一、工具准备
1. jdk1.8
2. scala
3. anaconda3
4. spark-2.3.1-bin-hadoop2.7
5. hadoop-2.8.3
6. winutils
7. pycharm
二、安装
1. jdk安装
oracle官网下载,安装后配置JAVA_HOME、CLASS_PATH,bin目录追加到PATH,注意:win10环境下PATH最好使用绝对路径!下同!

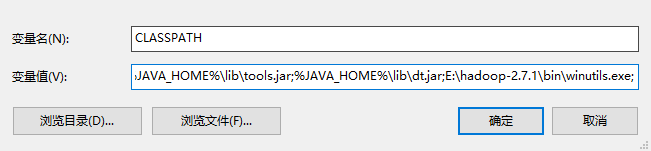
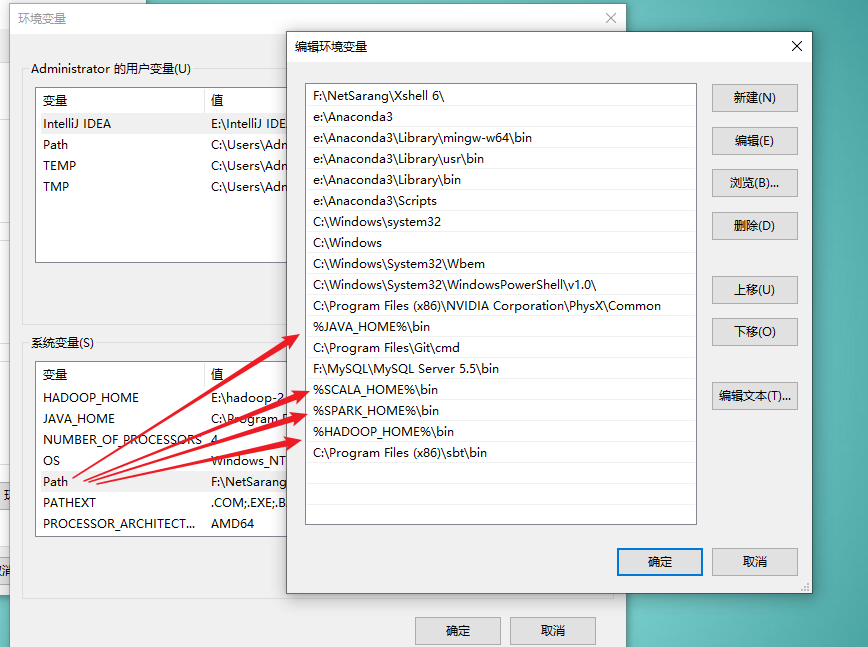
2. scala安装
官网下载,安装后配置SCALA_HOME,bin目录追加到PATH(上图包含)

3. anaconda3安装
官网下载,安装时注意在“追加到PATH”复选框打钩
4. spark安装
官网下载压缩包,解压缩后配置SPARK_HOME,bin目录追加到PATH(上图包含)
5. hadoop安装
官网下载版本>=spark对应hadoop版本,解压缩后配置HADOOP_HOME,bin目录追加到PATH(上图包含)
6. winutils安装
下载地址:https://github.com/steveloughran/winutils,按hadoop版本对应下载
7. pycharm安装
下载付费版本,使用lanyu注册码激活,注意按照提示添加域名解析到hosts文件
三、处理python相关
- 将pyspark文件夹(在spark-2.3.1-bin-hadoop2.7\python目录)复制到anaconda3\Lib\site-packages目录下
- 将winutils解压缩后用对应版本的bin目录替换hadoop下的bin目录
- conda install py4j
- 进入hadoop\bin目录下,以管理员方式打开cmd,输入命令:winutils.exe chmod 777 c:\tmp\Hive,若提示错误,检查Hive目录是否存在,若不存在,则手动创建,再重新执行命令
四、验证
打开pycharm,使用anaconda中的python作为解释器,输入以下代码并运行:
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a', 'b', 'c'], ['b', 'd', 'd']])
words = doc.flatMap(lambda d: d).distinct().collect()
word_dict = {w: i for w, i in zip(words, range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict = {}
wd = word_dict_b.value
for w in d:
if wd[w] in dict:
dict[wd[w]] += 1
else:
dict[wd[w]] = 1
return dict
print(doc.map(wordCountPerDoc).collect())
print("successful!")
运行结果:


[{0: 1, 1: 1, 2: 1}, {1: 1, 3: 2}]
successful!
本文为win10+pyspark+pycharm+anaconda的单机测试环境搭建。