一、二次排序问题。

MR/hadoop两种方案:
1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序。这种方法不具有可伸缩性,因为reducer要接受一个给定键的所有值,这种方法可能导致reducer的内存耗尽(OOM)。另一方面,如果值数量很少,就不会导致内存溢出,那么这种方法可行。
2.使用MR框架对reducer的值排序(这样一来,就不再需要对传入reducer的值完成排序。)这种方法“会为自然键增加部分或整个值来创建一个组合键以实现排序目标”(参考 java Code Geeks)。这种方法可伸缩,不会产生内存溢出错误。在这里,排序工作基本上由MR框架来完成。
使用MR框架的二次排序设计模式,规约器值到达时就是有序地。(也就是说,不再需要在内存中对值进行排序)。这种技术使用了MR框架的洗牌和排序技术完成规约器值的排序。这种解决方案比1更可取,不再依赖内存完成排序。
思考分析:对返回数据形式进行分析,自定义对象和reducer的分区策略。(当然为了实现排序,要对自定义的对象进行实现comparele接口,重写compare方法。)
spark两种方案:
1.将一个给定键的所有值读取缓存到一个List数组结构中,然后对这些值完成排序。优缺点同MR方案1.
2.使用Spark框架对规约器值排序(这种做法不需要对传入规约器的值完成规约器中排序)。这种方法“会为自然建增加部分或整个值来创建一个组合键以实现排序目标。”
二。 Top N问题。
列表L的TopN 算法大致描述:L列表的元素是一个scala的tuple结构,通过java的TreeMap将一个tuple添加到其中,然后对TreeMap进>N的if操作,来进行remove操作。
1.唯一键。
例子:

在这个问题上,可以使用一个规约器完成对所有数据的接收,所有压力和负载全部是都在这一个节点上。在这里不糊带来性能问题,为什么呢。假设有由1000个映射,每个映射器只会生成10个键值对,因为,这个规约器只会得到10*1000个记录,这个数据量还不至于导致性能瓶颈。
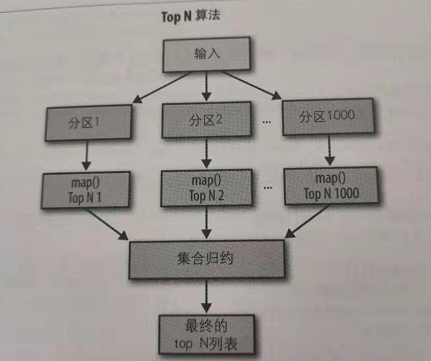
2.非唯一键