需要配置多台服务器,实验环境:master和data两台服务器,已安装好hadoop,可参考前文!!!
1.spark安装
- master安装
(1)下载scala和spark
(2)解压并配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin(3)配置spark-env.sh文件
export SPARK_MASTER_IP=IP
export SPARK_MASTER_HOST=IP
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=4
export SPARK_MASTER_PORT=7077(4)配置slaves文件
data
- data安装
(1)下载scala和spark
(2)解压并配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin(3)配置spark-env.sh文件
export SPARK_MASTER_IP=IP
export SPARK_MASTER_HOST=IP
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=4
export SPARK_MASTER_PORT=7077启动和测试:
进入到sbin目录启动:start-all.sh或者start-master.sh、start-slaves.sh,输入jps:
扫描二维码关注公众号,回复:
13000192 查看本文章

master显示: data显示:
data显示: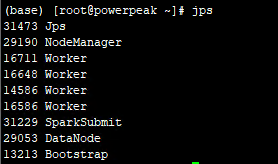
然后启动pyspark:
pyspark 可以访问成功,然后更换模式:
pyspark --master spark://master_ip:70772. 配置Anaconda和远程访问Jupyter
(1)安装Anaconda
安装:![]()
配置环境变量:![]()
(2)远程配置Jupyter
参考:https://blog.csdn.net/MuziZZ/article/details/101703604
(3)pyspark和python结合
export PATH=$PATH:/root/anaconda3/bin
export ANACONDA_PATH=/root/anaconda3
export PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/jupyter-notebook
#PARK_DRIVER_PYTHON="jupyter" PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark
export PYSPARK_PYTHON=$ANACONDA_PATH/bin/python访问界面:
