内容: 在分布式储存中一种很有利与扩展的算法:一致性哈希
出现背景:
有海量的数据分布式地储存在许多的储存站点上,当站点信息出现变化时,数据需要如何处理?
假设哈希函数为:
hash(数据_ID) = 数据_ID % 站点数量
1、如果某个站点宕机了,那么数据需要重新进行哈希,那么如何进行哈希呢?
举个例子:
假设3号站点宕机了,总共有四个站点。那么原来映射的数据就得重新映射了。因为以前分配到站点X的数据
是根据ID % 4 = X , 就分配到X站点去储存。但是现在只有三个站点了,原来的数据就得迁移,因为他映射
完的结果不会是X了。而是:ID % 3 = Y , 就得分配到Y站点去储存。
2、如果因为数据量太大,需要扩展新的站点,那么数据需要重新进行哈希,那么如何进行哈希呢?
举个例子:
假设新加入了5号站点,以前有四个站点,现在有五个了。那么原来映射的数据就得重新映射了。因为以前
分配到站点X的数据是根据ID % 4 = X , 就分配到X站点去储存。但是现在有五个站点了,原来的数据就
得迁移,因为他映射完的结果不会是X了。而是:ID % 5 = Y , 就得分配到Y站点去储存。
没有一致性哈希导致的问题:
每当站点信息发生变化,就得大规模迁移数据,是个开销非常大的操作,特别是对海量数据
一致性哈希如何解决呢?
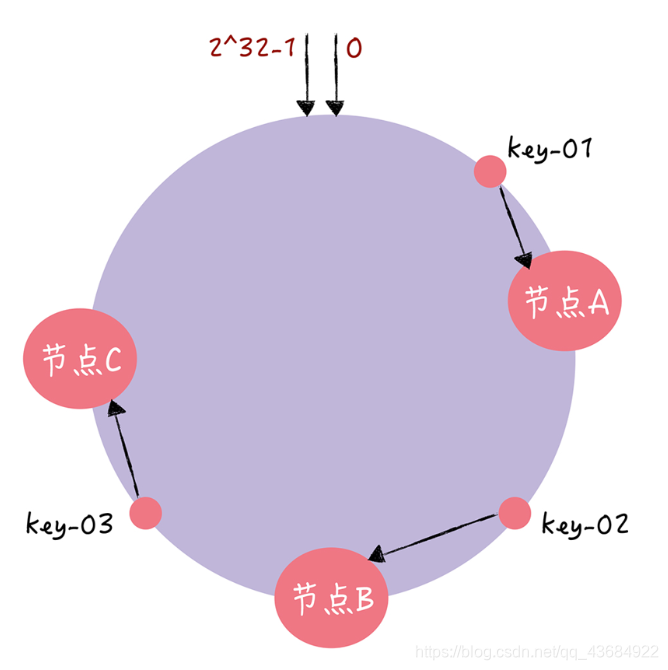
1、首先把映射的数据想想成一个圆

(图片来源:极客时间)
2、每个站点负责环上一部分数段区间的数据,也就是说A站点就负责映射到Z-X数值的这段区间,
那么站点B就负责X-Y数值的这段区间,C就负责Y-Z数值的这段区间。其中X-Y-Z这三个数据值刚好
就将0-2^32-1这个数据区间划分成三段。
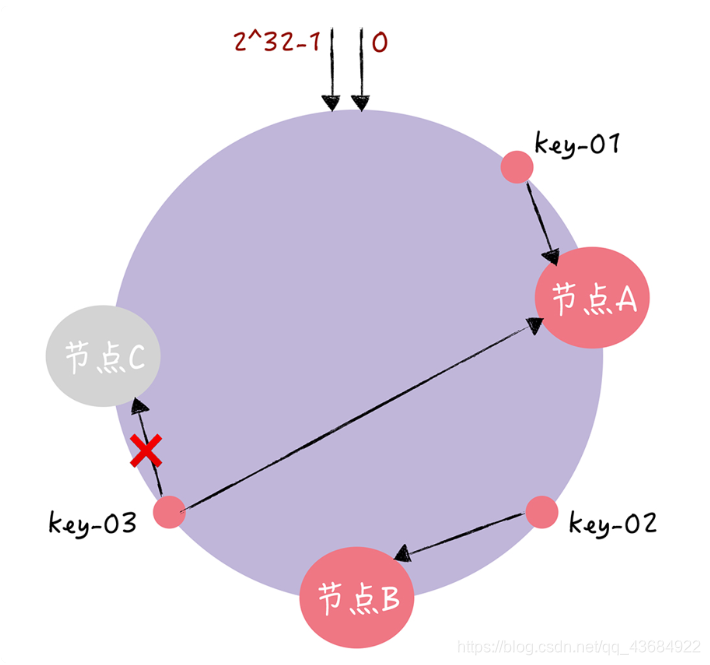
