PG 的数据恢复过程
集群中的设备异常(异常OSD的添加删除操作),会导致PG的各个副本间出现数据的不一致现象,这时就需要进行数据的恢复,让所有的副本都达到一致的状态。想知道如何来进行数据的恢复之前,先要了解OSD故障的种类。
一、OSD的故障和处理办法:
1. OSD的故障种类:
故障A:一个正常的OSD 因为所在的设备发生异常,导致OSD不能正常工作,这样OSD超过设定的时间 就会被 out出集群。
故障B: 一个正常的OSD因为所在的设备发生异常,导致OSD不能正常工作,但是在设定的时间内,它又可以正常的工作,这时会添加会集群中。
2. OSD的故障处理:
故障A:OSD上所有的PG,这些PG就会重新分配副本到其他OSD上。一个PG中包含的object数量是不限制的,这时会将PG中所有的object进行复制,可能会产生很大的数据复制。
故障B:OSD又重新回到PG当中去,这时需要判断一下,如果OSD能够进行增量恢复则进行增量恢复,否则进行全量恢复。(增量恢复:是指恢复OSD出现异常的期间,PG内发生变化的object。全量恢复:是指将PG内的全部object进行恢复,方法同故障A的处理)。
需要全量恢复的操作叫做backfill操作。需要增量恢复的操作叫做recovery操作。
二、OSD恢复时常用的基本概念解析:
(引用自http://blog.csdn.net/changtao381/article/details/49125817,感谢该博主)
上一节当中已经讲述了PG的Peering的过程,Peering就是PG在副本所在的OSD发生变化时的状态演变过程。这一节也和Peering过程是分不开的,但是重点是来讲述数据恢复过程中涉及到的关键步骤。
先来解释一下基本的概念。
1. acting set 和 up set:每个pg都有这两个集合,acting set中保存是该pg所有的副本所在OSD的集合,比如acting[0,1,2],就表示这个pg的副本保存在OSD.0 、OSD.1、OSD.2中,而且排在第一位的是OSD.0 ,表示这个OSD.0是PG的primary副本。 在通常情况下 up set 与 acting set是相同的。区别不同之处需要先了解pg_temp。
2. pg_temp : 假设当一个PG的副本数量不够时,这时的副本情况为acting/up = [1,2]/[1,2]。这时添加一个OSD.3作为PG的副本。经过crush的计算发现,这个OSD.3应该为当前PG的primary,但是呢,这OSD.3上面还没有PG的数据,所以无法承担primary,所以需要申请一个pg_temp,这个pg_temp就还采用OSD.1作为primary,此时pg的集合为acting,pg_temp的集合为up。当然pg与pg_temp是不一样的,所以这时pg的集合变成了[3,1,2]/[1,2,3]。当OSD.3上的数据全部都恢复完成后,就变成了[3,1,2]/[3,1,2]。
3.epoch:当集群中的OSD发生变化,则就会产生新的OSDmap,每个OSDmap都对应一个epoch,epoch按着先后顺序单调递增。epoch越大说明OSDmap越新。
4.current_interval、past_interval:每个PG都有interval。 interval 是一个epoch的序列,在这个interval内,可能存在多个epoch,但是PG的成员却不会改变。如果PG的成员发生变化,则会形成new interval。current是当前的序列,past是指过去的interval。
last_epoch_started:上次经过peering后的osdmap版本号epoch。
last_epoch_clean:上次经过recovery或者backfill后的osdmap版本号epoch。
(注:peering结束后,数据的恢复操作才刚开始,所以last_epoch_started与last_epoch_clean可能存在不同)。
例如:
ceph 系统当前的epoch值为20, pg1.0 的 acting set 和 up set 都为[0,1,2]
-
osd.3失效导致了osd map变化,epoch变为 21
-
osd.5失效导致了osd map变化,epoch变为 22
-
osd.6失效导致了osd map变化,epoch变为 23
上述三次epoch的变化都不会改变pg1.0的acting set和up set
-
osd.2失效导致了osd map变化,epoch变为 24
此时导致pg1.0的acting set 和 up set变为 [0,1,8],若此时 peering过程成功完成,则last_epoch_started 为24
-
osd.12失效导致了osd map变化,epoch变为 25
此时如果pg1.0完成了recovery,处于clean状态,last_epoch_clean就为25
-
osd13失效导致了osd map变化,epoch变为 26
epoch 序列 21,22,23,23 就为pg1.0的past interval
epoch 序列 24,25,26就为 pg1.0的current interval
5.pg_log:pg_log是用于恢复数据重要的结构,每个pg都有自己的log。对于pg的每一个object操作都记录在pg当中。
-
__s32 op; 操作的类型
-
