python 识别图片上的数字,使用pytesseract库从图像中提取文本,而识别引擎采用 tesseract-ocr。
Tesseract是一款由Google赞助的开源OCR。OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。
pytesseract是python包装器,它为可执行文件提供了pythonic API。
1、安装必要的包:
pip install pillow
pip install pytesseract
2、安装tesseract-ocr的识别引擎
* 下载地址:https://github.com/UB-Mannheim/tesseract/wiki
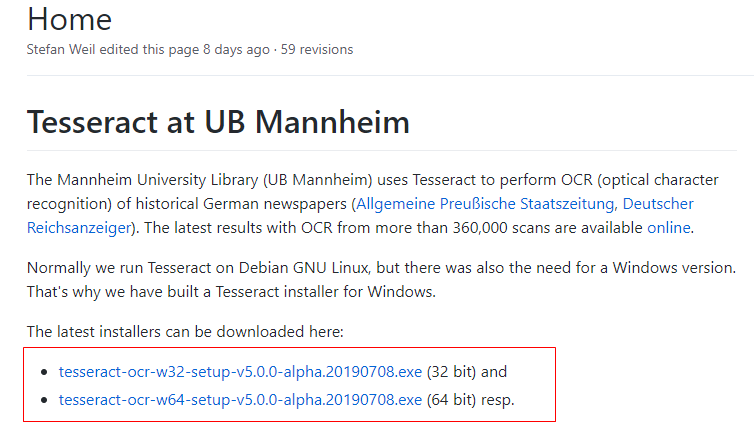
或者更多版本的tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
* 装完成后配置环境变量: 我的电脑 ->属性 -> 高级系统设置 ->环境变量 ->系统变量 ,在 path 中添加 安装路径。
在命令行 WIN+R 输入cmd :输入 tesseract -v ,出现版本信息,则配置成功。

3、解决pytesseract 找不到路径的问题。
在自己安装的pytesseract包中,找到pytesseract.py文件
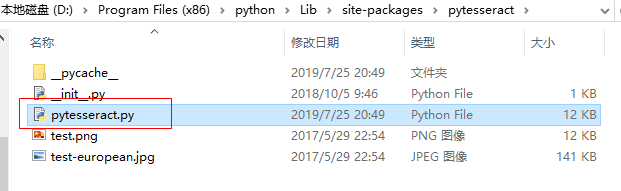
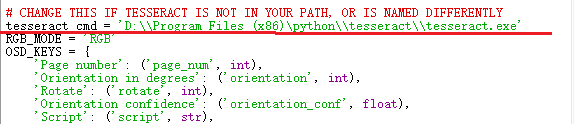
打开pytesseract.py文件,修改 tesseract_cmd 的值:tesseract.exe 的安装路径 。为了避免其他的错误,使用双反斜杠,或者斜杠
4、简单使用
import pytesseract from PIL import Image if __name__ == '__main__': text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng") print(text)
测试图片:
输出结果: 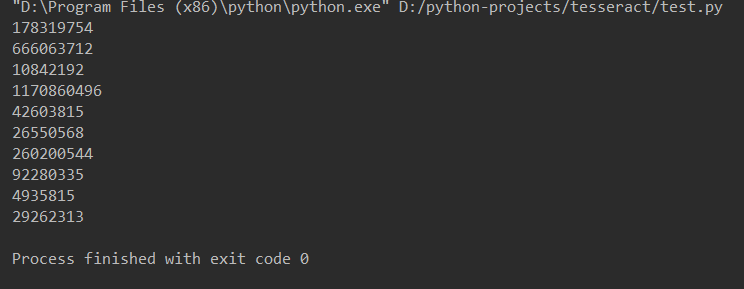
对于数字 和英文识别效果比较好,但是对于中文的识别效果不太好,可以考虑加入机器学习来进行改进。