ceph scrub介绍
- scrub的调度
1.1 相关数据结构
1.2 scrub的调度实现
1.2.1 OSD::sched_scrub函数
1.2.2 PG::sched_scrub()函数
1.3 scrub资源预约消息转换 - scrub的实现
2.1 相关数据结构
2.1.1 Scrubber
2.1.2 Scrubmap
2.2 Scrub的控制流程
2.2.1 chunky_scrub()
2.3 构建Scrubmap
2.3.1 build_scrub_map_chunk
2.3.2 PGBackend::be_scan_list
2.3.3 ReplicatedBackend::be_deep_scrub
2.4 从副本处理,构建scrubmap
2.5 副本对比
2.5.1 scrub_compare_maps
2.5.2 be_compare_scrubmaps
2.5.3 be_select_auth_object
2.6 结束scrub过程
ceph scrub介绍
ceph通过scrub保证数据的一致性,scrub 以PG 的chunky为单位,对于每一个pg,ceph 分析该pg下的所有object, 产生一个类似于元数据信息摘要的数据结构,如对象大小,属性等,叫scrubmap, 比较所有有副本的scrubmap,选出auth 对象,通过对比auth 对象,得到缺失或者损坏的对象,并进行修复。scrub(daily)比较object size 和属性。deep scrub (weekly)读取数据部分并通过checksum(这里是CRC32)比较保证数据一致性。 每次scrub 只取chunk(chunk大小可以通过ceph的配置选项进行配置)数量的object比较,这期间被校验对象的数据是不能被修改的,所以write请求会被block。等待该chunk的对象scrub完毕,会把阻塞的请求重新加入队列,进行处理。 scrub操作可以手动触发,也会根据配置项和系统负载情况每天定时触发。
1. scrub的调度
scurb的调度解决了一个PG何时启动scrub扫描机制。主要有以下方式:
- 手动立即启动;
- 后台设置一定间隔,按照间隔来启动,比如一天执行一次;
- 设置启动时间段。一般选择比较系统负载较轻的时间段进行;
图一:scrub的调度
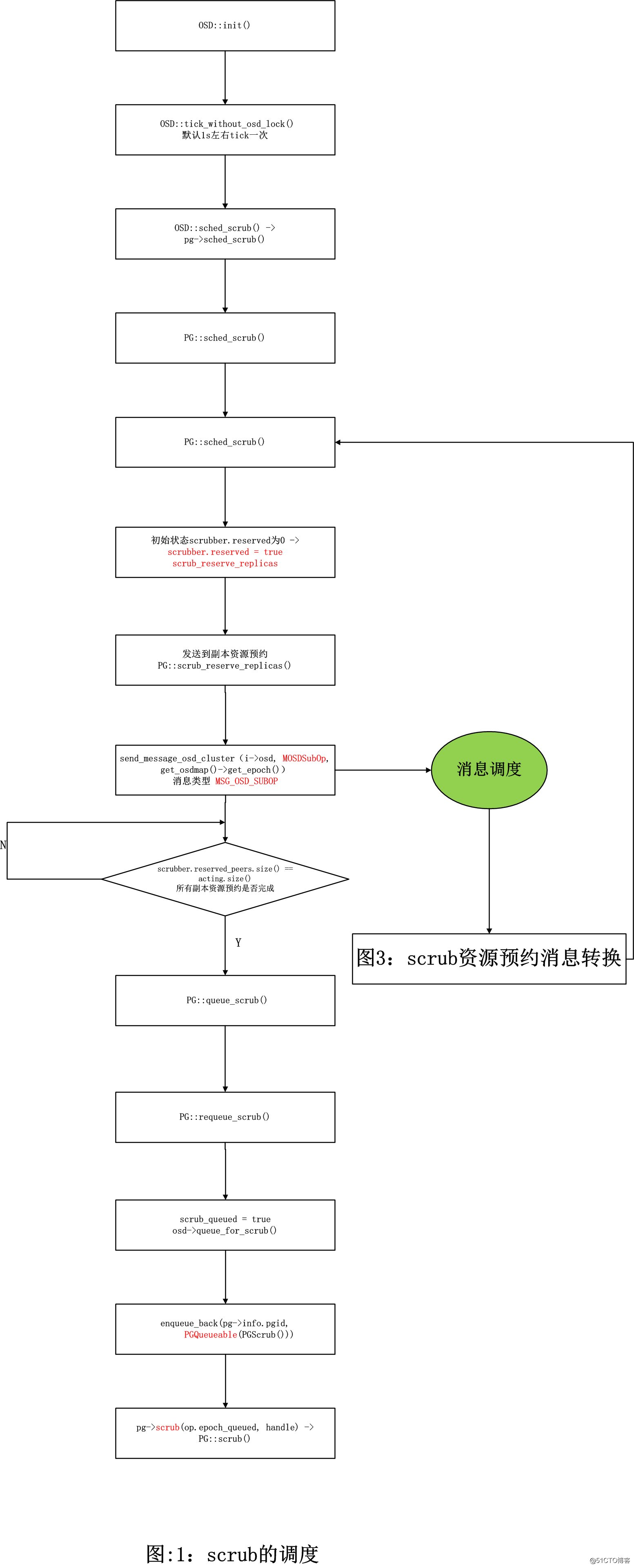
1.1 相关数据结构
class OSDService {
// -- scrub scheduling --
Mutex sched_scrub_lock;//scrub 相关变量的保护锁
int scrubs_pending;//资源预约已经成功,等待scrub的pg
int scrubs_active;//正在进行scrub的pg
}
struct ScrubJob {//封装了一个pg 的scrub相关参数
CephContext* cct;
/// pg to be scrubbed
spg_t pgid;
/// a time scheduled for scrub. but the scrub could be delayed if system
/// load is too high or it fails to fall in the scrub hours
utime_t sched_time;
/// the hard upper bound of scrub time
utime_t deadline;
}1.2 scrub的调度实现
该定时任务大概每隔1s就会触发 OSD::tick_without_osd_lock() 一次,L版本中给了个增益的因子,时间稍微1s上下调动;
int OSD::init()
{
{
Mutex::Locker l(tick_timer_lock);
tick_timer_without_osd_lock.add_event_after(get_tick_interval(),
new C_Tick_WithoutOSDLock(this));
}
}
double OSD::get_tick_interval() const
{
// vary +/- 5% to avoid scrub scheduling livelocks
constexpr auto delta = 0.05;
std::default_random_engine rng{static_cast<unsigned>(whoami)};
return (OSD_TICK_INTERVAL *
std::uniform_real_distribution<>{1.0 - delta, 1.0 + delta}(rng));
}
class OSD::C_Tick_WithoutOSDLock : public Context {
OSD *osd;
public:
explicit C_Tick_WithoutOSDLock(OSD *o) : osd(o) {}
void finish(int r) override {
osd->tick_without_osd_lock();
}
};
void OSD::tick_without_osd_lock()
{
if (is_active()) {
if (!scrub_random_backoff()) {
sched_scrub();// 调度scrub
}
}
}1.2.1 OSD::sched_scrub函数
本函数用于控制一个PG的scrub过程启动时机。
- 检查配额是否允许启动scrub操作;
- osd 是否处于recovery过程中,如果是,不会进行scrub
- 检查是否在scrub允许时间段内
- 检查当前系统负载是否允许
- 获取第一个等待scrub的scrubjob
- pg 支持scrub并且是active状态,才会进行scrub
void OSD::sched_scrub()
{
// if not permitted, fail fast
if (!service.can_inc_scrubs_pending()) {
return;
}
//osd处于recovery过程中,不会进行scrub
if (!cct->_conf->osd_scrub_during_recovery && service.is_recovery_active()) {//osd_scrub_during_recovery=false
dout(20) << __func__ << " not scheduling scrubs due to active recovery" << dendl;
return;
}
utime_t now = ceph_clock_now();
bool time_permit = scrub_time_permit(now);// 检查是否在scrub允许时间段内
bool load_is_low = scrub_load_below_threshold();// 检查当前系统负载是否允许
dout(20) << "sched_scrub load_is_low=" << (int)load_is_low << dendl;
OSDService::ScrubJob scrub;
if (service.first_scrub_stamp(&scrub)) {//获取第一个等待scrub的scrubjob
do {
dout(30) << "sched_scrub examine " << scrub.pgid << " at " << scrub.sched_time << dendl;
if (scrub.sched_time > now) {// 还没到时间,跳过执行下一个任务
// save ourselves some effort
dout(10) << "sched_scrub " << scrub.pgid << " scheduled at " << scrub.sched_time
<< " > " << now << dendl;
break;
}
if ((scrub.deadline >= now) && !(time_permit && load_is_low)) {
dout(10) << __func__ << " not scheduling scrub for " << scrub.pgid << " due to "
<< (!time_permit ? "time not permit" : "high load") << dendl;
continue;
}
PG *pg = _lookup_lock_pg(scrub.pgid);
if (!pg)
continue;
if (pg->get_pgbackend()->scrub_supported() && pg->is_active()) {// pg 支持scrub并且是active状态,才会进行scrub
dout(10) << "sched_scrub scrubbing " << scrub.pgid << " at " << scrub.sched_time
<< (pg->scrubber.must_scrub ? ", explicitly requested" :
(load_is_low ? ", load_is_low" : " deadline < now"))
<< dendl;
if (pg->sched_scrub()) {// 执行scrub操作
pg->unlock();
break;
}
}
pg->unlock();
} while (service.next_scrub_stamp(scrub, &scrub));
}
dout(20) << "sched_scrub done" << dendl;
}1.2.2 PG::sched_scrub()函数
- 主osd触发primary、pg active、pg clean、pg 没有在scrub过程中,这些条件任何一个为假直接退出scrub调度;
- 设置deep_scrub_interval,如果该值没有设置,就设置为osd_deep_scrub_interval(7_day)
- time_for_deep 判断是否执行deep-scrub。
- scrub和recovery过程类似,都需要耗费大量的系统资源,需要到PG所在的OSD上进行资源预约。如果scrubber.reserved 为false,代表着还没有预约完成,需要先进行资源预约。
-
- 本端置为scrubber.reserved = true
-
- 把自己加入到scrubber.reserved_peers中
-
- 调用scrub_reserve_replicas向其他osd发送资源预约请求.
涉及MOSDScrubReserve::REQUEST,MOSDScrubReserve::GRANT,MOSDScrubReserve::REJECT,MOSDScrubReserve::RELEASE。
参考《1.3 scrub资源预约消息转换》
- 当 scrubber.reserved_peers.size() == acting.size()说明所有osd资源预约成功,然后判断是否要进行deep操作。调用 PG::queue_scrub() 函数把该PG加入到op_wq 中,触发scrub任务执行。
bool PG::sched_scrub()
{
bool nodeep_scrub = false;
assert(is_locked());
//主osd触发primary、pg active、pg clean、pg 没有在scrub过程中,这些条件任何一个为假直接退出scrub调度;
if (!(is_primary() && is_active() && is_clean() && !is_scrubbing())) {
return false;
}
double deep_scrub_interval = 0;
pool.info.opts.get(pool_opts_t::DEEP_SCRUB_INTERVAL, &deep_scrub_interval);
if (deep_scrub_interval <= 0) {
deep_scrub_interval = cct->_conf->osd_deep_scrub_interval;//7_day
}
bool time_for_deep = ceph_clock_now() >=
info.history.last_deep_scrub_stamp + deep_scrub_interval;
bool deep_coin_flip = false;
// Only add random deep scrubs when NOT user initiated scrub
if (!scrubber.must_scrub)//must_scrub 为用户手动启动deepscrub操作
deep_coin_flip = (rand() % 100) < cct->_conf->osd_deep_scrub_randomize_ratio * 100;//osd_deep_scrub_randomize_ratio =0.15
//sched_scrub: time_for_deep=0 deep_coin_flip=0
dout(20) << __func__ << ": time_for_deep=" << time_for_deep << " deep_coin_flip=" << deep_coin_flip << dendl;
time_for_deep = (time_for_deep || deep_coin_flip);
//NODEEP_SCRUB so ignore time initiated deep-scrub
if (osd->osd->get_osdmap()->test_flag(CEPH_OSDMAP_NODEEP_SCRUB) ||
pool.info.has_flag(pg_pool_t::FLAG_NODEEP_SCRUB)) {
time_for_deep = false;
nodeep_scrub = true;
}
if (!scrubber.must_scrub) {
assert(!scrubber.must_deep_scrub);
//NOSCRUB so skip regular scrubs
if ((osd->osd->get_osdmap()->test_flag(CEPH_OSDMAP_NOSCRUB) ||
pool.info.has_flag(pg_pool_t::FLAG_NOSCRUB)) && !time_for_deep) {
if (scrubber.reserved) {
// cancel scrub if it is still in scheduling,
// so pgs from other pools where scrub are still legal
// have a chance to go ahead with scrubbing.