hobject_t soid; 操作的对象
-
eversion_t version, prior_version, reverting_to; 操作的版本
struct pg_info_t
{
spg_t pgid;
eversion_t last_update; //pg 最后一次更新的eversion
//recovery完成后的最后一个everson,也就是pg处于clean状态的最后一次操作的 eversion
eversion_t last_complete;
// last epoch at which this pg started on this osd 这个pg在这个osd上的最近的的开始的epoch,也就是最近一次peering完成后的epoch
epoch_t last_epoch_started;
// last user object version applied to store
version_t last_user_version;
eversion_t log_tail; // oldest log entry.
// objects >= this and < last_complete may be missing
hobject_t last_backfill;
interval_set<snapid_t> purged_snaps; //pg的要删除的snap集合
pg_stat_t stats;
pg_history_t history; //pg的历史信息
pg_hit_set_history_t hit_set; //这个是cache tie用的hit_set
}
三、数据的恢复过程的简要流程描述如下:
1. 生成past_interval (要根据interval确定每个interval期间的osd集合)。
2.根据past_interval 选取参与peering过程的osd集合 build_prior。
3. 拉取prior集合中所有osd的pg_info。
4. 选取权威的osd。
5.拉取权威osd的log与info。与本地log合并。形成本地missing结构
6.拉取其他osd的log与info。与auth log对比,将差异log发送给peer。并且在本地形成peer_missing结构。
7.根据missing和peer_missing结构可知丢失数据定位。
8.peering处理成功,开始进行数据的恢复。
四、数据恢复的具体流程:

详细分析这个过程主要涉及到peering过程的准备与recovering的数据恢复过程。在peering准备过程如上图描述。
peering过程准备工作:
-
确定参与peering过程的osd集合。
-
该集合中合并出最权威的log记录。
-
每一个osd缺失并且需要恢复的object。
-
需要恢复的object可以从哪个osd上进行拷贝。
4.1 恢复的前驱peering过程的准备工作:
在进行解析peering过程中,肯定和上一节讲述的内容是分不开的。但是这里先去除其他异常整理代码,直接从GetInfo处理函数讲起(PG::RecoveryState::GetInfo::GetInfo(my_context ctx))。
在GetInfo函数中先来看一下:
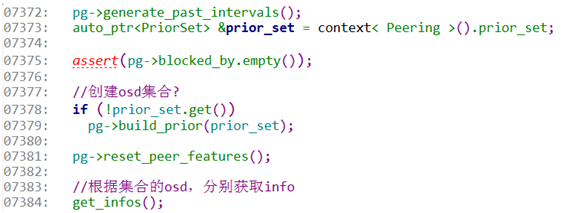
7372:调用generate_past_intervals()函数,生成past_interval序列。首先确定查找interval的start_epoch(history.last_epoch_clean 上次恢复数据完成的epoch)和end_epoch(history.same_interval_since 最近一次interval的起始epoch)。确定了start_epoch和end_epoch之后,循环这个两个版本间的所有osdmap,确定pg成员变化的区间interval。
7379:根据past_interval生成prior set集合。确定prior set集合,如果处于当前的acting和up集合中的成员,循环遍历past_interval中的每一个interval,interval.last >= info.history.last_epoch_started、! interval.acting.empty()、interval.maybe_went_rw,在该interval中的acting集合中,并且在集群中仍然是up状态的。
7384:根据priorset 集合,开始获取集合中的所有osd的info。这里会向所有的osd发送请求info的req(PG::RecoveryState::GetInfo::get_infos())。发送请求后等待回复。
回复的处理函数:PG::RecoveryState::GetInfo::react(const MNotifyRec& infoevt)
主要调用了pg->proc_replica_info进行处理:1.将info放入peerinfo数组中。2.合并history记录。 在这里会等待所有的副本都回复info信息。进入下一个状态GetLog。
在GetLog中处理(PG::RecoveryState::GetLog::GetLog):
-
通过pg->choose_acting(auth_log_shard)选择acting集合和auth_osd.
