PG
当Ceph 集群接收到数据存储的请求时,它被分散到各个 PG 中。然而, CRUSH 首先将数据分解成 一组对象,然后根据对象名称、复制级别和系统中总的 PG 数目等信息执行散列操作,再将结果生成 PG ID。 PG 是一组对象的逻辑集合,通过复制它到不同的 OSD 上来提供存储系统的可靠性。 根据 Ceph 池的复制级别,每个 PG 的数据会被复制并分发到 Ceph集群的多个 OSD上。 可以将 PG 看成一个逻辑容器,这个容器包含多个对象,同时这个逻辑容器被映射到多个 OSD上。 PG 是保障 Ceph 存储系统的可伸缩性和性能必不可少的部分。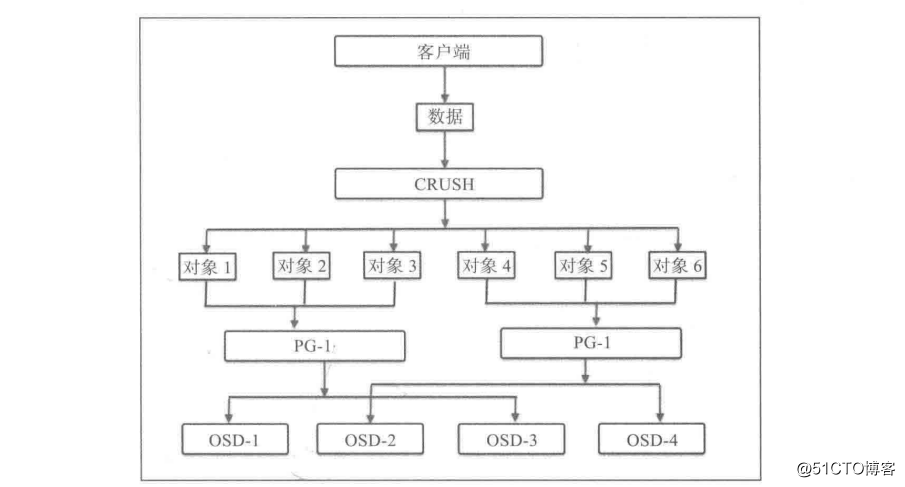
没有 PG ,在成千上万个 OSD 上管理和跟踪数以百万计的对象的复制和传播是相当困难的。 没有 PG 情况下管理这些对象所消耗的计算资源也是噩梦。 与独立的管理每一个对象不同的是,我们的系统只管理包含大量对象的 PG。 这使得 Ceph 成为一个更易于管理和更易上手的系统。 每个 PG 需要一定的系统资源(如 CPU 和内存),因为每个 PG 需要管理多个对象 。因此应该精心计算集群中 PG 的数量 。一般来说,增加集群 PG 的数量能够降低每个 OSD 上的负载,但是应该以规范的方式进行增加, 建议每个 OSD上放置 50 - 100个PG。 这是为了避免 PG 占用 OSD 节点太多的资源。 随着存储数据的增加,同样需要根据集群规模来调整 PG数, 当在集群中添加或者删除一个设备的时候,大部分的 PG 保持不变;CRUSH 管理 PG 在整个集群内部的分布。PGP 是用于定位的 PG 的总数,它应该等于 PG 的总数。
计算 PG数
计算正确的 PG 数是构建一个企业级的 Ceph 存储集群中至关重要的一步。 因为 PG在一定程度上能够提高或者影响存储性能。计算 Ceph 集群中 PG 数的公式如下:
PG 总数= (OSD 总数 100) /最大副本数
结果必须舍入到最接近2的N 次幕的值。比如:如果 Ceph 集群有 160个 OSD 且副本数是3 ,这样根据公式计算得到的 PG 总数是 5333.3 ,因此舍入这个值到最接近的2的N次幕的结果就是 8192个 PG。我们还应该计算 Ceph 集群中每一个池中的 PG 总数 计算公式如下:
PG 总数= ((OSD 总数 100) /最大副本数) /池数
同样使用前面的例子: OSD 总数是 160 ,副本数是3 ,池总数是3。 根据上面这个公式,计算得到每个池的 PG 总数应该是 1777.7 ,最后舍入到 2的N次幕得到结果为每个池 2048个PG。平衡每个池中的 PG 数和每个 OSD 中的 PG 数对于降低 OSD 的方差、避免速度缓慢的恢复进程是相当重要的。
修改 PG PGP
如果你管理一个 Ceph 存储集群,有时你可能需要修改池的 PG 和PGP 的值。 在修改PG和 PGP 之前,我们先来了解一下 PGP 是什么。PGP 是为实现定位而设置的 PG ,它的值应该与 PG 的总数(即 pg num) 保持一致。对于Ceph 的一个池而言,如果你增加 PG 的数目(即 pg_num 的值),你还应该调整 pgp_num到同样的值,这样集群才能够开始再平衡 下文将详细阐述神秘的再平衡机制。参数 pg_num 定义了 PG 的数量,这些 PG 映射到 OSD 当任意池的 pg_num 增加的时候,这个池的每个 PG 一分为二,但它们依然保持跟源 OSD 的映射。直到这个时候,
Ceph 依然没有开始再平衡 此时,当你增加该池的 pgp_num 的值时, PG 才开始从源 OSD迁移到其他 OSD ,正式开始再平衡 从这可以看出, PGP 在集群再平衡中扮演着重要的角色。现在,让我们来学习如何改变 pg_num和 pgp_num:
1 )获取现有的 PG PGP 值:
[root@node140 ~]# ceph osd pool get rbd pg_num
pg_num: 128
[root@node140 ~]# ceph osd pool get rbd pgp_num
pgp_num: 128
2 )使用下面的命令可以检查池的副本数,找到其中 rep size 的值:
[root@node140 ~]# ceph osd dump | grep size
pool 3 'rbd' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode warn last_change 100 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
pool 4 'remote_rbd' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode warn last_change 112 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
3 )依据下面的参数使用公式计算新的 PG 的数目:
OSD 总数 =9,池副本数 (rep size) = 2. 池数 =3
根据前面的公式,得到每个地的 PG 数是 150 ,然后舍入到2的N 次幕 256。
4) 修改池的 PG和PGP:
[root@node140 ~]# ceph osd pool set rbd pg_num 256
set pool 3 pg_num to 256
[root@node140 ~]# ceph osd pool set rbd pgp_num 256
set pool 3 pgp_num to 256
5 )同样,修改 metadata 池和 rbd 池的 PG PGP:
[root@node140 ~]# ceph osd pool set metadata pg_num 256
set pool 3 pg_num to 256
[root@node140 ~]# ceph osd pool set metadata pgp_num 256
set pool 3 pgp_num to 256
注释:引用《ceph分布式存储学习指南》