clear_scrub_reserved();
scrub_unreserve_replicas();
}
return false;
}
}
if (cct->_conf->osd_scrub_auto_repair/*default false*/
&& get_pgbackend()->auto_repair_supported()
&& time_for_deep
// respect the command from user, and not do auto-repair
&& !scrubber.must_repair
&& !scrubber.must_scrub
&& !scrubber.must_deep_scrub) {
dout(20) << __func__ << ": auto repair with deep scrubbing" << dendl;
scrubber.auto_repair = true;
} else {
// this happens when user issue the scrub/repair command during
// the scheduling of the scrub/repair (e.g. request reservation)
scrubber.auto_repair = false;
}
bool ret = true;
if (!scrubber.reserved) {// 还没有完成资源预约
assert(scrubber.reserved_peers.empty());
if ((cct->_conf->osd_scrub_during_recovery/*false*/ || !osd->is_recovery_active()) &&
osd->inc_scrubs_pending()) {
dout(20) << __func__ << ": reserved locally, reserving replicas" << dendl;
scrubber.reserved = true;
scrubber.reserved_peers.insert(pg_whoami);
scrub_reserve_replicas();//向其他osd发送资源预约请求
} else {
dout(20) << __func__ << ": failed to reserve locally" << dendl;
ret = false;
}
}
if (scrubber.reserved) {
if (scrubber.reserve_failed) {
dout(20) << "sched_scrub: failed, a peer declined" << dendl;
clear_scrub_reserved();
scrub_unreserve_replicas();
ret = false;
} else if (scrubber.reserved_peers.size() == acting.size()) {//所有副本预约成功
dout(20) << "sched_scrub: success, reserved self and replicas" << dendl;
if (time_for_deep) {
dout(10) << "sched_scrub: scrub will be deep" << dendl;
state_set(PG_STATE_DEEP_SCRUB);
} else if (!scrubber.must_deep_scrub && info.stats.stats.sum.num_deep_scrub_errors) {
if (!nodeep_scrub) {
osd->clog->info() << "osd." << osd->whoami
<< " pg " << info.pgid
<< " Deep scrub errors, upgrading scrub to deep-scrub";
state_set(PG_STATE_DEEP_SCRUB);
} else if (!scrubber.must_scrub) {
osd->clog->error() << "osd." << osd->whoami
<< " pg " << info.pgid
<< " Regular scrub skipped due to deep-scrub errors and nodeep-scrub set";
clear_scrub_reserved();
scrub_unreserve_replicas();
return false;
} else {
osd->clog->error() << "osd." << osd->whoami
<< " pg " << info.pgid
<< " Regular scrub request, deep-scrub details will be lost";
}
}
queue_scrub();//把该pg加入到工作队列op_wq 触发scrub任务执行
} else {
// none declined, since scrubber.reserved is set
dout(20) << "sched_scrub: reserved " << scrubber.reserved_peers << ", waiting for replicas" << dendl;
}
}
return ret;
}
//PG::sched_scrub()-> PG::queue_scrub()->PG::requeue_scrub() -> queue_for_scrub() ->PGQueueable::RunVis::operator() ->pg->scrub(op.epoch_queued, handle)
bool PG::queue_scrub()
{
assert(is_locked());
if (is_scrubbing()) {
return false;
}
scrubber.priority = scrubber.must_scrub ?
cct->_conf->osd_requested_scrub_priority/*120*/ : get_scrub_priority();
scrubber.must_scrub = false;
state_set(PG_STATE_SCRUBBING);
if (scrubber.must_deep_scrub) {
state_set(PG_STATE_DEEP_SCRUB);
scrubber.must_deep_scrub = false;
}
if (scrubber.must_repair || scrubber.auto_repair) {
state_set(PG_STATE_REPAIR);
scrubber.must_repair = false;
}
requeue_scrub();
return true;
}
bool PG::requeue_scrub(bool high_priority)
{
assert(is_locked());
if (scrub_queued) {
dout(10) << __func__ << ": already queued" << dendl;
return false;
} else {
dout(10) << __func__ << ": queueing" << dendl;
scrub_queued = true;
osd->queue_for_scrub(this, high_priority);
return true;
}
}
void queue_for_scrub(PG *pg, bool with_high_priority) {
unsigned scrub_queue_priority = pg->scrubber.priority;
if (with_high_priority && scrub_queue_priority < cct->_conf->osd_client_op_priority) {
scrub_queue_priority = cct->_conf->osd_client_op_priority;
}
enqueue_back(
pg->info.pgid,
PGQueueable(
PGScrub(pg->get_osdmap()->get_epoch()),
cct->_conf->osd_scrub_cost,
scrub_queue_priority,
ceph_clock_now(),
entity_inst_t(),
pg->get_osdmap()->get_epoch()));
}
void PGQueueable::RunVis::operator()(const PGScrub &op) {
pg->scrub(op.epoch_queued, handle);
}
1.3 scrub资源预约消息转换
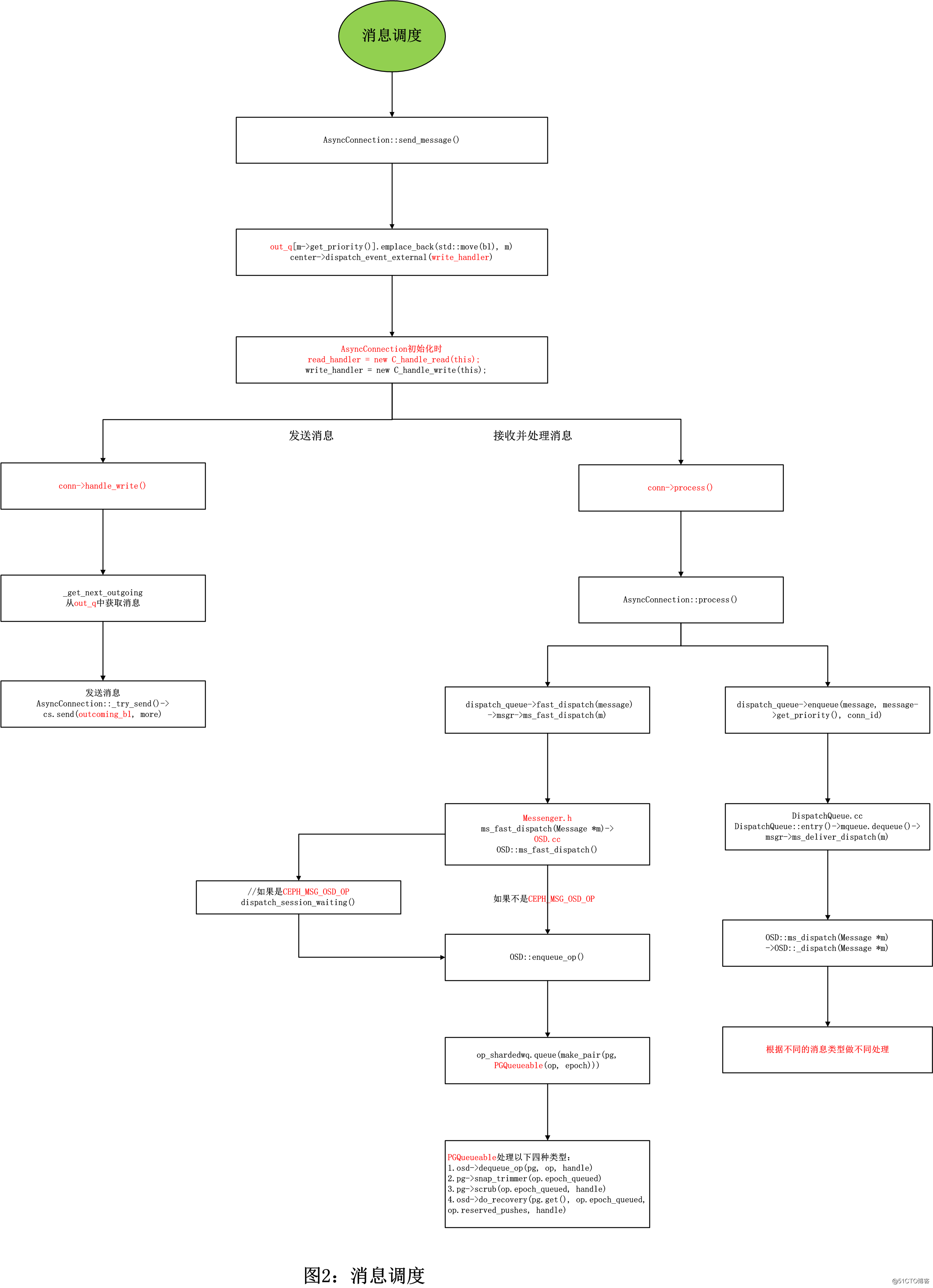
图二:scrub消息调度
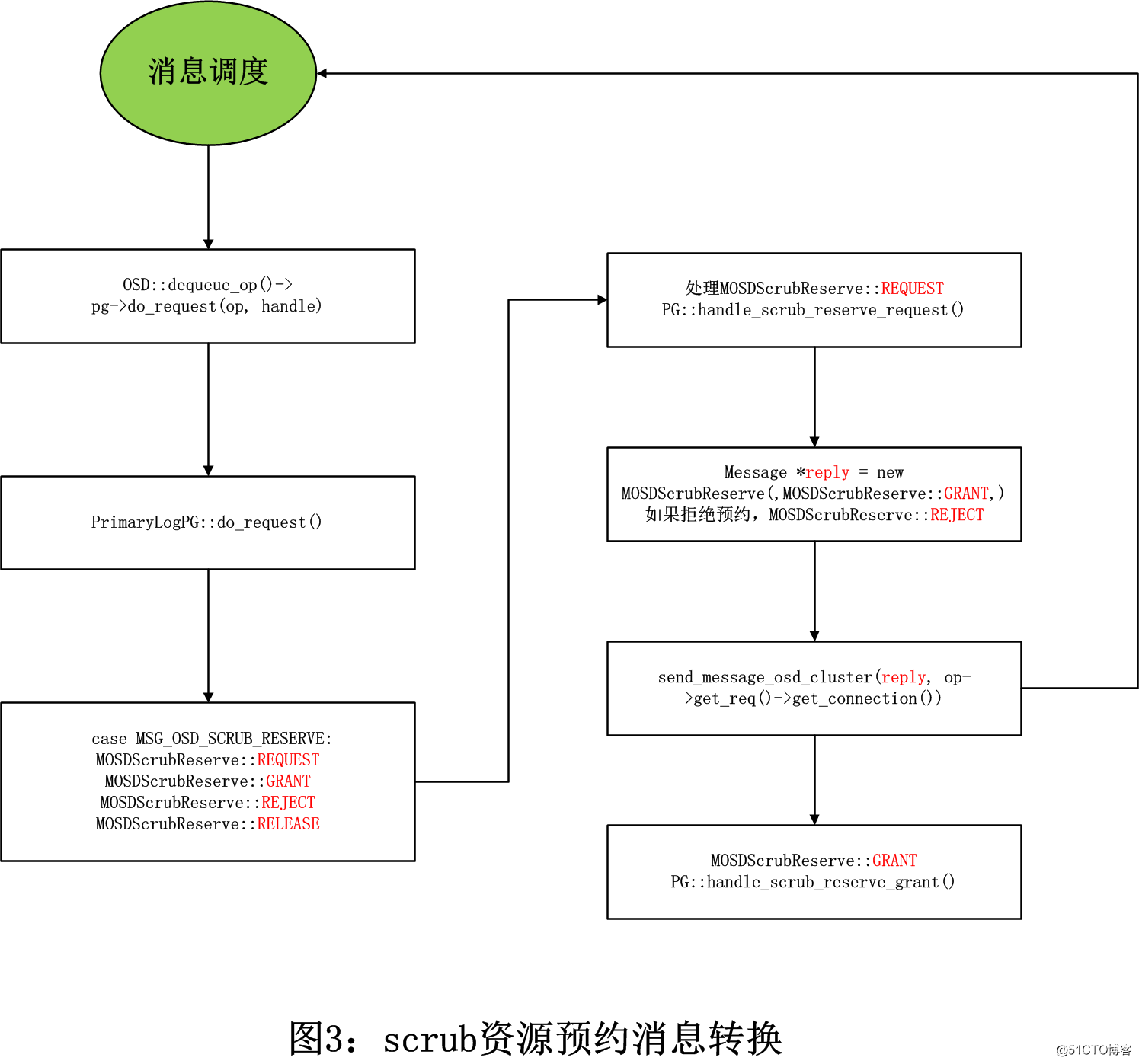
图三:scrub资源预约消息转换
void OSDService::send_message_osd_cluster(int peer, Message *m, epoch_t from_epoch)
{
OSDMapRef next_map = get_nextmap_reserved();
// service map is always newer/newest
assert(from_epoch <= next_map->get_epoch());
if (next_map->is_down(peer) ||
next_map->get_info(peer).up_from > from_epoch) {
m->put();
release_map(next_map);
return;
}
const entity_inst_t& peer_inst = next_map->get_cluster_inst(peer);
ConnectionRef peer_con = osd->cluster_messenger->get_connection(peer_inst);
share_map_peer(peer, peer_con.get(), next_map);
peer_con->send_message(m);//发送消息到其他节点
release_map(next_map);
}
int AsyncConnection::send_message(Message *m)
{
FUNCTRACE();
lgeneric_subdout(async_msgr->cct, ms,
1) << "-- " << async_msgr->get_myaddr() << " --> "
<< get_peer_addr() << " -- "
<< *m << " -- " << m << " con "
<< m->get_connection().get()
<< dendl;
// optimistic think it's ok to encode(actually may broken now)
if (!m->get_priority())
m->set_priority(async_msgr->get_default_send_priority());
m->get_header().src = async_msgr->get_myname();
m->set_connection(this);
if (m->get_type() == CEPH_MSG_OSD_OP)
OID_EVENT_TRACE_WITH_MSG(m, "SEND_MSG_OSD_OP_BEGIN", true);
else if (m->get_type() == CEPH_MSG_OSD_OPREPLY)
OID_EVENT_TRACE_WITH_MSG(m, "SEND_MSG_OSD_OPREPLY_BEGIN", true);
if (async_msgr->get_myaddr() == get_peer_addr()) { //loopback connection
ldout(async_msgr->cct, 20) << __func__ << " " << *m << " local" << dendl;
std::lock_guard<std::mutex> l(write_lock);
if (can_write != WriteStatus::CLOSED) {
dispatch_queue->local_delivery(m, m->get_priority());
} else {
ldout(async_msgr->cct, 10) << __func__ << " loopback connection closed."
<< " Drop message " << m << dendl;
m->put();
}
return 0;
}
last_active = ceph::coarse_mono_clock::now();
// we don't want to consider local message here, it's too lightweight which
// may disturb users
logger->inc(l_msgr_send_messages);
bufferlist bl;
uint64_t f = get_features();
// TODO: Currently not all messages supports reencode like MOSDMap, so here
// only let fast dispatch support messages prepare message
bool can_fast_prepare = async_msgr->ms_can_fast_dispatch(m);
if (can_fast_prepare)
prepare_send_message(f, m, bl);
std::lock_guard<std::mutex> l(write_lock);
// "features" changes will change the payload encoding
if (can_fast_prepare && (can_write == WriteStatus::NOWRITE || get_features() != f)) {
// ensure the correctness of message encoding
bl.clear();
m->get_payload().clear();
ldout(async_msgr->cct, 5) << __func__ << " clear encoded buffer previous "
<< f << " != " << get_features() << dendl;
}
if (can_write == WriteStatus::CLOSED) {
ldout(async_msgr->cct, 10) << __func__ << " connection closed."
