centos7搭建伪分布式集群
需要
centos7虚拟机一台;
jdk-linux安装包一个
hadoop-2.x安装包1个(推荐2.7.x)
一、设置虚拟机网络为静态IP(最好设成静态,为之后编程提供方便,不设置静态ip也可以)
1、进入网络配置查看ip
2、选择NAT模式链连接

3、点击NAT设置,记住网关IP,后面要用到

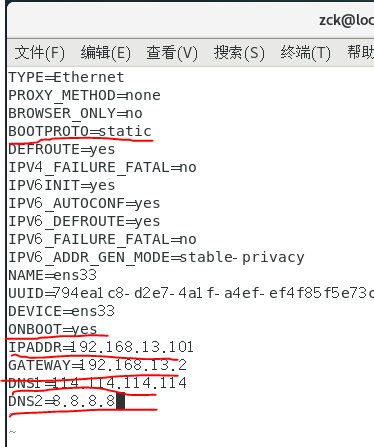
4、进入终端,输入命令: cd /etc/sysconfig/network-scripts,然后 vim ./ifcfg-eth0,(有的虚拟机是文件是:ifcfg-ens33)并进行如下设置,
【IPADDR为静态ip地址,格式必须与网关IP的前三位一样:192.168.13.X】 X在1-255之间
GATWAY是之前记得的网关IP.
其他的如图所示。
5、重启网络服务:service network restart

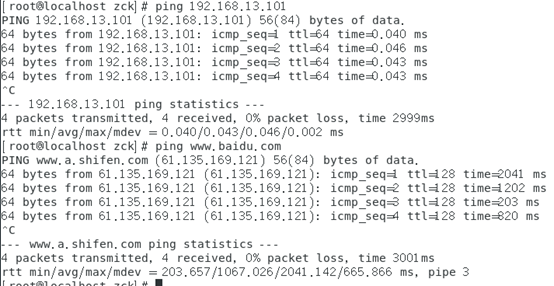
6、网络测试:ping网关,ping外网。都能ping通表示网络正常,大功告成(前提主机联网)
成功标志如图:
二、配置ssh免密登录(开启集群服务时不必每次都输入密码)
1、命令:ssh-keygen 一路回车。遇到overwrite(覆盖写入)输入y
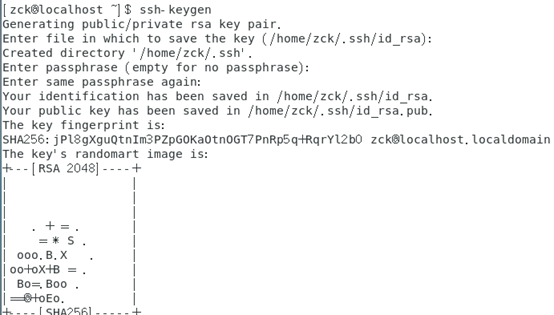
2、将生成的密钥发送到本机地址:ssh-copy-id localhost
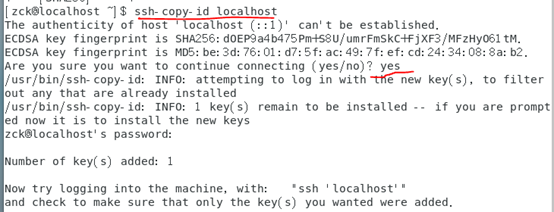
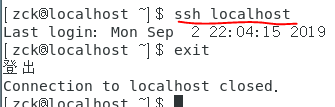
3、测试是否可以免密登录。出现下图解果就OK;
三、安装java环境(jdk)
1、卸载虚拟机自带的dk;
确定JDK版本
rpm –qa | grep jdk
rpm –qa | grep gcj

切换到root用户,根据结果卸载java
yum -y remove java-1.8.0-openjdk-headless.x86_64
yum -y remove java-1.7.0-openjdk-headless.x86_64
2、测试jdk是否卸载干净 java -version

3、安装jdk.
将jdk-linux-xxx解压到某一个文件夹(记好路径,不要有中文)

通过pwd命令查看当前路径

4、配置环境变量
在root用户下,将/etc/profile的权限赋给普通用户:chown -R zck:zck /etc/profile (zck是我的普通用户名,不然普通用户无法修改环境变量)


转到普通用户(zck)下,修改环境变量:vim /etc/profile (注意自己的jdk路径)


| #java export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141 export JAVA_JRE=JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin |
5、保存退出,并使/etc/profile文件生效:source /etc/profile

6、测试jdk环境:java -version

四、安装hadoop
1、解压hadoop(同jdk)
2、配置环境变量(基本步骤与jdk一样)。
| #hadoop |

3、测试(保存之后要source /etc/profile 不然环境变量修改不生效)
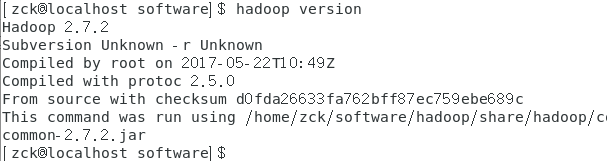
五、搭建伪分布式
修改6个配置文件
进入文件目录 ../hadoop/etc/hadoop
1、修改core-site.xml配置文件 (建议将localhost修改为你之前设置的静态ip)
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration> |
2、修改hdfs-site.xml配置文件
| <configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/dfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dfs/data</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> |
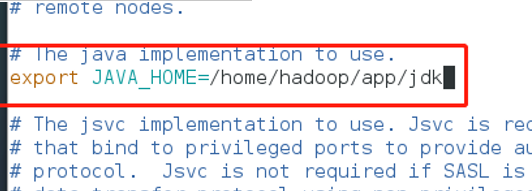
3、修改hadoop-env.sh配置文件(改成jdk位置)
4、修改mapred-site.xml.template配置文件(先重命名为mapred-site.xml)
| <configuration> <property> <name>mapreduce.frameword.name</name> <value>yarn</value> </property> </configuration> |
5、修改yarn-site.xml配置文件
| <property> <name>yarn.nodemanager.aux-servies</name> <value>mapreduce_shuffle</value> </property> </configuration> |
使修改生效,命令:sourec /etc/profile
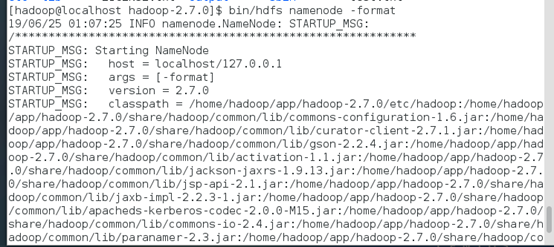
6、格式化namenode
切回到hadoop目录,输入如下命令:bin/hdfs namenode -format
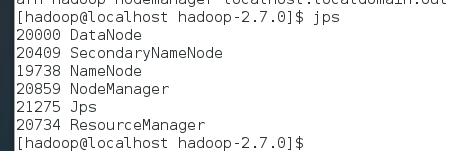
启动hadoop伪分布式集群:sbin/start-all.sh

启动完毕输入jps查看