3、当出现迁移的时候:假设站点C没用了,那么就将站点C本该负责的数据继续往环的时钟方向
顺延映射到下一个站点,也就是站点A
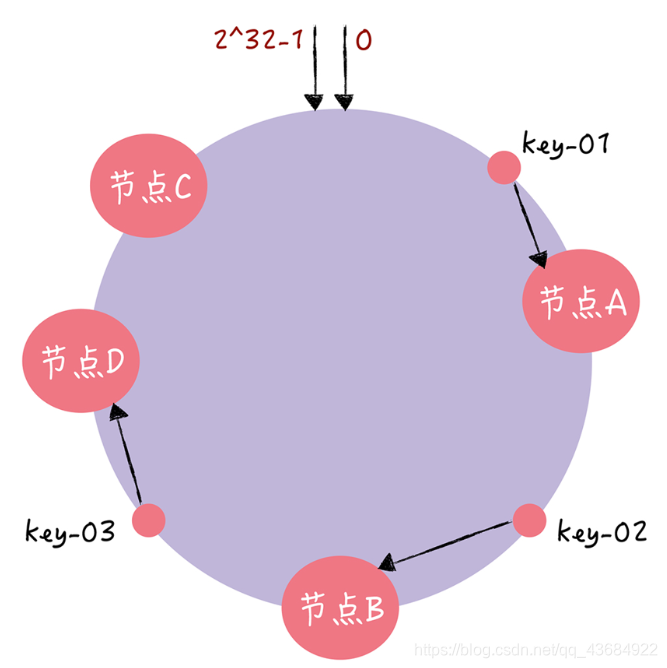
4、需要新增站点:新增站点负责的数段在原某两个站点负责的数据段之间,那么就将新站点负责的那一段映射到新站点,删除旧站点上的这一段信息,其余信息不变。假设图中的key-03这一段映射到新站点D,而新站点到就站点C之间的这一段还是放在C上就好,同时在C站点上删除新站点负责的内容
以上就是一致性哈希的思想,为什么这样可行呢?
因为当站点信息发生改变的时候,只有某个数段的信息需要重新映射而已,而总体不变。那么当站点很多,
那么圆环会被细分成很多数段,那么某个站点发生意外,需要重映射的数据段对全局来说其实很小,造成的
影响也最小
注意一致性哈希可能的问题:雪崩
雪崩:顾名思义就是想滚雪球一样,那么使用一致性哈希什么情况下会出现雪崩呢?
出现情况:当某个站点宕机,他承当的数据需要映射到下一个站点,如何下一个站点扛不住这么多数据,
那么也宕机了,那下下个站点就得抗住前两个站点的数据,压力更大,也宕机了。那么下下下个
站点呢?以此类型,越后的站点需要承受的压力越大,那么压力就会像滚雪球一样一直往后压,
最终导致大全部站点宕机
解决:引入虚拟站点,也就是将每个站点负责的数据段其实是分散的,圆环划分数段的站点是逻辑站点,而
非真正的物理站点。那么看似滚雪球的压力其实不会都落到一个站点,而是均匀分散到各个站点。
(同时虚拟站点也能使各站点负载均衡一些,不至于某些站点映射的数段的信息过于多,因为负责的
数段一样,不代表映射的信息一样多,更不代表的这部分信息代表的业务也一样多)
大四学生一枚,如果文章有错误的地方,欢迎在下方提出,每条评论我都会去认真看并回复,同时感谢指正的前辈。有喜欢C/C++,linux的同学欢迎私信一起讨论学习。