<< " Drop message " << m << dendl;
m->put();
} else {
m->trace.event("async enqueueing message");
out_q[m->get_priority()].emplace_back(std::move(bl), m);
ldout(async_msgr->cct, 15) << __func__ << " inline write is denied, reschedule m=" << m << dendl;
if (can_write != WriteStatus::REPLACING)
center->dispatch_event_external(write_handler);
}
return 0;
}
AsyncConnection::AsyncConnection(CephContext *cct, AsyncMessenger *m, DispatchQueue *q,
Worker *w)
{
read_handler = new C_handle_read(this);
write_handler = new C_handle_write(this);
}
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
explicit C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(int fd_or_id) override {
conn->process();// 调用
}
};
class C_handle_write : public EventCallback {
AsyncConnectionRef conn;
public:
explicit C_handle_write(AsyncConnectionRef c): conn(c) {}
void do_request(int fd) override {
conn->handle_write();// 调用
}
};
void AsyncConnection::handle_write()
{
ldout(async_msgr->cct, 10) << __func__ << dendl;
ssize_t r = 0;
write_lock.lock();
if (can_write == WriteStatus::CANWRITE) {
if (keepalive) {
_append_keepalive_or_ack();
keepalive = false;
}
auto start = ceph::mono_clock::now();
bool more;
do {
bufferlist data;
Message *m = _get_next_outgoing(&data);
if (!m)
break;
if (!policy.lossy) {
// put on sent list
sent.push_back(m);
m->get();
}
more = _has_next_outgoing();
write_lock.unlock();
// send_message or requeue messages may not encode message
if (!data.length())
prepare_send_message(get_features(), m, data);
r = write_message(m, data, more);
if (r < 0) {
ldout(async_msgr->cct, 1) << __func__ << " send msg failed" << dendl;
goto fail;
}
write_lock.lock();
if (r > 0)
break;
} while (can_write == WriteStatus::CANWRITE);
write_lock.unlock();
uint64_t left = ack_left;
if (left) {
ceph_le64 s;
s = in_seq;
outcoming_bl.append(CEPH_MSGR_TAG_ACK);
outcoming_bl.append((char*)&s, sizeof(s));
ldout(async_msgr->cct, 10) << __func__ << " try send msg ack, acked " << left << " messages" << dendl;
ack_left -= left;
left = ack_left;
r = _try_send(left);
} else if (is_queued()) {
r = _try_send();
}
logger->tinc(l_msgr_running_send_time, ceph::mono_clock::now() - start);
if (r < 0) {
ldout(async_msgr->cct, 1) << __func__ << " send msg failed" << dendl;
goto fail;
}
} else {
write_lock.unlock();
lock.lock();
write_lock.lock();
if (state == STATE_STANDBY && !policy.server && is_queued()) {
ldout(async_msgr->cct, 10) << __func__ << " policy.server is false" << dendl;
_connect();
} else if (cs && state != STATE_NONE && state != STATE_CONNECTING && state != STATE_CONNECTING_RE && state != STATE_CLOSED) {
r = _try_send();// 发送消息
if (r < 0) {
ldout(async_msgr->cct, 1) << __func__ << " send outcoming bl failed" << dendl;
write_lock.unlock();
fault();
lock.unlock();
return ;
}
}
write_lock.unlock();
lock.unlock();
}
return ;
fail:
lock.lock();
fault();
lock.unlock();
}
void AsyncConnection::process()
{
......
do {
......
prev_state = state;
switch (state) {
......
case STATE_OPEN_MESSAGE_READ_FOOTER_AND_DISPATCH:
{
Message *message = decode_message(async_msgr->cct, async_msgr->crcflags, current_header, footer,
front, middle, data, this);
if (delay_state) {
utime_t release = message->get_recv_stamp();
double delay_period = 0;
if (rand() % 10000 < async_msgr->cct->_conf->ms_inject_delay_probability * 10000.0) {
delay_period = async_msgr->cct->_conf->ms_inject_delay_max * (double)(rand() % 10000) / 10000.0;
release += delay_period;
ldout(async_msgr->cct, 1) << "queue_received will delay until " << release << " on "
<< message << " " << *message << dendl;
}
delay_state->queue(delay_period, release, message);
} else if (async_msgr->ms_can_fast_dispatch(message)) {
lock.unlock();
dispatch_queue->fast_dispatch(message);
recv_start_time = ceph::mono_clock::now();
logger->tinc(l_msgr_running_fast_dispatch_time,
recv_start_time - fast_dispatch_time);
lock.lock();
} else {
dispatch_queue->enqueue(message, message->get_priority(), conn_id);
}
......
} while (prev_state != state);
}
void DispatchQueue::fast_dispatch(Message *m)
{
uint64_t msize = pre_dispatch(m);
msgr->ms_fast_dispatch(m);
post_dispatch(m, msize);
}
void OSD::ms_fast_dispatch(Message *m)
{
FUNCTRACE();
if (service.is_stopping()) {
m->put();
return;
}
OpRequestRef op = op_tracker.create_request<OpRequest, Message*>(m);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(osd, ms_fast_dispatch, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
if (m->trace)
op->osd_trace.init("osd op", &trace_endpoint, &m->trace);
// note sender epoch, min req'd epoch
op->sent_epoch = static_cast<MOSDFastDispatchOp*>(m)->get_map_epoch();
op->min_epoch = static_cast<MOSDFastDispatchOp*>(m)->get_min_epoch();
assert(op->min_epoch <= op->sent_epoch); // sanity check!
service.maybe_inject_dispatch_delay();
if (m->get_connection()->has_features(CEPH_FEATUREMASK_RESEND_ON_SPLIT) ||
m->get_type() != CEPH_MSG_OSD_OP) {
// queue it directly
enqueue_op(
static_cast<MOSDFastDispatchOp*>(m)->get_spg(),
op,
static_cast<MOSDFastDispatchOp*>(m)->get_map_epoch());//入队
} else {
// legacy client, and this is an MOSDOp (the *only* fast dispatch
// message that didn't have an explicit spg_t); we need to map
// them to an spg_t while preserving delivery order.
// 这里是兼容老版本,新版本中应该走的上边分支
Session *session = static_cast<Session*>(m->get_connection()->get_priv());
if (session) {
{
Mutex::Locker l(session->session_dispatch_lock);
op->get();
session->waiting_on_map.push_back(*op);
OSDMapRef nextmap = service.get_nextmap_reserved();
dispatch_session_waiting(session, nextmap);
service.release_map(nextmap);
}
session->put();
}
}
OID_EVENT_TRACE_WITH_MSG(m, "MS_FAST_DISPATCH_END", false);
}
void OSD::enqueue_op(spg_t pg, OpRequestRef& op, epoch_t epoch)
{
utime_t latency = ceph_clock_now() - op->get_req()->get_recv_stamp();
dout(15) << "enqueue_op " << op << " prio " << op->get_req()->get_priority()
<< " cost " << op->get_req()->get_cost()
<< " latency " << latency
<< " epoch " << epoch
<< " " << *(op->get_req()) << dendl;
op->osd_trace.event("enqueue op");
op->osd_trace.keyval("priority", op->get_req()->get_priority());
op->osd_trace.keyval("cost", op->get_req()->get_cost());
op->mark_queued_for_pg();
logger->tinc(l_osd_op_before_queue_op_lat, latency);
op_shardedwq.queue(make_pair(pg, PGQueueable(op, epoch)));
}
//scrub 资源预约走这里
void PGQueueable::RunVis::operator()(const OpRequestRef &op) {
osd->dequeue_op(pg, op, handle);
}
void PGQueueable::RunVis::operator()(const PGScrub &op) {
pg->scrub(op.epoch_queued, handle);
}
void OSD::dequeue_op(
PGRef pg, OpRequestRef op,
ThreadPool::TPHandle &handle)
{
FUNCTRACE();
OID_EVENT_TRACE_WITH_MSG(op->get_req(), "DEQUEUE_OP_BEGIN", false);
utime_t now = ceph_clock_now();
op->set_dequeued_time(now);
utime_t latency = now - op->get_req()->get_recv_stamp();
dout(10) << "dequeue_op " << op << " prio " << op->get_req()->get_priority()
<< " cost " << op->get_req()->get_cost()
<< " latency " << latency
<< " " << *(op->get_req())
<< " pg " << *pg << dendl;
logger->tinc(l_osd_op_before_dequeue_op_lat, latency);
Session *session = static_cast<Session *>(
op->get_req()->get_connection()->get_priv());
if (session) {
maybe_share_map(session, op, pg->get_osdmap());
session->put();
}
if (pg->deleting)
return;
op->mark_reached_pg();
op->osd_trace.event("dequeue_op");
pg->do_request(op, handle);//go void PrimaryLogPG::do_request()
// finish
dout(10) << "dequeue_op " << op << " finish" << dendl;
OID_EVENT_TRACE_WITH_MSG(op->get_req(), "DEQUEUE_OP_END", false);
}
void PrimaryLogPG::do_request(
OpRequestRef& op,
ThreadPool::TPHandle &handle)
{
......
switch (op->get_req()->get_type()) {
......
case MSG_OSD_SCRUB_RESERVE:
{
const MOSDScrubReserve *m =
static_cast<const MOSDScrubReserve*>(op->get_req());
switch (m->type) {
case MOSDScrubReserve::REQUEST:
handle_scrub_reserve_request(op);//处理资源预约请求
break;
case MOSDScrubReserve::GRANT:
handle_scrub_reserve_grant(op, m->from);//处理资源预约请求
break;
case MOSDScrubReserve::REJECT:
handle_scrub_reserve_reject(op, m->from);
break;
case MOSDScrubReserve::RELEASE:
handle_scrub_reserve_release(op);
break;
}
}
break;
......