-
向auth_osd发送查询 log的req。
choose_acting中主要进行了两项重要的措施:
-
find_best_info,查找一个最优的osd。
-
calc_replicated_acting,选择参与peering、recovering的osd集合。
在 find_best_info中查找最优的osd时,判断的条件的优先级有三个:最大的last_update、最小的log_tail、当前的primary。
在calc_replicated_acting中主要进行一下几种分析:
-
up集合中的成员。所有的成员都是加入到acting_backfilling中,如果是incomplete状态的成员或者 日志衔接不上的成员(cur.last_update<auth.log_tail)则添加到backfill中,否则添加到want成员中。
-
acting集合中的成员,该组内的成员不会添加到backfill中,所以只需要判断 如果状态是complete并且 日志能够衔接的上,则添加到want和acting_backfilling中。
-
其他prior中的osd成员 处理同acting一致。
经过这一步可知,acting_backfilling的成员(可用日志恢复数据,或者帮助恢复数据的成员),backfill的成员(只能通过其他的osd上pg的数据进行全量拷贝恢复),want的成员(同样在acting_backfill中,但是不同于backfill的成员)。
以上在GetLog中的工作就都完成了,然后想best_osd发送log请求,等待best_osd回复。
best_osd回复PG::RecoveryState::GetLog::react(const GotLog&):
-
使用pg->proc_master_log()处理来自best_osd的log。
-
跳转到GetMissing的处理
在pg->proc_master_log()中
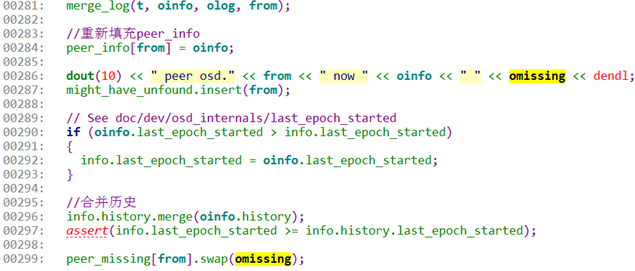
0281:调用merge_log函数,该函数对log进行合并,形成一个权威顺序完整的一个log。包括日志前后的修补,而且最重要的是修补的过程中,统计了本地副本中需要恢复object的情况missing.add_next_event(ne)。这里已经开始统计missing结构了。
0284:保存来自best_log的oinfo到本地的peer-info数组中。
0296:需要对history信息进行合并。
0299:将missing结构统计到本地的peer_missing结构中。
这是一个很重要的处理过程,涉及到两个重要的点,
-
auth_log:一个是auth_log的合并,最大最权威的log,恢复数据要根据这里进行。
-
missing:另外就是合并log过程中发现本地副本需要恢复的object集合。
-
omissing:auth_osd需要进行恢复的object集合。
接下来该进入GetMissing处理中(PG::RecoveryState::GetMissing::GetMissing(my_context ctx)):
循环遍历actingbackfill 成员,拉取所有成员的log和missing信息。等待回复。
在回复PG::RecoveryState::GetMissing::react(const MLogRec& logevt)中:
接收到其他osd发回的log信息并且进行处理,主要为pg->proc_replica_log处理。
在proc_replica_log中对peer_log进行修剪,丢弃那些不完整不可用的log。整理接收到的oinfo到peerinfo中,omissing到peer_missing中。接下来可以选择跳过NeedUpThru(因为 我不知道这个什么作用),直接来到active状态。
