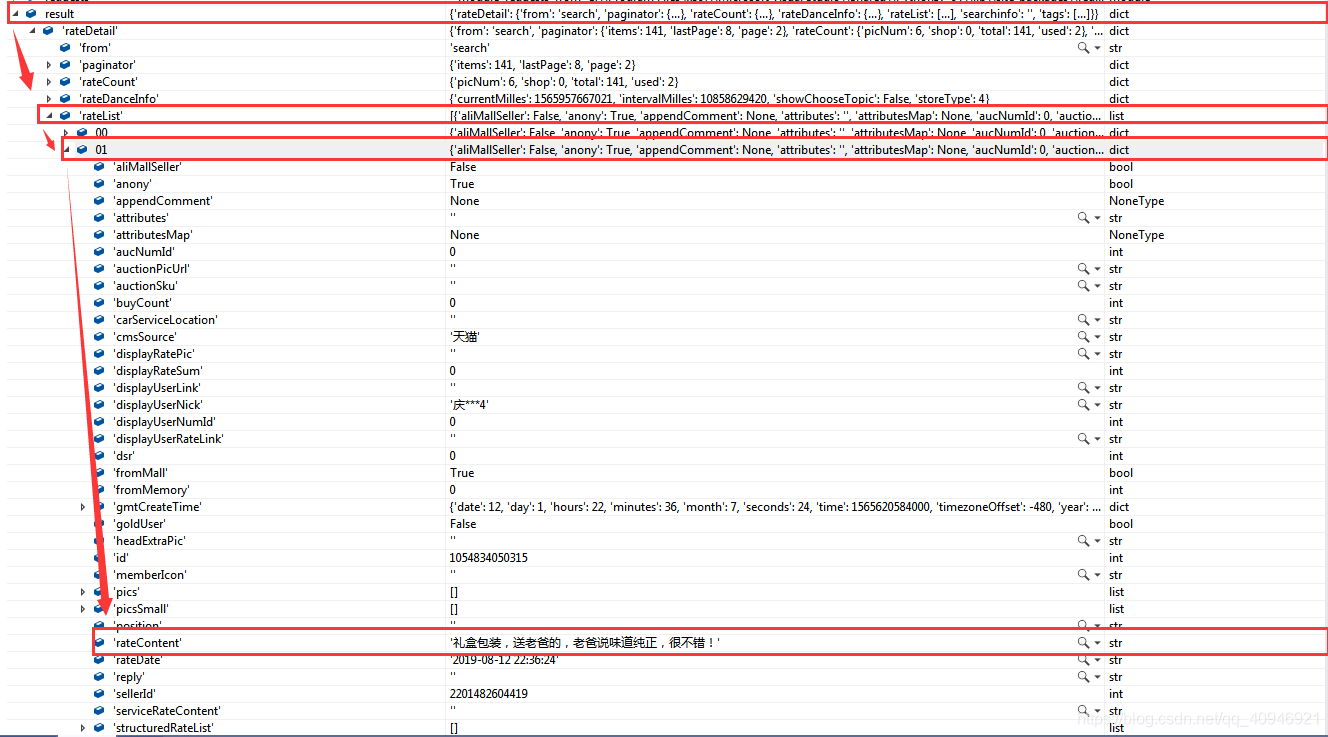 假如我们需要打印这条评论,只需要
假如我们需要打印这条评论,只需要
print(result['rateDetail']['rateList'][1]['rateContent'])上面是一个 获取商品单页评论,下面进行一个整合
import requests
import json
class TaoBao:
lastPage = 1
url="https://rate.tmall.com/list_detail_rate.htm"
header={
"cookie":"cna=eGXNFRhRSkkCAbfhJLKH8aWp; _m_h5_tk=7d827b7269161b2bec1e75221f12e13b_1565891528974; _m_h5_tk_enc=7a2b5c3133447a619a160b42f8bb9335; x=__ll%3D-1%26_ato%3D0; hng=CN%7Czh-CN%7CCNY%7C156; uc1=cookie14=UoTaHoqcxosmvA%3D%3D; uc3=nk2=1DsN4FjjwTp04g%3D%3D&lg2=UIHiLt3xD8xYTw%3D%3D&id2=UondHPobpDVKHQ%3D%3D&vt3=F8dBy3K1GcD57BN%2BveY%3D; t=8d194ab804c361a3bb214233ceb1815c; tracknick=%5Cu4F0F%5Cu6625%5Cu7EA22013; lid=%E4%BC%8F%E6%98%A5%E7%BA%A22013; uc4=nk4=0%401up5I07xsWKbOPxFt%2Bwto8Y%2BdFcW&id4=0%40UOE3EhLY%2FlTwLmADBuTc%2BcF%2B4cKo; lgc=%5Cu4F0F%5Cu6625%5Cu7EA22013; enc=JY20EEjZ0Q4Aw%2BRncd1lfanpSZcoRHGHdAZmqrLUca8sEI9ku3vIBCYdT4Lvd9KJMVpk%2F1TnijPlCpUrJ2ncRQ%3D%3D; _tb_token_=553316e3ee5b5; cookie2=17126dd7c1288f31dc73b09697777108; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; l=cBj2amlRqUrFkhhjBOfgZuI8as7O6CvWGsPzw4_GjICP9H5cIxnlWZeaTSLkCnGVL6Dyr3RhSKO4B8YZjPathZXRFJXn9MpO.; isg=BBMTUm-GSmBFQQYmiWpbMPIdtpf9YKfi0yhVD8U0EzPgRD_mR5uf2DzSfvSPZP-C",
"referer":"https://detail.tmall.com/item.htm",
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.37",
}
params={ #必带信息
"itemId":"0", #商品id
"sellerId":"2616970884",
"currentPage":"1", #页码
"order":"1", #排序方式:1:按时间降序 3:默认排序
"callback":"jsonp2359",
}
def __init__(self,id:str):
self.params['itemId']=id
def getPageData(self,pageIndex:int):
self.params["currentPage"]=str(pageIndex)
req=requests.get(self.url,self.params,headers=self.header,timeout = 2).content.decode('utf-8'); #解码,并且去除str中影响json转换的字符(\n\rjsonp(...));
req=req[req.find('{'):req.rfind('}')+1]
return json.loads(req)
def setOrder(self,way:int):
self.params["order"]=way;
def getAllData(self):
Data=self.getPageData(1)
self.lastPage= Data['rateDetail']['paginator']['lastPage']
for i in range(2,self.lastPage+1):
Data['rateDetail']['rateList'].extend(self.getPageData(i)['rateDetail']['rateList'])
taobao=TaoBao("555082135230")
k=taobao.getPageData(1)
print(k)