}
}
void PG::handle_scrub_reserve_request(OpRequestRef op)
{
dout(7) << __func__ << " " << *op->get_req() << dendl;
op->mark_started();
if (scrubber.reserved) {
dout(10) << __func__ << " ignoring reserve request: Already reserved"
<< dendl;
return;
}
if ((cct->_conf->osd_scrub_during_recovery || !osd->is_recovery_active()) &&
osd->inc_scrubs_pending()) {
scrubber.reserved = true;
} else {
dout(20) << __func__ << ": failed to reserve remotely" << dendl;
scrubber.reserved = false;
}
if (op->get_req()->get_type() == MSG_OSD_SCRUB_RESERVE) {
const MOSDScrubReserve *m =
static_cast<const MOSDScrubReserve*>(op->get_req());
Message *reply = new MOSDScrubReserve(
spg_t(info.pgid.pgid, primary.shard),
m->map_epoch,
scrubber.reserved ? MOSDScrubReserve::GRANT : MOSDScrubReserve::REJECT,
pg_whoami);// 这里scrub请求转换为GRANT类型。中间如果处理失败,转换为REJECT类型
osd->send_message_osd_cluster(reply, op->get_req()->get_connection());
} else {
// for jewel compat only
const MOSDSubOp *req = static_cast<const MOSDSubOp*>(op->get_req());
assert(req->get_type() == MSG_OSD_SUBOP);
MOSDSubOpReply *reply = new MOSDSubOpReply(
req, pg_whoami, 0, get_osdmap()->get_epoch(), CEPH_OSD_FLAG_ACK);
::encode(scrubber.reserved, reply->get_data());
osd->send_message_osd_cluster(reply, op->get_req()->get_connection());
}
}
void PG::handle_scrub_reserve_grant(OpRequestRef op, pg_shard_t from)
{
dout(7) << __func__ << " " << *op->get_req() << dendl;
op->mark_started();
if (!scrubber.reserved) {
dout(10) << "ignoring obsolete scrub reserve reply" << dendl;
return;
}
if (scrubber.reserved_peers.find(from) != scrubber.reserved_peers.end()) {
dout(10) << " already had osd." << from << " reserved" << dendl;
} else {
dout(10) << " osd." << from << " scrub reserve = success" << dendl;
scrubber.reserved_peers.insert(from);
sched_scrub();//本osd scrub资源预约成功,返回调用 PG::sched_scrub()
}
}2. scrub的实现
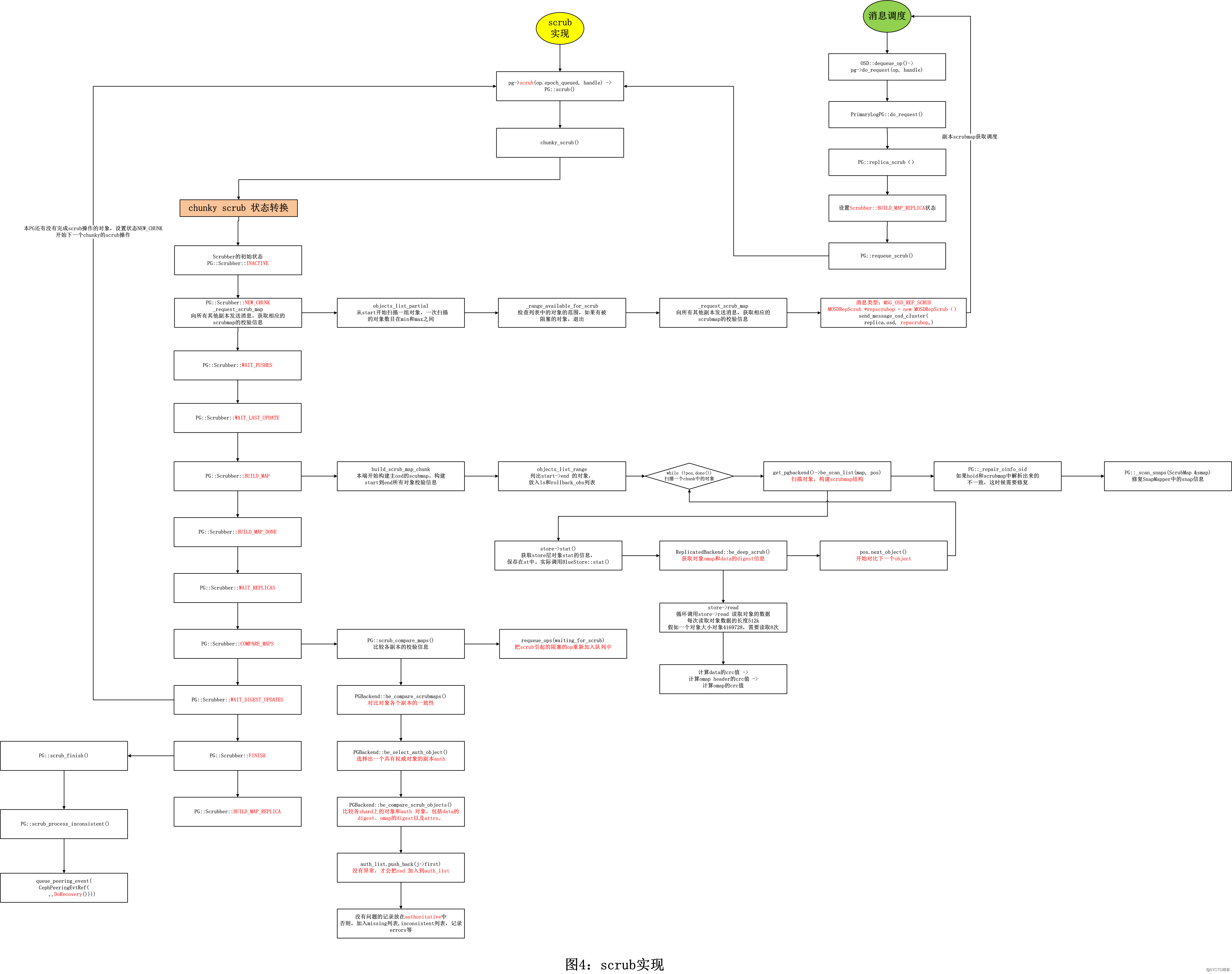
scrub的具体执行过程大致如下,通过对比对象各个OSD副本的元数据和数据来完成元数据和数据的校验。其核心处理流程在函数PG::chunky_scrub 中控制完成。
图4:scrub的实现
2.1 相关数据结构
scrub操作主要2个数据结构,一个是Scrubber,相当于一次scrub操作的上下文,控制一次PG的操作过程。另一个是ScrubMap保存需要比较对象的元数据和数据的摘要信息。
2.1.1 Scrubber
struct Scrubber {//用来控制一个pg的scrub过程
// metadata
set<pg_shard_t> reserved_peers;//资源预约的shard set
bool reserved, reserve_failed;//是否预约,预约是否失败
epoch_t epoch_start;// 开始scrub操作的epoch
// common to both scrubs
bool active;//scrub 是否开始
set<pg_shard_t> waiting_on_whom;//等待的副本
int shallow_errors;//轻度扫描错误数
int deep_errors;//深度扫描错误数
int large_omap_objects = 0;
int fixed;//已经修复对象数
ScrubMap primary_scrubmap;//主副本的scrubmap
ScrubMapBuilder primary_scrubmap_pos;
epoch_t replica_scrub_start = 0;
ScrubMap replica_scrubmap;
ScrubMapBuilder replica_scrubmap_pos;
map<pg_shard_t, ScrubMap> received_maps;//接收到从副本的scrubmap
OpRequestRef active_rep_scrub;
utime_t scrub_reg_stamp; // stamp we registered for
// For async sleep
bool sleeping = false;
bool needs_sleep = true;
utime_t sleep_start;
// flags to indicate explicitly requested scrubs (by admin)
bool must_scrub, must_deep_scrub, must_repair;
// Priority to use for scrub scheduling
unsigned priority;
// this flag indicates whether we would like to do auto-repair of the PG or not
bool auto_repair;//是否自动修复
// Maps from objects with errors to missing/inconsistent peers
map<hobject_t, set<pg_shard_t>> missing;// 扫描出的缺失对象
map<hobject_t, set<pg_shard_t>> inconsistent;// 扫描数的不一致对象
// Map from object with errors to good peers
map<hobject_t, list<pair<ScrubMap::object, pg_shard_t> >> authoritative;//如果所有副本对象中有不一致的对象,authoritative记录了正确对象所在的osd
// digest updates which we are waiting on
int num_digest_updates_pending;// 等待更新digest的对象数目
// chunky scrub
hobject_t start, end; // [start,end) 扫描对象列表的开始和结尾
hobject_t max_end; // Largest end that may have been sent to replicas
eversion_t subset_last_update;//扫描对象列表中最新的版本号
// chunky scrub state
enum State {
INACTIVE,
NEW_CHUNK,
WAIT_PUSHES,
WAIT_LAST_UPDATE,
BUILD_MAP,
BUILD_MAP_DONE,
WAIT_REPLICAS,
COMPARE_MAPS,
WAIT_DIGEST_UPDATES,
FINISH,
BUILD_MAP_REPLICA,
} state;
std::unique_ptr<Scrub::Store> store;
// deep scrub
bool deep;// 是否为深度扫描
int preempt_left;
int preempt_divisor;
} scrubber2.1.2 Scrubmap
保存准备校验的对象及相应的校验信息。
/*
* summarize pg contents for purposes of a scrub
*/
struct ScrubMap {// 保存准备校验的对象以及相应的校验信息
struct object {
map<string,bufferptr> attrs;//对象的属性
uint64_t size;//对象大小
__u32 omap_digest; ///< omap crc32c
__u32 digest; ///< data crc32c
bool negative:1;
bool digest_present:1;//是否校验了数据的校验码标志
bool omap_digest_present:1;// 是否有omap的校验码标志
bool read_error:1;//读对象数据出错标志
bool stat_error:1;//调用stat获取对象元数据出错标志
bool ec_hash_mismatch:1;
bool ec_size_mismatch:1;
bool large_omap_object_found:1;
uint64_t large_omap_object_key_count = 0;
uint64_t large_omap_object_value_size = 0;
object() :
// Init invalid size so it won't match if we get a stat EIO error
size(-1), omap_digest(0), digest(0),
negative(false), digest_present(false), omap_digest_present(false),
read_error(false), stat_error(false), ec_hash_mismatch(false),
ec_size_mismatch(false), large_omap_object_found(false) {}
void encode(bufferlist& bl) const;
void decode(bufferlist::iterator& bl);
void dump(Formatter *f) const;
static void generate_test_instances(list<object*>& o);
};
WRITE_CLASS_ENCODER(object)
map<hobject_t,object> objects;// 需要校验的对象 -> 对象的校验信息映射
eversion_t valid_through;
eversion_t incr_since;
bool has_large_omap_object_errors:1;
boost::optional<bool> has_builtin_csum;
}2.2 Scrub的控制流程
scrub 的任务是由OSD的工作队列OpWq来完成,调用对应的pg->scrub(handle)来执行。
PG::scrub 函数最终调用 PG::chunky_scrub() 函数来实现,该函数控制了scrub操作的状态转换和核心处理流程。
//PG::requeue_scrub() -> queue_for_scrub() ->PGQueueable::RunVis::operator() ->pg->scrub(op.epoch_queued, handle)
void PG::scrub(epoch_t queued, ThreadPool::TPHandle &handle)
{
......
assert(scrub_queued);
scrub_queued = false;
scrubber.needs_sleep = true;
// for the replica
if (!is_primary() &&
scrubber.state == PG::Scrubber::BUILD_MAP_REPLICA) {
chunky_scrub(handle);// 副本处理state:BUILD_MAP_REPLICA
return;
}
//如果本osd 非主,非active,非clean,非scrubbing,满足之一,就不进行scrub
if (!is_primary() || !is_active() || !is_clean() || !is_scrubbing()) {
dout(10) << "scrub -- not primary or active or not clean" << dendl;
state_clear(PG_STATE_SCRUBBING);
state_clear(PG_STATE_REPAIR);
state_clear(PG_STATE_DEEP_SCRUB);
publish_stats_to_osd();
return;
}
if (!scrubber.active) {
assert(backfill_targets.empty());
scrubber.deep = state_test(PG_STATE_DEEP_SCRUB);
dout(10) << "starting a new chunky scrub" << dendl;
}
chunky_scrub(handle);// 开始处理scrub主流程
}2.2.1 chunky_scrub()
- 1.开始了scrub,但是epoch_start != same_interval_since,直接退出
- 2.Scrubber的初始状态为 PG::Scrubber::INACTIVE。处理如下:
-
- 设置scrubber.epoch_start 值为info.history.same_interval_since。
-
- 设置scrubber.active 为true
-
- 设置scrubber.state状态为 PG::Scrubber::NEW_CHUNK
- 3.PG::Scrubber::NEW_CHUNK状态处理如下:
-
- 调用函数objects_list_partial 从start开始扫描一组对象,一次扫描的对象数目在min和max之间。这两个值和osd_scrub_chunk_min(5)和osd_scrub_chunk_max(25)有关
-
- 计算出对象的边界。相同的对象具有相同的哈希值。从里边后边开始查找哈希值不同的对象,从该地方为界限。这样做的目的是把一个对象的所有相关对象(快照对象、回滚对象)划分在一次扫描校验过程中。
-
- 函数_range_available_for_scrub,检查列表中的对象的范围,如果有被阻塞的对象,就设置done为true,退出本次PG scrub的过程。
-
- 计算pglog中最新的版本号,设置为scrubber.subset_last_update
-
- 调用_request_scrub_map 向所有其他副本发送消息,获取相应的scrubmap的校验信息
-
- 设置状态为PG::Scrubber::WAIT_PUSHES
- 4.PG::Scrubber::WAIT_PUSHES状态处理:
-
- active_pushes为0,直接进入下一个状态 PG::Scrubber::WAIT_LAST_UPDATE;如果不为0,说明pg正在recovery状态,设置done为true,直接结束。
- 5.PG::Scrubber::WAIT_LAST_UPDATE状态处理如下:
-
- 如果last_update_applied < scrubber.subset_last_update,虽然已经把操作写入日志,但是还没有应用到对象,由于后边scrub有对象的读操作,所以需要等待日志应用完成。这里有对象没有真正写完,所以结束本地scrub。
-
- 设置状态为 PG::Scrubber::BUILD_MAP
- 6.PG::Scrubber::BUILD_MAP状态处理如下
-
- 调用函数build_scrub_map_chunk 本端开始真正构建主osd的scubmap。构建start到end所有对象校验信息,并保存在scrubmap结构中
-
- 设置状态为 PG::Scrubber::BUILD_MAP_DONE
- 7.PG::Scrubber::BUILD_MAP_DONE 处理如下
-
- 设置状态scrubber.state = PG::Scrubber::WAIT_REPLICAS;
- 8.PG::Scrubber::WAIT_REPLICAS 处理如下:
-
- 如果waiting_on_whom不为空,说明有部分osd没有完成scrubmap构建,结束本次scrub请求
- -设置状态为 PG::Scrubber::COMPARE_MAPS
- 9.PG::Scrubber::COMPARE_MAPS状态如下:
-
- 调用函数 scrub_compare_maps 比较各副本的校验信息
-
- 更新参数scrubber.start = scrubber.end
-
- 函数requeue_ops 把scrub引起的阻塞的op重新加入队列中执行 PrimaryLogPG::do_op()-> waiting_for_scrub.push_back(op)
-
- 设置状态为PG::Scrubber::WAIT_DIGEST_UPDATES
- 10.PG::Scrubber::WAIT_DIGEST_UPDATES 状态处理如下:
-
- 如果scrubber.num_digest_updates_pending 存在,等待更新数据的digest或者omap的digest
-
- 如果end不是max,说明本PG还有没有完成scrub操作的对象,设置状态NEW_CHUNK,继续加入requeue_scrub,进行处理。
-
- 否则设置为PG::Scrubber::FINISH
- 11.PG::Scrubber::FINISH状态处理如下:
-- 设置状态为PG::Scrubber::INACTIVE, done = true,完成scrub。 - 12.PG::Scrubber::BUILD_MAP_REPLICA 状态处理如下:
-
- 在步骤3中发送到其他osd副本,其他副本会调用build_scrub_map_chunk 构建scrubmap,然后调用 osd->send_message_osd_cluster(reply) 返回到主OSD。
/*
* Chunky scrub scrubs objects one chunk at a time with writes blocked for that
* chunk.