在active处理 PG::RecoveryState::Active::Active(my_context ctx):
在这里主要调用了pg->activate()处理。
这里首先进行了一些细节的处理,这些细节对于流程的控制起到很重要的作用,但是不是关键的流程,下面截取一些关键流程。
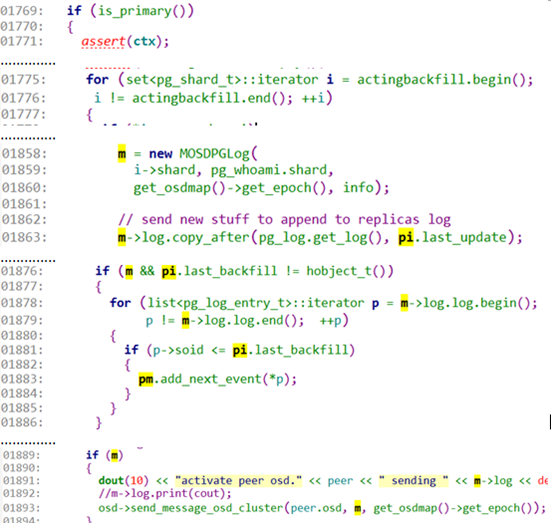
1769:这里主要由primary osd进行处理。发起流程。
1775:开始循环处理 replica osd,因为这些osd都添加在actingbackfill中。这些replica可能有缺失log,所以要进行log的修补。
1858:如果存在一些replica osd需要进行log的修补工作,则创建一个message用于传递修补的log。
1863:这里知道需要修补的log从last_update开始。使用copy_after拷贝之后的log。
1876:判断如果不是所有的object都修复了,则需要记录missing结构。
1878:循环遍历需要修补的log list。
1881:判断这个log记录的 object是不是还没修补呢。
1883:如果这个object还没来得及修补,则添加到pm中,记录这object需要被恢复。
1893:将这个用于修补log的message发送给对应的osd。等待回应。
上面一部分主要进行了每个osd的差异log整理工作,并且将这个log组织在message中,准备发送给对应的osd。而且根据缺失log确定了该osd需要恢复的object,放在pm的结构中。
对于每一个peer osd 都进行了缺失log的整理工作,并且也整理了peer_missing 存放每个osd需要恢复的object。现在知道了每个osd需要恢复的object,但是不知道这些object需要从哪个osd上拉取object数据,所以还需要确定这些需要恢复的object可以在哪个osd进行拉取数据。这部分处理可以看下这个图。
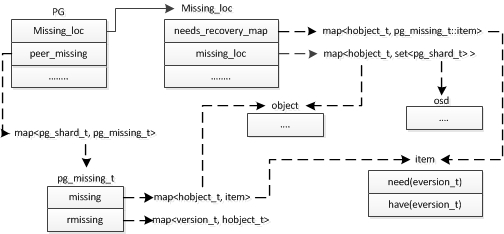
1. 首先这里都知道了pg->peer_missing结构,因为上面根据缺失log可知这些需要恢复的object,这些object记录在peermissing->missing结构中。
2.接下来结果转换将整理统计 哪些object需要恢复,当然将整理的结果添加到pg->missing_loc->needs_recovery_map结构中保存。这样可以按着object进行恢复。
3.知道了哪些object需要进行恢复,还要继续确定这些object可以从哪些osd中拉取,将每个object可以拉取数据的osd 集合使用 pg->Missing_loc->missing_loc保存。
经过上面的步骤可以得到一下条件:
1. 每个osd需要恢复的object集合 ,保存在peer_missing结构中。
2. 这次recovery过程所有需要恢复的object,保存在need_recovery_map中。
3.这些需要恢复的object可以从哪些osd上拉取数据,保存在 missing_loc结构中。
接下来看代码是怎么实现的,因为前面已经说过了peermissing的组织,所以这里直接从第二条need_recovery_map结构组织开始(还是pg->activate()):

1913:仍然循环处理 actingbackfill 列表中的所有的成员。
1917:如果是primary osd则添加primary osd的missing,这里使用add_active_missing()函数,就是将丢失的object直接添加到need_recovery_map中。
