1.一致性哈希
什么是一致性哈希,和一般的分布式哈希表(DHT)有什么区别?一般的DHT使用以下公式进行数据定位:position = Hash(对象名) % N(N是节点个数)。很明显,如果我们在集群中增减一个节点,都必须要重新计算对象的位置,导致大量的数据迁移的发生。文中的对象表示文件(分布式文件系统)或者数据块(p2p)。而一致性哈希的计算公式则不同:position = Hash(对象名) % M(M是一个常量,一般取2^31 )。
如何使用一致性哈希定位文件?
大体上分成两步:1. 计算节点位置 2. 将对象分布到各个节点。下面,我给各位细细道来:
开始时我们使用常用的哈希函数以节点名或者节点IP为键值计算哈希并将计算得到的哈希和M=2^31取模,得到一个新的哈希值。这个哈希值就表示节点的位置。如下图所示我们以节点名作为键值,计算出N1, N2, N3, N4四个节点的哈希分别是2000, 3000, 4000, 5000。
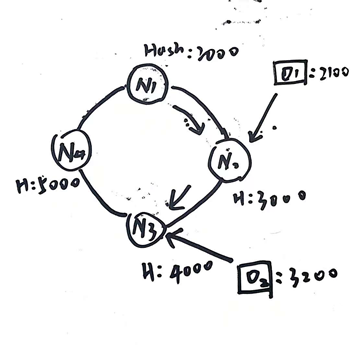
随后,我们使用相同的方法计算对象的哈希值,hash = Hash(对象名) % (2^31)。计算完成之后得到对象O1的哈希时2100,这时我们以顺时针的顺序将O1放到节点N2。同样哈希值为3200的O2被放到节点N3。
那么这样究竟有什么好处呢?假如我们增加一个节点X,计算出来X节点的位置是3500。在普通的DHT中我们需要重新计算每个节点中的数据的位置。但是(重点来了)在一致性哈希中,我们只需要把节点N3中的对象O2迁移到新节点X中。只影响到节点N3到节点X之间的对象,图中用黑色粗体标注的部分。大大减少了被影响的节点。
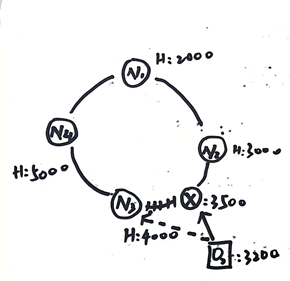
我们在看看删除节点的情况,假如我们删除节点N3。只需要按照顺时针的方向,将N3中的所有对象迁移到离其最近的节点N4。

可以看到作为一种分布式环境下的数据分布手段,一致性哈希即保留了DHT的负载均衡的特点,又降低了节点的横向拓展带来的数据迁移的开销。那么哪里都用到了一致性哈希?目前我知道的领域有BT下载,分布式文件系统(IPFS,ceph,openstack swift)。
2.一致性哈希的改进
从上面的内容我们可以看到,当我们在增加或者删除一个节点时,会增加其相邻节点的负载,这当然不是我们想看到的,理想的状态是将负载均衡到集群中的每一个节点。那么应该怎么才能做到这一点呢?可以通过引入虚拟节点来解决这个问题。
每个物理节点都被分割为几个虚拟节点,每个对象先计算其位于哪一个虚拟节点,在通过判断虚拟节点的owner,将对象存储到实际的物理节点。

从上图可以看到,整个结构分成两层,外层的虚拟节点层和内层的物理节点层,并且外层的虚拟节点是随机分布的。虚拟节点通过这种随机的排列顺序进一步提高了物理节点的负载均衡。
我们来看看去掉N4节点时的数据迁移情况。当移除N4节点时,所有属于N4的虚拟节点上的数据都要迁移到它们的顺时针方向的下一个虚拟节点,本例中是N3#1,N2#2,N1#3,N1#1。可以看到N4的数据会均衡的再分布到其余的每一个节点。
3.一致性哈希的实现
代码已经放到github,使用golang来编写,目前尚未完成,欢迎大家指正。https://github.com/DennisWong/ConsistentHash.git
参考
一致性Hash(Consistent Hashing)原理剖析,关于虚拟节点的解释很易懂
https://blog.csdn.net/lihao21/article/details/54193868
五分钟看懂一致性哈希算法
https://juejin.im/post/5ae1476ef265da0b8d419ef2
介绍openstack的一致性哈希