*
* The object store is partitioned into chunks which end on hash boundaries. For
* each chunk, the following logic is performed:
*
* (1) Block writes on the chunk
* (2) Request maps from replicas
* (3) Wait for pushes to be applied (after recovery)
* (4) Wait for writes to flush on the chunk
* (5) Wait for maps from replicas
* (6) Compare / repair all scrub maps
* (7) Wait for digest updates to apply
*
* This logic is encoded in the mostly linear state machine:
*
* +------------------+
* _________v__________ |
* | | |
* | INACTIVE | |
* |____________________| |
* | |
* | +----------+ |
* _________v___v______ | |
* | | | |
* | NEW_CHUNK | | |
* |____________________| | |
* | | |
* _________v__________ | |
* | | | |
* | WAIT_PUSHES | | |
* |____________________| | |
* | | |
* _________v__________ | |
* | | | |
* | WAIT_LAST_UPDATE | | |
* |____________________| | |
* | | |
* _________v__________ | |
* | | | |
* | BUILD_MAP | | |
* |____________________| | |
* | | |
* _________v__________ | |
* | | | |
* | WAIT_REPLICAS | | |
* |____________________| | |
* | | |
* _________v__________ | |
* | | | |
* | COMPARE_MAPS | | |
* |____________________| | |
* | | |
* | | |
* _________v__________ | |
* | | | |
* |WAIT_DIGEST_UPDATES | | |
* |____________________| | |
* | | | |
* | +----------+ |
* _________v__________ |
* | | |
* | FINISH | |
* |____________________| |
* | |
* +------------------+
*/
void PG::chunky_scrub(ThreadPool::TPHandle &handle)
{
// check for map changes
if (scrubber.is_chunky_scrub_active()) {// return state != INACTIVE; 开始了scrub
if (scrubber.epoch_start != info.history.same_interval_since) {//开始了scrub,但是epoch_start != same_interval_since,直接退出
dout(10) << "scrub pg changed, aborting" << dendl;
scrub_clear_state();
scrub_unreserve_replicas();
return;
}
}
bool done = false;
int ret;
// 这里如果是deepscrub,假如一个对象4169728,那么4169728/524288=7.9 ,需要8次才能把一个对象操作完,然后才会执行下一个object,每次都会从这里开始。
while (!done) {
dout(20) << "scrub state " << Scrubber::state_string(scrubber.state)
<< " [" << scrubber.start << "," << scrubber.end << ")"
<< " max_end " << scrubber.max_end << dendl;
switch (scrubber.state) {
case PG::Scrubber::INACTIVE:
dout(10) << "scrub start" << dendl;
assert(is_primary());
publish_stats_to_osd();
scrubber.epoch_start = info.history.same_interval_since;
scrubber.active = true;
osd->inc_scrubs_active(scrubber.reserved);
if (scrubber.reserved) {
scrubber.reserved = false;
scrubber.reserved_peers.clear();
}
{
ObjectStore::Transaction t;
scrubber.cleanup_store(&t);
scrubber.store.reset(Scrub::Store::create(osd->store, &t,
info.pgid, coll));
osd->store->queue_transaction(osr.get(), std::move(t), nullptr);
}
// Don't include temporary objects when scrubbing
scrubber.start = info.pgid.pgid.get_hobj_start();
scrubber.state = PG::Scrubber::NEW_CHUNK;
{
bool repair = state_test(PG_STATE_REPAIR);
bool deep_scrub = state_test(PG_STATE_DEEP_SCRUB);
const char *mode = (repair ? "repair": (deep_scrub ? "deep-scrub" : "scrub"));
stringstream oss;
oss << info.pgid.pgid << " " << mode << " starts" << std::endl;
osd->clog->debug(oss);
}
scrubber.preempt_left = cct->_conf->get_val<uint64_t>(
"osd_scrub_max_preemptions");
scrubber.preempt_divisor = 1;
break;
case PG::Scrubber::NEW_CHUNK:
scrubber.primary_scrubmap = ScrubMap();
scrubber.received_maps.clear();
// begin (possible) preemption window
if (scrub_preempted) {
scrubber.preempt_left--;
scrubber.preempt_divisor *= 2;
dout(10) << __func__ << " preempted, " << scrubber.preempt_left
<< " left" << dendl;
scrub_preempted = false;
}
scrub_can_preempt = scrubber.preempt_left > 0;
{
int min = std::max<int64_t>(3, cct->_conf->osd_scrub_chunk_min /
scrubber.preempt_divisor);
int max = std::max<int64_t>(min, cct->_conf->osd_scrub_chunk_max /
scrubber.preempt_divisor);
hobject_t start = scrubber.start;
hobject_t candidate_end;
vector<hobject_t> objects;
osr->flush();
ret = get_pgbackend()->objects_list_partial(
start,
min,
max,
&objects,
&candidate_end);
assert(ret >= 0);
if (!objects.empty()) {
hobject_t back = objects.back();
while (candidate_end.has_snapset() &&
candidate_end.get_head() == back.get_head()) {
candidate_end = back;
objects.pop_back();
if (objects.empty()) {
assert(0 ==
"Somehow we got more than 2 objects which"
"have the same head but are not clones");
}
back = objects.back();
}
if (candidate_end.has_snapset()) {
assert(candidate_end.get_head() != back.get_head());
candidate_end = candidate_end.get_object_boundary();
}
} else {
assert(candidate_end.is_max());
}
if (!_range_available_for_scrub(scrubber.start, candidate_end)) {//检查列表中的对象,如果有被阻塞的对象,就退出
// we'll be requeued by whatever made us unavailable for scrub
dout(10) << __func__ << ": scrub blocked somewhere in range "
<< "[" << scrubber.start << ", " << candidate_end << ")"
<< dendl;
done = true;
break;
}
scrubber.end = candidate_end;
if (scrubber.end > scrubber.max_end)
scrubber.max_end = scrubber.end;
}
// walk the log to find the latest update that affects our chunk
scrubber.subset_last_update = eversion_t();
for (auto p = projected_log.log.rbegin();
p != projected_log.log.rend();
++p) {
if (p->soid >= scrubber.start &&
p->soid < scrubber.end) {
scrubber.subset_last_update = p->version;
break;
}
}
if (scrubber.subset_last_update == eversion_t()) {
for (list<pg_log_entry_t>::const_reverse_iterator p =
pg_log.get_log().log.rbegin();
p != pg_log.get_log().log.rend();
++p) {
if (p->soid >= scrubber.start &&
p->soid < scrubber.end) {
scrubber.subset_last_update = p->version;
break;
}
}
}
// ask replicas to wait until
// last_update_applied >= scrubber.subset_last_update and then scan
scrubber.waiting_on_whom.insert(pg_whoami);
// request maps from replicas
for (set<pg_shard_t>::iterator i = actingbackfill.begin();
i != actingbackfill.end();// 向所有副本发送消息,获取相应的scrubmap的校验信息
++i) {
if (*i == pg_whoami) continue;
_request_scrub_map(*i, scrubber.subset_last_update,
scrubber.start, scrubber.end, scrubber.deep,
scrubber.preempt_left > 0);
scrubber.waiting_on_whom.insert(*i);//把所有的等待的副本加入到waiting_on_whom set中
}
dout(10) << __func__ << " waiting_on_whom " << scrubber.waiting_on_whom
<< dendl;
scrubber.state = PG::Scrubber::WAIT_PUSHES;
break;
case PG::Scrubber::WAIT_PUSHES:
if (active_pushes == 0) {
scrubber.state = PG::Scrubber::WAIT_LAST_UPDATE;
} else {
dout(15) << "wait for pushes to apply" << dendl;
done = true;
}
break;
case PG::Scrubber::WAIT_LAST_UPDATE:
if (last_update_applied < scrubber.subset_last_update) {//虽然已经把操作写入日志,但是还没有应用到对象,由于后边scrub有对象的读操作,所以需要等待日志应用完成。这里有对象没有真正写完,所以结束本地scrub。
// will be requeued by op_applied
dout(15) << "wait for writes to flush" << dendl;
done = true;
break;
}
scrubber.state = PG::Scrubber::BUILD_MAP;
scrubber.primary_scrubmap_pos.reset();
break;
case PG::Scrubber::BUILD_MAP:
assert(last_update_applied >= scrubber.subset_last_update);
// build my own scrub map
if (scrub_preempted) {
dout(10) << __func__ << " preempted" << dendl;
scrubber.state = PG::Scrubber::BUILD_MAP_DONE;
break;
}
ret = build_scrub_map_chunk(
scrubber.primary_scrubmap,
scrubber.primary_scrubmap_pos,
scrubber.start, scrubber.end,
scrubber.deep,
handle);// 此处开始真正构建主osd的scubmap。构建start到end所有对象校验信息,并保存在scrubmap结构中
if (ret == -EINPROGRESS) {
requeue_scrub();
done = true;
break;
}
scrubber.state = PG::Scrubber::BUILD_MAP_DONE;
break;
case PG::Scrubber::BUILD_MAP_DONE:
if (scrubber.primary_scrubmap_pos.ret < 0) {
dout(5) << "error: " << scrubber.primary_scrubmap_pos.ret
<< ", aborting" << dendl;
scrub_clear_state();
scrub_unreserve_replicas();
return;
}
dout(10) << __func__ << " waiting_on_whom was "
<< scrubber.waiting_on_whom << dendl;
assert(scrubber.waiting_on_whom.count(pg_whoami));
scrubber.waiting_on_whom.erase(pg_whoami);
scrubber.state = PG::Scrubber::WAIT_REPLICAS;
break;
case PG::Scrubber::WAIT_REPLICAS:
if (!scrubber.waiting_on_whom.empty()) {//如果waiting_on_whom不为空,说明有部分osd没有完成scrubmap构建,结束本次scrub请求
// will be requeued by sub_op_scrub_map
dout(10) << "wait for replicas to build scrub map" << dendl;
done = true;
break;
}
// end (possible) preemption window
scrub_can_preempt = false;
if (scrub_preempted) {
dout(10) << __func__ << " preempted, restarting chunk" << dendl;
scrubber.state = PG::Scrubber::NEW_CHUNK;
} else {
scrubber.state = PG::Scrubber::COMPARE_MAPS;
}
break;
case PG::Scrubber::COMPARE_MAPS:
assert(last_update_applied >= scrubber.subset_last_update);
assert(scrubber.waiting_on_whom.empty());
scrub_compare_maps();//比较各副本的校验信息
scrubber.start = scrubber.end;
scrubber.run_callbacks();
// requeue the writes from the chunk that just finished
requeue_ops(waiting_for_scrub);//把scrub引起的阻塞的op重新加入队列中执行 PrimaryLogPG::do_op()-> waiting_for_scrub.push_back(op)
scrubber.state = PG::Scrubber::WAIT_DIGEST_UPDATES;
// fall-thru
case PG::Scrubber::WAIT_DIGEST_UPDATES:
if (scrubber.num_digest_updates_pending) {// 等待更新数据的digest或者omap的digest
dout(10) << __func__ << " waiting on "
<< scrubber.num_digest_updates_pending
<< " digest updates" << dendl;
done = true;
break;
}
scrubber.preempt_left = cct->_conf->get_val<uint64_t>(
"osd_scrub_max_preemptions");
scrubber.preempt_divisor = 1;
if (!(scrubber.end.is_max())) {// 本PG还有没有完成scrub操作的对象,设置状态NEW_CHUNK,继续加入requeue_scrub,进行处理
scrubber.state = PG::Scrubber::NEW_CHUNK;
requeue_scrub();
done = true;
} else {
scrubber.state = PG::Scrubber::FINISH;
}
break;
case PG::Scrubber::FINISH:
scrub_finish();
scrubber.state = PG::Scrubber::INACTIVE;
done = true;
if (!snap_trimq.empty()) {
dout(10) << "scrub finished, requeuing snap_trimmer" << dendl;
snap_trimmer_scrub_complete();
}
break;
case PG::Scrubber::BUILD_MAP_REPLICA:
// build my own scrub map
if (scrub_preempted) {
dout(10) << __func__ << " preempted" << dendl;
ret = 0;
} else {
ret = build_scrub_map_chunk(
scrubber.replica_scrubmap,
scrubber.replica_scrubmap_pos,
scrubber.start, scrubber.end,
scrubber.deep,
handle);
}
if (ret == -EINPROGRESS) {
requeue_scrub();
done = true;
break;
}
// reply
if (HAVE_FEATURE(acting_features, SERVER_LUMINOUS)) {//L版版
MOSDRepScrubMap *reply = new MOSDRepScrubMap(