1922:这里是将其他osd的missing中记录的object添加到need_recovery_map中。
接下来就是要进行第三个结构missing_loc的组织了:
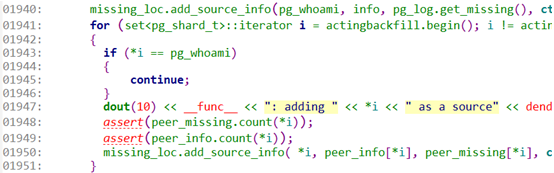
1940:先开始处理本地missing结构,使用add_source_info()函数处理。该函数处理主要是对比当前osd的missing列表和need_recovery列表,如果不在missing列表,却在need_recovery_map列表的object,可以从本osd上拉取数据,将这个osd记录起来missing_loc[soid].insert(fromosd)。
1941:开始循环处理其他的osd。
1950:处理其他osd上的missing结构,处理方法同1941。
这样三部分的数据都有了,下面就可以进行数据的恢复了。
这样等待所有的osd都发回了确认ack(差异日志发送给osd)信息,进入如下处理的函数中PG::RecoveryState::Active::react(const AllReplicasActivated &evt),这里主要调用了pg->on_activate(),该方法是由ReplicatedPG::on_activate()实现的。经过一系列的变化(上一节中详细讲述了),达到recovering状态。最后将这个pg添加到了osd->recovery_queue中,recovery_queue是一个工作队列,会有专门处理的线程来进行处理。该线程的主处理函数为void OSD::do_recovery(PG *pg, ThreadPool::TPHandle &handle),解决着调用ReplicatedPG::start_recovery_ops()。

9497:获取主osd上的missing 统计结果。
9499:获取主osd上缺失并且需要恢复的object数量。
9500:获取定位缺失数据中 缺少数据源的object数量。
9507:如果 主osd上丢失的object 数量 与 无法定位数据源的object数量相同。也就是主osd上丢失的object暂时无法恢复。
9511:开始先恢复replicas osd上的数据。
9514:直到 replicas osd上数据全都恢复完毕,或者无数据可以恢复时。
9517:开始进行 primary osd上的数据恢复。
9520:如果前面两项都进行了数据恢复,但是仍然有object没有被恢复,则再次恢复replicas上缺失的object。
上面进行了三次恢复的操作,第一次恢复replicas副本,第二次恢复primary 副本,第三次恢复replicas副本,为了恢复数据的流控,在恢复的时候设置了阀值,每次恢复的上限就是阀值,超过阀值后,会将该pg重新添加到recovery_wq队列中,等待下次被处理,同样上面的三次恢复操作之间存在依赖关系,所以必须一个恢复完再尝试恢复第二个,如果恢复完第一个后,不再进行第二个,第三的恢复,直接重新添加到recovery_wq中,直到第一个被恢复完成,再次添加到recovery_wq中,下次才会进行第二个恢复操作。
所有的数据恢复都要经过primary osd,
1. 如果primary osd出现数据丢失object,则由primary osd主动pull拉取replicas osd上的object数据。
2. 如果 replicas osd 上出现数据丢失object,则由primary osd 主动push 推送replicas osd上的 object数据。
3.如果primary osd 和 部分replica osd缺失object数据,则先由primary osd从正常的replica osd上拉取数据,进行本地恢复。下一次再把数据推送到需要恢复的osd上。