spg_t(info.pgid.pgid, get_primary().shard),
scrubber.replica_scrub_start,
pg_whoami);
reply->preempted = scrub_preempted;
::encode(scrubber.replica_scrubmap, reply->get_data());
osd->send_message_osd_cluster(
get_primary().osd, reply,
scrubber.replica_scrub_start);
} else {//J版本
// for jewel compatibility
vector<OSDOp> scrub(1);
scrub[0].op.op = CEPH_OSD_OP_SCRUB_MAP;
hobject_t poid;
eversion_t v;
osd_reqid_t reqid;
MOSDSubOp *subop = new MOSDSubOp(
reqid,
pg_whoami,
spg_t(info.pgid.pgid, get_primary().shard),
poid,
0,
scrubber.replica_scrub_start,
osd->get_tid(),
v);
::encode(scrubber.replica_scrubmap, subop->get_data());
subop->ops = scrub;
osd->send_message_osd_cluster(
get_primary().osd, subop,
scrubber.replica_scrub_start);
}
scrub_preempted = false;
scrub_can_preempt = false;
scrubber.state = PG::Scrubber::INACTIVE;
scrubber.replica_scrubmap = ScrubMap();
scrubber.replica_scrubmap_pos = ScrubMapBuilder();
scrubber.start = hobject_t();
scrubber.end = hobject_t();
scrubber.max_end = hobject_t();
done = true;
break;
default:
ceph_abort();
}
}
dout(20) << "scrub final state " << Scrubber::state_string(scrubber.state)
<< " [" << scrubber.start << "," << scrubber.end << ")"
<< " max_end " << scrubber.max_end << dendl;
} 2.3 构建Scrubmap
2.3.1 build_scrub_map_chunk
构建start到end所有对象校验信息,并保存在scrubmap结构中。在函数chunky_scrub中主/从OSD都会调用该函数进行Scrubmap的构建。
- 1.调用get_pgbackend()->objects_list_range列出start->end 的对象,放入ls和rollback_obs列表, ls 用来存放head和snap对象(默认),rollback_obs存放用来回滚的对象
- 2.调用函数get_pgbackend()->be_scan_list(map, pos),扫描对象,构建scrubmap结构。
- 3.当一组[start,end]构建完毕,这里会调用PG::_repair_oinfo_oid,如果hoid和scrubmap中解析出来的不一致,这时候需要修复,以scrubmap中解析出的hoid为准,修复oi(o.attrs)中的soid。
- 4.调用_scan_snaps修复SnapMapper中的snap信息。
//构建start到end所有对象校验信息,并保存在scrubmap结构中
int PG::build_scrub_map_chunk(
ScrubMap &map,
ScrubMapBuilder &pos,
hobject_t start,
hobject_t end,
bool deep,
ThreadPool::TPHandle &handle)
{
dout(10) << __func__ << " [" << start << "," << end << ") "
<< " pos " << pos
<< dendl;
//build_scrub_map_chunk [2:60000000::::head,2:7341ac06:::rbd_data.6ed5b6b8b4567.00000000000000c5:0) pos (2/24 2:61948a30:::rbd_data.6ed5b6b8b4567.000000000000006d:head deep)
// start
while (pos.empty()) {//初始状态pos.empty()为空
pos.deep = deep;
map.valid_through = info.last_update;
osr->flush();
// objects
vector<ghobject_t> rollback_obs;
pos.ret = get_pgbackend()->objects_list_range(
start,
end,
0,
&pos.ls,
&rollback_obs);//列出范围内的对象, ls 用来存放head和snap对象,rollback_obs存放用来回滚的对象
if (pos.ret < 0) {
dout(5) << "objects_list_range error: " << pos.ret << dendl;
return pos.ret;
}
if (pos.ls.empty()) {
break;
}
_scan_rollback_obs(rollback_obs, handle);
pos.pos = 0;
return -EINPROGRESS;
}
// scan objects
while (!pos.done()) {
int r = get_pgbackend()->be_scan_list(map, pos);//扫描对象,构建scrubmap结构
if (r == -EINPROGRESS) {
return r;
}
}
// finish
dout(20) << __func__ << " finishing" << dendl;
assert(pos.done());
_repair_oinfo_oid(map);
if (!is_primary()) {
ScrubMap for_meta_scrub;
// In case we restarted smaller chunk, clear old data
scrubber.cleaned_meta_map.clear_from(scrubber.start);
scrubber.cleaned_meta_map.insert(map);
scrubber.clean_meta_map(for_meta_scrub);
_scan_snaps(for_meta_scrub);
}
dout(20) << __func__ << " done, got " << map.objects.size() << " items"
<< dendl;
return 0;
}2.3.2 PGBackend::be_scan_list
用于构建scrubmap中对象的校验信息。
- 1.调用store->stat 获取store层对象stat的信息,保存在st中。实际调用BlueStore::stat()
- 2.设置o.size 的值为 st.st_size,并调用store->getattrs 把对象的attr信息保存在o.attrs中。
- 3.如果deep为true,调用函数be_deep_scrub,获取对象omap和data的digest信息。
- 注:这里构建scrubmap,如果是scrub,对比的只有size和attrs信息,如果是deep-scrub,对比的多了omap和data的信息;
-
4.开始对比下一个object
int PGBackend::be_scan_list( ScrubMap &map, ScrubMapBuilder &pos) { dout(10) << __func__ << " " << pos << dendl; //be_scan_list (4/24 2:625a7837:::rbd_data.6ed5b6b8b4567.000000000000001c:head) assert(!pos.done()); assert(pos.pos < pos.ls.size()); hobject_t& poid = pos.ls[pos.pos]; struct stat st; int r = store->stat( ch, ghobject_t( poid, ghobject_t::NO_GEN, get_parent()->whoami_shard().shard), &st, true);//BlueStore::stat if (r == 0) { ScrubMap::object &o = map.objects[poid];//这里是引用语法,构建scrubmap,如果是scrub,对比的只有size和attrs信息,如果是deep-scrub,对比的多了omap和data的信息; o.size = st.st_size; assert(!o.negative); store->getattrs( ch, ghobject_t( poid, ghobject_t::NO_GEN, get_parent()->whoami_shard().shard), o.attrs); dout(10) << __func__ << " wds-1: o.size:" << o.size << ", o.attrs:" << o.attrs << dendl; if (pos.deep) { r = be_deep_scrub(poid, map, pos, o);// 这里对比omap和data的信息 } dout(25) << __func__ << " " << poid << dendl; dout(10) << __func__ << " wds-3: o.size:" << o.size << ", o.attrs:" << o.attrs << dendl; } else if (r == -ENOENT) { dout(25) << __func__ << " " << poid << " got " << r << ", skipping" << dendl; } else if (r == -EIO) { dout(25) << __func__ << " " << poid << " got " << r << ", stat_error" << dendl; ScrubMap::object &o = map.objects[poid]; o.stat_error = true; } else { derr << __func__ << " got: " << cpp_strerror(r) << dendl; ceph_abort(); } if (r == -EINPROGRESS) {//代表连接还在进行中,如果object读了一部分,还没有读完,be_deep_scrub返回该值,就直接返回到上层,不会继续执行pos.next_object() return -EINPROGRESS; } pos.next_object();// 一个object彻底读完了,才开始下一个object return 0; }2.3.3 ReplicatedBackend::be_deep_scrub
- 1.循环调用store->read 读取对象的数据,每次读取对象数据的长度为cct->_conf->osd_deep_scrub_stride/512k/。
- 2.这里是逐个对象进行data_hash值的,每次读取对象的512K字节,假如一个对象4169728,那么4169728/524288=7.9 ,需要8次 ‘more data, digest so far’ 之后才会出现‘done with data, digest 0x’,接着开始下一个object。
- 3.计算data的crc值
- 4.计算omap header的crc值
- 5.计算omap的crc值
int ReplicatedBackend::be_deep_scrub(
const hobject_t &poid,
ScrubMap &map,
ScrubMapBuilder &pos,
ScrubMap::object &o)
{
dout(10) << __func__ << " " << poid << " pos " << pos << dendl;
int r;
uint32_t fadvise_flags = CEPH_OSD_OP_FLAG_FADVISE_SEQUENTIAL |
CEPH_OSD_OP_FLAG_FADVISE_DONTNEED |
CEPH_OSD_OP_FLAG_BYPASS_CLEAN_CACHE;
utime_t sleeptime;
sleeptime.set_from_double(cct->_conf->osd_debug_deep_scrub_sleep);//osd_debug_deep_scrub_sleep=0
if (sleeptime != utime_t()) {
lgeneric_derr(cct) << __func__ << " sleeping for " << sleeptime << dendl;
sleeptime.sleep();
}
assert(poid == pos.ls[pos.pos]);
//这里是逐个对象进行data_hash值的,每次读取对象的512K字节,假如一个对象4169728,那么4169728/524288=7.9 ,需要8次 ‘more data, digest so far’ 之后才会出现‘done with data, digest 0x’,接着开始下一个object。
if (!pos.data_done()) {
if (pos.data_pos == 0) {
pos.data_hash = bufferhash(-1);
}
bufferlist bl;
r = store->read(
ch,
ghobject_t(
poid, ghobject_t::NO_GEN, get_parent()->whoami_shard().shard),
pos.data_pos,
cct->_conf->osd_deep_scrub_stride/*512k*/, bl,
fadvise_flags);
if (r < 0) {
dout(20) << __func__ << " " << poid << " got "
<< r << " on read, read_error" << dendl;
o.read_error = true;
return 0;
}
if (r > 0) {
pos.data_hash << bl;
}
pos.data_pos += r;
if (r == cct->_conf->osd_deep_scrub_stride) {
dout(20) << __func__ << " " << poid << " more data, digest so far 0x"
<< std::hex << pos.data_hash.digest() << std::dec << dendl;
return -EINPROGRESS;
}
// done with bytes
pos.data_pos = -1;
o.digest = pos.data_hash.digest();//计算data的crc值
o.digest_present = true;
dout(20) << __func__ << " " << poid << " done with data, digest 0x"
<< std::hex << o.digest << std::dec << dendl;
}
// omap header
if (pos.omap_pos.empty()) {
pos.omap_hash = bufferhash(-1);
bufferlist hdrbl;
r = store->omap_get_header(
coll,
ghobject_t(
poid, ghobject_t::NO_GEN, get_parent()->whoami_shard().shard),
&hdrbl, true);
if (r == -EIO) {
dout(20) << __func__ << " " << poid << " got "
<< r << " on omap header read, read_error" << dendl;
o.read_error = true;
return 0;
}
if (r == 0 && hdrbl.length()) {
dout(25) << "CRC header " << string(hdrbl.c_str(), hdrbl.length())
<< dendl;
pos.omap_hash << hdrbl;//计算omap header的crc值
}
}
// omap
ObjectMap::ObjectMapIterator iter = store->get_omap_iterator(
coll,
ghobject_t(
poid, ghobject_t::NO_GEN, get_parent()->whoami_shard().shard));
assert(iter);
if (pos.omap_pos.length()) {
iter->lower_bound(pos.omap_pos);
} else {
iter->seek_to_first();
}
int max = g_conf->osd_deep_scrub_keys;//1024
while (iter->status() == 0 && iter->valid()) {
pos.omap_bytes += iter->value().length();
++pos.omap_keys;
--max;
// fixme: we can do this more efficiently.
bufferlist bl;
::encode(iter->key(), bl);
::encode(iter->value(), bl);
pos.omap_hash << bl;
iter->next();
if (iter->valid() && max == 0) {
pos.omap_pos = iter->key();
return -EINPROGRESS;
}
if (iter->status() < 0) {
dout(25) << __func__ << " " << poid
<< " on omap scan, db status error" << dendl;
o.read_error = true;
return 0;
}
}
if (pos.omap_keys > cct->_conf->
osd_deep_scrub_large_omap_object_key_threshold/*2000000*/ ||
pos.omap_bytes > cct->_conf->
osd_deep_scrub_large_omap_object_value_sum_threshold/*1G*/) {
dout(25) << __func__ << " " << poid
<< " large omap object detected. Object has " << pos.omap_keys
<< " keys and size " << pos.omap_bytes << " bytes" << dendl;
o.large_omap_object_found = true;
o.large_omap_object_key_count = pos.omap_keys;
o.large_omap_object_value_size = pos.omap_bytes;
map.has_large_omap_object_errors = true;
}
o.omap_digest = pos.omap_hash.digest();//计算omap的crc值
o.omap_digest_present = true;
dout(20) << __func__ << " done with " << poid << " omap_digest "
<< std::hex << o.omap_digest << std::dec << dendl;
// done!
return 0;
}2.4 从副本处理,构建scrubmap
2.3中主副本PG::chunky_scrub中发送MOSDRepScrub消息,类型为MSG_OSD_REP_SCRUB到其他副本获取scrubmap。
从副本接收到主副本发送过来的MOSDRepScrub消息,通过PrimaryLogPG::do_request,处理类型为MSG_OSD_REP_SCRUB,开始获取从副本上的scrubmap信息,调用函数PG::replica_scrub完成。
- 1.断定没有正在scrub的操作
- 2.确保过来的scrub消息不是过时的
- 3.如果副本上完成日志应用的操作落后于主副本scrub的操作版本,必须等待他们保持一致,等待
- 4.如果recovery操作正在进行,等待
- 5.设置Scrubber::BUILD_MAP_REPLICA状态。
- 6.调用函数requeue_scrub,放入本副本osd的队列,PG::scrub -> if (!is_primary() && scrubber.state == PG::Scrubber::BUILD_MAP_REPLICA) {chunky_scrub(handle)}->case PG::Scrubber::WAIT_REPLICAS,接着执行副本上的build_scrub_map_chunk。
/* replica_scrub
*
* Wait for last_update_applied to match msg->scrub_to as above. Wait
* for pushes to complete in case of recent recovery. Build a single
* scrubmap of objects that are in the range [msg->start, msg->end).
*/
void PG::replica_scrub(
OpRequestRef op,
ThreadPool::TPHandle &handle)
{
const MOSDRepScrub *msg = static_cast<const MOSDRepScrub *>(op->get_req());
assert(!scrubber.active_rep_scrub);//断定没有正在scrub的操作
dout(7) << "replica_scrub" << dendl;
if (msg->map_epoch < info.history.same_interval_since) {// 说明过来的scrub是过时的
dout(10) << "replica_scrub discarding old replica_scrub from "
<< msg->map_epoch << " < " << info.history.same_interval_since
<< dendl;
return;
}
assert(msg->chunky);
if (last_update_applied < msg->scrub_to) {//副本上完成日志应用的操作落后于主副本scrub的操作版本,必须等待他们保持一致,等待
dout(10) << "waiting for last_update_applied to catch up" << dendl;
scrubber.active_rep_scrub = op;
return;
}
if (active_pushes > 0) {//recovery操作正在进行,等待
dout(10) << "waiting for active pushes to finish" << dendl;
scrubber.active_rep_scrub = op;
return;
}
scrubber.state = Scrubber::BUILD_MAP_REPLICA;
scrubber.replica_scrub_start = msg->min_epoch;
scrubber.start = msg->start;
scrubber.end = msg->end;
scrubber.max_end = msg->end;
scrubber.deep = msg->deep;
scrubber.epoch_start = info.history.same_interval_since;
if (msg->priority) {
scrubber.priority = msg->priority;
} else {
scrubber.priority = get_scrub_priority();
}
scrub_can_preempt = msg->allow_preemption;
scrub_preempted = false;
scrubber.replica_scrubmap_pos.reset();
requeue_scrub(msg->high_priority);// 这里会放入队列,PG::scrub -> if (!is_primary() && scrubber.state == PG::Scrubber::BUILD_MAP_REPLICA) {chunky_scrub(handle)}->case PG::Scrubber::WAIT_REPLICAS,接着执行副本上的build_scrub_map_chunk
}
2.5 副本对比
当对象的主副本和从副本都完成了校验信息的构建,并保存在相应的结构Scrubmap中,下一步就是对比各副本的校验信息来完成一致性检查。
首先通过对象自身的信息来选出一个权威对象,然后用权威对象和其他对象做对比校验。
2.5.1 scrub_compare_maps
该函数实现比较不同副本数据是否一致。
- 1.把actingbackfill对应的osd的scrubmap放置到maps中。
- 2.把所有副本的object全部放到master_set中
- 3.调用be_compare_scrubmaps,比较各副本对象,把对象完整的副本所在的shard保存在authoritative
- 4.调用_scan_snaps,比较snap对象之间的一致性。
//比较不同副本数据是否一致
void PG::scrub_compare_maps()
{
dout(10) << __func__ << " has maps, analyzing" << dendl;
// construct authoritative scrub map for type specific scrubbing
scrubber.cleaned_meta_map.insert(scrubber.primary_scrubmap);
map<hobject_t,
pair<boost::optional<uint32_t>,
boost::optional<uint32_t>>> missing_digest;
map<pg_shard_t, ScrubMap *> maps;
maps[pg_whoami] = &scrubber.primary_scrubmap;
for (const auto& i : actingbackfill) {//osdmap [8,0,3], 把actingbackfill对应的osd的scrubmap放置到maps中。
if (i == pg_whoami) continue;
//scrub_compare_maps replica 0 has 24 items
//scrub_compare_maps replica 3 has 24 items
dout(2) << __func__ << " replica " << i << " has "
<< scrubber.received_maps[i].objects.size()
<< " items" << dendl;
maps[i] = &scrubber.received_maps[i];
}
set<hobject_t> master_set;//所有副本上对象的并集
// Construct master set
for (const auto map : maps) {
for (const auto i : map.second->objects) {//这里把所有副本的object全部放到master_set中
master_set.insert(i.first);
}
}
stringstream ss;
get_pgbackend()->be_large_omap_check(maps, master_set,
scrubber.large_omap_objects, ss);
if (!ss.str().empty()) {
osd->clog->warn(ss);
}
if (acting.size() > 1) {
dout(10) << __func__ << " comparing replica scrub maps" << dendl;
// Map from object with errors to good peer
map<hobject_t, list<pg_shard_t>> authoritative; //对象完整的副本所在的shard集合
//scrub_compare_maps osd.8 has 24 items
dout(2) << __func__ << " osd." << acting[0] << " has "
<< scrubber.primary_scrubmap.objects.size() << " items" << dendl;
ss.str("");
ss.clear();
get_pgbackend()->be_compare_scrubmaps(//比较各副本对象,把对象完整的副本所在的shard保存在authoritative
maps,
master_set,
state_test(PG_STATE_REPAIR),
scrubber.missing,
scrubber.inconsistent,
authoritative,
missing_digest,
scrubber.shallow_errors,
scrubber.deep_errors,
scrubber.store.get(),
info.pgid, acting,
ss);
dout(2) << ss.str() << dendl;
if (!ss.str().empty()) {
osd->clog->error(ss);
}
for (map<hobject_t, list<pg_shard_t>>::iterator i = authoritative.begin();
i != authoritative.end();
++i) {
list<pair<ScrubMap::object, pg_shard_t> > good_peers;
for (list<pg_shard_t>::const_iterator j = i->second.begin();
j != i->second.end();
++j) {
good_peers.push_back(make_pair(maps[*j]->objects[i->first], *j));//object -> osd
}
scrubber.authoritative.insert(
make_pair(
i->first,
good_peers));// object -> (object -> osd)
}
for (map<hobject_t, list<pg_shard_t>>::iterator i = authoritative.begin();
i != authoritative.end();
++i) {
scrubber.cleaned_meta_map.objects.erase(i->first);
scrubber.cleaned_meta_map.objects.insert(
*(maps[i->second.back()]->objects.find(i->first))
);
}
}
ScrubMap for_meta_scrub;
scrubber.clean_meta_map(for_meta_scrub);
// ok, do the pg-type specific scrubbing
scrub_snapshot_metadata(for_meta_scrub, missing_digest);
// Called here on the primary can use an authoritative map if it isn't the primary
_scan_snaps(for_meta_scrub);//比较snap对象之间的一致性
if (!scrubber.store->empty()) {
if (state_test(PG_STATE_REPAIR)) {
dout(10) << __func__ << ": discarding scrub results" << dendl;
scrubber.store->flush(nullptr);
} else {
dout(10) << __func__ << ": updating scrub object" << dendl;
ObjectStore::Transaction t;
scrubber.store->flush(&t);
osd->store->queue_transaction(osr.get(), std::move(t), nullptr);
}
}
}
2.5.2 be_compare_scrubmaps
该函数用来比较各副本的一致性。
- 1.遍历master_set中所有对象。进行逐个对象的一致性检查。
- 2.调用函数be_select_auth_object,选择出一个具有权威对象的副本auth,如果没有选出权威对象,调用set_auth_missing设置missing以及根据情况设置deep_errors,shallow_errors。
- 3.调用函数be_compare_scrub_objects 比较各shard上的对象和auth 对象,包括data的digest、omap的digest以及attrs。
- 4.如果结果是clean,表明该对象和权威对象各项一致,就把该shard添加到auth_list列表中。
- 5.如果结果不是clean,就把该对象加到cur_inconsistent列表中,分别统计deep_errors和shallow_errors的值。
- 6.如果该对象在某个osd(j)中不存在,就把该osd加入到cur_missing 列表,统计shallow_errors值。
- 7.检查该对象的对比结果,如果cur_missing不为空,就添加到missing列表;如果cur_inconsistent不为空,就加入inconsistent列表。
- 8.如果该对象有不完整的副本,就把没有问题的记录放在authoritative中。
- 9.如果object_info里没有data的digest和omap的digest,update置为MAYBE;如果auth_oi 中记录的data_digest和omap_digest和实际计算出的auth_object的data_digest和omap_digest不一致。修复模式下设置为FORCE,构建missing_digest,用于强制恢复。
//对比对象各个副本的一致性
void PGBackend::be_compare_scrubmaps(
const map<pg_shard_t,ScrubMap*> &maps,
const set<hobject_t> &master_set,
bool repair,
map<hobject_t, set<pg_shard_t>> &missing,
map<hobject_t, set<pg_shard_t>> &inconsistent,
map<hobject_t, list<pg_shard_t>> &authoritative,
map<hobject_t, pair<boost::optional<uint32_t>,
boost::optional<uint32_t>>> &missing_digest,
int &shallow_errors, int &deep_errors,
Scrub::Store *store,
const spg_t& pgid,
const vector<int> &acting,
ostream &errorstream)
{
utime_t now = ceph_clock_now();
// Check maps against master set and each other
for (set<hobject_t>::const_iterator k = master_set.begin();
k != master_set.end();
++k) {//遍历master_set中所有对象。进行逐个对象的一致性检查。
object_info_t auth_oi;
map<pg_shard_t, shard_info_wrapper> shard_map;
inconsistent_obj_wrapper object_error{*k};
bool digest_match;
map<pg_shard_t, ScrubMap *>::const_iterator auth =
be_select_auth_object(*k, maps, &auth_oi, shard_map, digest_match,
pgid, errorstream);//选出一个具有权威对象的副本给auth,如果没有选出,shallow_errors+1 记录这种错误
list<pg_shard_t> auth_list;
set<pg_shard_t> object_errors;
if (auth == maps.end()) {//没有找到权威的object
object_error.set_version(0);
object_error.set_auth_missing(*k, maps, shard_map, shallow_errors,
deep_errors, get_parent()->whoami_shard());
if (object_error.has_deep_errors())
++deep_errors;
else if (object_error.has_shallow_errors())
++shallow_errors;
store->add_object_error(k->pool, object_error);
errorstream << pgid.pgid << " soid " << *k
<< " : failed to pick suitable object info\n";
continue;
}
object_error.set_version(auth_oi.user_version);
ScrubMap::object& auth_object = auth->second->objects[*k];//auth_object 即为权威的object
set<pg_shard_t> cur_missing;
set<pg_shard_t> cur_inconsistent;
bool fix_digest = false;
for (auto j = maps.cbegin(); j != maps.cend(); ++j) {
if (j == auth)
shard_map[auth->first].selected_oi = true;
if (j->second->objects.count(*k)) {//可以找到对象
shard_map[j->first].set_object(j->second->objects[*k]);
// Compare
stringstream ss;
bool found = be_compare_scrub_objects(auth->first,
auth_object,
auth_oi,
j->second->objects[*k],
shard_map[j->first],
object_error,
ss,
k->has_snapset());//比较各shard上的对象和auth 对象,包括data的digest、omap的digest以及attrs。
/*
*be_compare_scrubmaps replicated shards 3 digest_match
*be_compare_scrubmaps replicated shards 3 digest_match
*be_compare_scrubmaps replicated auth shards 3 digest_match
*/
dout(20) << __func__ << (repair ? " repair " : " ") << (parent->get_pool().is_replicated() ? "replicated " : "")
<< (j == auth ? "auth " : "") << "shards " << shard_map.size() << (digest_match ? " digest_match " : " ")
<< (shard_map[j->first].has_data_digest_mismatch_info() ? "info_mismatch " : "")
<< (shard_map[j->first].only_data_digest_mismatch_info() ? "only" : "")
<< dendl;
if (cct->_conf->osd_distrust_data_digest/*false*/) {
if (digest_match && parent->get_pool().is_replicated()
&& shard_map[j->first].has_data_digest_mismatch_info()) {
fix_digest = true;
}
shard_map[j->first].clear_data_digest_mismatch_info();
// If all replicas match, but they don'by using missing_digest mechanism
} else if (repair && parent->get_pool().is_replicated() && j == auth && shard_map.size() > 1
&& digest_match && shard_map[j->first].only_data_digest_mismatch_info()
&& auth_object.digest_present) {
// Set in missing_digests
fix_digest = true;
// Clear the error
shard_map[j->first].clear_data_digest_mismatch_info();
errorstream << pgid << " soid " << *k << " : repairing object info data_digest" << "\n";
}
// Some errors might have already been set in be_select_auth_object()
if (shard_map[j->first].errors != 0) {//有error信息
cur_inconsistent.insert(j->first);
if (shard_map[j->first].has_deep_errors())
++deep_errors;
else
++shallow_errors;
// Only true if be_compare_scrub_objects() found errors and put something
// in ss.
if (found)
errorstream << pgid << " shard " << j->first << " soid " << *k
<< " : " << ss.str() << "\n";
} else if (found) {// 有不匹配的信息
// Track possible shard to use as authoritative, if needed
// There are errors, without identifying the shard
object_errors.insert(j->first);
errorstream << pgid << " soid " << *k << " : " << ss.str() << "\n";
} else {// 没有异常,才会把osd 加入到auth_list
// XXX: The auth shard might get here that we don't know
// that it has the "correct" data.
auth_list.push_back(j->first);
}
} else {//对象在某个osd(j)中不存在
cur_missing.insert(j->first);// 把该osd加入到cur_missing 列表
shard_map[j->first].set_missing();
shard_map[j->first].primary = (j->first == get_parent()->whoami_shard());
// Can't have any other errors if there is no information available
++shallow_errors;
errorstream << pgid << " shard " << j->first << " " << *k << " : missing\n";
}
object_error.add_shard(j->first, shard_map[j->first]);
}
if (auth_list.empty()) {
if (object_errors.empty()) {
errorstream << pgid.pgid << " soid " << *k
<< " : failed to pick suitable auth object\n";
goto out;
}
// Object errors exist and nothing in auth_list
// Prefer the auth shard otherwise take first from list.
pg_shard_t shard;
if (object_errors.count(auth->first)) {//auth osd存在Object errors,osd又不在auth_list,加入到auth_list
shard = auth->first;
} else {
shard = *(object_errors.begin());
}
auth_list.push_back(shard);
object_errors.erase(shard);
}
// At this point auth_list is populated, so we add the object errors shards
// as inconsistent.
cur_inconsistent.insert(object_errors.begin(), object_errors.end());
if (!cur_missing.empty()) {
missing[*k] = cur_missing;//加入missing列表
}
if (!cur_inconsistent.empty()) {
inconsistent[*k] = cur_inconsistent;//加入inconsistent列表
}
if (fix_digest) {//是否修复digest
boost::optional<uint32_t> data_digest, omap_digest;
assert(auth_object.digest_present);
data_digest = auth_object.digest;
if (auth_object.omap_digest_present) {
omap_digest = auth_object.omap_digest;
}
missing_digest[*k] = make_pair(data_digest, omap_digest);
}
// Special handling of this particular type of inconsistency
// This can over-ride a data_digest or set an omap_digest
// when all replicas match but the object info is wrong.
if (!cur_inconsistent.empty() || !cur_missing.empty()) {
authoritative[*k] = auth_list;//如果该对象有不完整的副本,就把没有问题的记录放在authoritative中。
} else if (!fix_digest && parent->get_pool().is_replicated()) {
enum {
NO = 0,
MAYBE = 1,
FORCE = 2,
} update = NO;
//如果object_info里没有data的digest和omap的digest,update置为MAYBE
if (auth_object.digest_present && !auth_oi.is_data_digest()) {
dout(20) << __func__ << " missing data digest on " << *k << dendl;
update = MAYBE;
}
if (auth_object.omap_digest_present && !auth_oi.is_omap_digest()) {
dout(20) << __func__ << " missing omap digest on " << *k << dendl;
update = MAYBE;
}
// recorded digest != actual digest?
if (auth_oi.is_data_digest() && auth_object.digest_present &&
auth_oi.data_digest != auth_object.digest) {//auth_oi 中记录的data_digest和omap_digest和实际计算出的auth_object的data_digest和omap_digest不一致。
assert(cct->_conf->osd_distrust_data_digest
|| shard_map[auth->first].has_data_digest_mismatch_info());
errorstream << pgid << " recorded data digest 0x"
<< std::hex << auth_oi.data_digest << " != on disk 0x"
<< auth_object.digest << std::dec << " on " << auth_oi.soid
<< "\n";
if (repair)
update = FORCE;
}
if (auth_oi.is_omap_digest() && auth_object.omap_digest_present &&
auth_oi.omap_digest != auth_object.omap_digest) {
assert(shard_map[auth->first].has_omap_digest_mismatch_info());
errorstream << pgid << " recorded omap digest 0x"
<< std::hex << auth_oi.omap_digest << " != on disk 0x"
<< auth_object.omap_digest << std::dec
<< " on " << auth_oi.soid << "\n";
if (repair)
update = FORCE;
}
if (update != NO) {
utime_t age = now - auth_oi.local_mtime;
if (update == FORCE ||
age > cct->_conf->osd_deep_scrub_update_digest_min_age/*2_hr*/) {
boost::optional<uint32_t> data_digest, omap_digest;
if (auth_object.digest_present) {
data_digest = auth_object.digest;
dout(20) << __func__ << " will update data digest on " << *k << dendl;
}
if (auth_object.omap_digest_present) {
omap_digest = auth_object.omap_digest;
dout(20) << __func__ << " will update omap digest on " << *k << dendl;
}
missing_digest[*k] = make_pair(data_digest, omap_digest);
} else {
dout(20) << __func__ << " missing digest but age " << age
<< " < " << cct->_conf->osd_deep_scrub_update_digest_min_age
<< " on " << *k << dendl;
}
}
}
out:
if (object_error.has_deep_errors())
++deep_errors;
else if (object_error.has_shallow_errors())
++shallow_errors;
if (object_error.errors || object_error.union_shards.errors) {
store->add_object_error(k->pool, object_error);
}
}
}2.5.3 be_select_auth_object
该函数在各副本对象中选择出一个权威的对象auth_obj。其原理是根据自身所携带的冗余信息验证自己是否完整。
- 1.把obj所在的osd放入shards列表,主osd放在列表头部。
- 2.遍历shards列表,循环逐个shard进行判断。
- 3.如果获取对象的数据和元数据出错,那么退出
- 4.确认获取OI_ATTR属性不为空,并将数据结构正确解码为object_info_t (oi),验证保存在object_info_t(oi)中的size和扫描对象的size值是否一致,如果不一致,就继续查找下一个更好的副本对象。
- 5.如果暂时auth 已经选出(auth_version != eversion_t()),auth的digest和待验证的obj的digest不一致,设置digest_match=false
- 6.如果shard_info.errors不为0,说明某个object有error,是不会选择为auth的。
- 7.如果shard_info.errors 为0,此时才有竞选auth的资格。开始选择auth:
-
- 第一次(主副本),auth_version=0`0,满足auth_version == eversion_t(),设置auth,auth_version = oi.version
-
- 第二次(次副本),oi.version == auth_version, 无法满足条件,进不去;//(dcount(oi, oi_prio) > dcount(*auth_oi, auth_prio)))默认同时拥有data和omap crc的object所在osd为auth,如果第一个osd的object 的data或者omap的crc缺失,那么第二个osd的object判断,会大于第一个的count,此时第二个为auth。
-
- 第三次(次副本),同第二次;
-
- 注:如果第一次的object比较完整,即使其他副本obj也完整,仍然选择第一个osd当选auth。
//在各副本对象中选择出一个权威的对象auth_obj
map<pg_shard_t, ScrubMap *>::const_iterator
PGBackend::be_select_auth_object(
const hobject_t &obj,
const map<pg_shard_t,ScrubMap*> &maps,
object_info_t *auth_oi,
map<pg_shard_t, shard_info_wrapper> &shard_map,
bool &digest_match,
spg_t pgid,
ostream &errorstream)
{
eversion_t auth_version;
bool auth_prio = false;
// Create list of shards with primary first so it will be auth copy all
// other things being equal.
list<pg_shard_t> shards;
for (map<pg_shard_t, ScrubMap *>::const_iterator j = maps.begin();
j != maps.end();
++j) {
if (j->first == get_parent()->whoami_shard())
continue;
shards.push_back(j->first);
}
shards.push_front(get_parent()->whoami_shard());//[8,0,3] osd.8 为主 把obj所在的osd放入shards列表,主osd放在列表头部。
map<pg_shard_t, ScrubMap *>::const_iterator auth = maps.end();
digest_match = true;
for (auto &l : shards) {
bool oi_prio = false;
ostringstream shard_errorstream;
bool error = false;
map<pg_shard_t, ScrubMap *>::const_iterator j = maps.find(l);
map<hobject_t, ScrubMap::object>::iterator i =
j->second->objects.find(obj);
if (i == j->second->objects.end()) {//没有找到要校验的对象
continue;
}
auto& shard_info = shard_map[j->first];//scrubmap 中某个osd的info信息
if (j->first == get_parent()->whoami_shard())
shard_info.primary = true;//当前osd为primary
if (i->second.read_error) {// 要校验的对象 read_error
shard_info.set_read_error();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a read error";
}
if (i->second.ec_hash_mismatch) {
shard_info.set_ec_hash_mismatch();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had an ec hash mismatch";
}
if (i->second.ec_size_mismatch) {
shard_info.set_ec_size_mismatch();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had an ec size mismatch";
}
object_info_t oi;
bufferlist bl;
map<string, bufferptr>::iterator k;
SnapSet ss;
bufferlist ss_bl, hk_bl;
if (i->second.stat_error) {
shard_info.set_stat_error();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a stat error";
// With stat_error no further checking
// We don't need to also see a missing_object_info_attr
goto out;//如果获取对象的数据和元数据出错,那么退出
}
// We won't pick an auth copy if the snapset is missing or won't decode.
if (obj.is_head() || obj.is_snapdir()) {
k = i->second.attrs.find(SS_ATTR);
if (k == i->second.attrs.end()) {
shard_info.set_snapset_missing();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a missing snapset key";
} else {
ss_bl.push_back(k->second);
try {
bufferlist::iterator bliter = ss_bl.begin();
::decode(ss, bliter);
} catch (...) {
// invalid snapset, probably corrupt
shard_info.set_snapset_corrupted();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a corrupt snapset";
}
}
}
if (parent->get_pool().is_erasure()) {
ECUtil::HashInfo hi;
k = i->second.attrs.find(ECUtil::get_hinfo_key());
if (k == i->second.attrs.end()) {
shard_info.set_hinfo_missing();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a missing hinfo key";
} else {
hk_bl.push_back(k->second);
try {
bufferlist::iterator bliter = hk_bl.begin();
decode(hi, bliter);
} catch (...) {
// invalid snapset, probably corrupt
shard_info.set_hinfo_corrupted();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a corrupt hinfo";
}
}
}
k = i->second.attrs.find(OI_ATTR);
if (k == i->second.attrs.end()) {
// no object info on object, probably corrupt
shard_info.set_info_missing();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a missing info key";
goto out;
}
bl.push_back(k->second);
try {
bufferlist::iterator bliter = bl.begin();
::decode(oi, bliter);//确认获取OI_ATTR属性不为空,并将数据结构正确解码为object_info_t (oi)
} catch (...) {
// invalid object info, probably corrupt
shard_info.set_info_corrupted();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate had a corrupt info";
goto out;
}
// This is automatically corrected in PG::_repair_oinfo_oid()
assert(oi.soid == obj);
dout(10) << __func__ << "wds-2: l:" << l << ", i->first:" << i.first << ", i->second.size:" << i->second.size << ", oi.size:" << oi.size << dendl;
if (i->second.size != be_get_ondisk_size(oi.size)) {//验证保存在object_info_t(oi)中的size和扫描对象的size值是否一致,如果不一致,就继续查找下一个更好的副本对象
shard_info.set_obj_size_info_mismatch();
if (error)
shard_errorstream << ", ";
error = true;
shard_errorstream << "candidate size " << i->second.size << " info size "
<< oi.size << " mismatch";
}
// digest_match will only be true if computed digests are the same
if (auth_version != eversion_t()
&& auth->second->objects[obj].digest_present
&& i->second.digest_present
&& auth->second->objects[obj].digest != i->second.digest) {// 暂时auth 已经选出(auth_version != eversion_t()),auth的digest和待验证的obj的digest不一致,设置digest_match=false
digest_match = false;
dout(10) << __func__ << " digest_match = false, " << obj << " data_digest 0x" << std::hex << i->second.digest
<< " != data_digest 0x" << auth->second->objects[obj].digest << std::dec
<< dendl;
}
// Don't use this particular shard due to previous errors
// XXX: For now we can't pick one shard for repair and another's object info or snapset
if (shard_info.errors)//这里如果某个object有error,是不会选择为auth的。
goto out;
// XXX: Do I want replicated only?
if (parent->get_pool().is_replicated() && cct->_conf->osd_distrust_data_digest/*false*/) {
// This is a boost::optional<bool> so see if option set AND it has the value true
// We give priority to a replica where the ObjectStore like BlueStore has builtin checksum
if (j->second->has_builtin_csum && j->second->has_builtin_csum == true) {
oi_prio = true;
}
}
dout(10) << __func__ << " wds-4: auth_version:" << auth_version << "oi.version:" << oi.version << " j->first:" << j->first << dendl;
/*
*第一次,auth_version=0`0,满足auth_version == eversion_t(),设置auth,auth_version = oi.version
*第二次,oi.version == auth_version, 无法满足条件,进不去;//(dcount(oi, oi_prio) > dcount(*auth_oi, auth_prio)))默认同时拥有data和omap crc的object所在osd为auth,如果第一个osd的object 的data或者omap的crc缺失,那么第二个osd的object判断,会大于第一个的count,此时第二个为auth
*第三次,同第二次;
*注:如果第一次的object比较完整,即使其他副本obj也完整,仍然选择第一个osd当选auth。
*/
if (auth_version == eversion_t() || oi.version > auth_version ||
(oi.version == auth_version && dcount(oi, oi_prio) > dcount(*auth_oi, auth_prio))) {
auth = j;
*auth_oi = oi;
auth_version = oi.version;
auth_prio = oi_prio;
dout(10) << __func__ << " wds-5: auth->first:" << auth->first << dendl;
}
out:
if (error)
errorstream << pgid.pgid << " shard " << l << " soid " << obj
<< " : " << shard_errorstream.str() << "\n";
// Keep scanning other shards
}
dout(10) << __func__ << ": selecting osd " << auth->first
<< " for obj " << obj
<< " with oi " << *auth_oi
<< dendl;
/*
*2020-08-28 09:53:18.636882 7f60d52e4700 10 osd.8 pg_epoch: 147 pg[2.6( v 147'409 (0'0,147'409] local-lis/les=146/147 n=37 ec=131/131 lis/c 146/146 les/c/f 147/147/0 146/146/146) [8,0,3] r=
*0 lpr=146 crt=147'409 lcod 147'408 mlcod 147'408 active+clean+scrubbing+deep] be_select_auth_object: selecting osd 8 for obj 2:62b05854:::rbd_data.6ed5b6b8b4567.000000000000006e:head with
*oi 2:62b05854:::rbd_data.6ed5b6b8b4567.000000000000006e:head(147'378 osd.8.0:5 dirty|data_digest|omap_digest s 3866624 uv 372 dd 210c09f1 od ffffffff alloc_hint [4194304 4194304 0])
*/
return auth;
}2.6 结束scrub过程
PG::scrub_finish() 函数用于结束scrub过程。
- 1.调用函数scrub_process_inconsistent 用于修复scrubber中标记的missing和inconsistent对象,最终调用repair_object函数。它只是在peer_missing和missing中标记对象缺失。authoritative 不为空,且repair为true时,has_error才为true。
- 2.设置相关PG状态及统计信息。
- 3.如果has_error为true,把DoRecovery 事件发送PG状态机,发起实际对象的修复操作。实际上,执行deepscrub操作,repair为0,不会触发修复操作的。
- 4.当pg恢复正常,调用函数PG::share_pg_info()把 新的pg_info 信息发送到其他副本。
// the part that actually finalizes a scrub
void PG::scrub_finish()
{
bool repair = state_test(PG_STATE_REPAIR);
// if the repair request comes from auto-repair and large number of errors,
// we would like to cancel auto-repair
if (repair && scrubber.auto_repair
&& scrubber.authoritative.size() > cct->_conf->osd_scrub_auto_repair_num_errors) {
state_clear(PG_STATE_REPAIR);
repair = false;
}
bool deep_scrub = state_test(PG_STATE_DEEP_SCRUB);
const char *mode = (repair ? "repair": (deep_scrub ? "deep-scrub" : "scrub"));
// type-specific finish (can tally more errors)
_scrub_finish();
//authoritative 不为空,且repair为true时,has_error才为true
bool has_error = scrub_process_inconsistent();// 用于修复scrubber中标记的missing和inconsistent对象,最终调用repair_object函数。她只是在peer_missing和missing中标记对象缺失。
{
stringstream oss;
oss << info.pgid.pgid << " " << mode << " ";
int total_errors = scrubber.shallow_errors + scrubber.deep_errors;
if (total_errors)
oss << total_errors << " errors";
else
oss << "ok";//2.6 deep-scrub ok
if (!deep_scrub && info.stats.stats.sum.num_deep_scrub_errors)
oss << " ( " << info.stats.stats.sum.num_deep_scrub_errors
<< " remaining deep scrub error details lost)";
if (repair)
oss << ", " << scrubber.fixed << " fixed";
if (total_errors)
osd->clog->error(oss);
else
osd->clog->debug(oss);
}
// finish up
unreg_next_scrub();
utime_t now = ceph_clock_now();
info.history.last_scrub = info.last_update;//更新pginfo的信息
info.history.last_scrub_stamp = now;
if (scrubber.deep) {
info.history.last_deep_scrub = info.last_update;
info.history.last_deep_scrub_stamp = now;
}
// Since we don't know which errors were fixed, we can only clear them
// when every one has been fixed.
if (repair) {
if (scrubber.fixed == scrubber.shallow_errors + scrubber.deep_errors) {
assert(deep_scrub);
scrubber.shallow_errors = scrubber.deep_errors = 0;
} else {
// Deep scrub in order to get corrected error counts
scrub_after_recovery = true;
}
}
if (deep_scrub) {
if ((scrubber.shallow_errors == 0) && (scrubber.deep_errors == 0))
info.history.last_clean_scrub_stamp = now;
info.stats.stats.sum.num_shallow_scrub_errors = scrubber.shallow_errors;
info.stats.stats.sum.num_deep_scrub_errors = scrubber.deep_errors;
info.stats.stats.sum.num_large_omap_objects = scrubber.large_omap_objects;
} else {
info.stats.stats.sum.num_shallow_scrub_errors = scrubber.shallow_errors;
// XXX: last_clean_scrub_stamp doesn't mean the pg is not inconsistent
// because of deep-scrub errors
if (scrubber.shallow_errors == 0)
info.history.last_clean_scrub_stamp = now;
}
info.stats.stats.sum.num_scrub_errors =
info.stats.stats.sum.num_shallow_scrub_errors +
info.stats.stats.sum.num_deep_scrub_errors;
reg_next_scrub();
{
ObjectStore::Transaction t;
dirty_info = true;
write_if_dirty(t);
int tr = osd->store->queue_transaction(osr.get(), std::move(t), NULL);
assert(tr == 0);
}
if (has_error) {//把DoRecovery 事件发送PG状态机,发起实际对象的修复操作。如果是deep操作,has_error 为false
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
DoRecovery())));
}
scrub_clear_state();
scrub_unreserve_replicas();
if (is_active() && is_primary()) {
share_pg_info();
}
}注:参考《ceph 源码分析》丛书