上节我们完成了神经网络基本框架的搭建,当时剩下了最重要的一个接口train,也就是通过读取数据自我学习,进而改进网络识别效率的功能尚未实现,从本节开始,我们着手实现该功能。
自我训练过程分两步走,第一步是计算输入训练数据,给出网络的计算结果,这点跟我们前面实现的query()功能很像。第二步是将计算结果与正确结果相比对,获取误差,采购采用我们前面描述的误差反向传播法更新网络里的每条链路权重。
我们先用代码完成第一步,代码如下:
def train(self, inputs_list, targets_list):
#根据输入的训练数据更新节点链路权重
'''
把inputs_list, targets_list转换成numpy支持的二维矩阵
.T表示做矩阵的转置
'''
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, nmin=2).T
#计算信号经过输入层后产生的信号量
hidden_inputs = numpy.dot(self.wih, inputs)
#中间层神经元对输入的信号做激活函数后得到输出信号
hidden_outputs = self.activation_function(hidden_inputs)
#输出层接收来自中间层的信号量
final_inputs = numpy.dot(self.who, hidden_outputs)
#输出层对信号量进行激活函数后得到最终输出信号
final_outputs = self.activation_function(final_inputs)函数的实现跟我们在上一节对query函数的实现逻辑是一样的,不同在于它多了两个输入函数inputs_list和targets_list,这两个参数分别代表输入的训练数据,已经训练数据对应的正确结果。函数中有一点知道注意的是,我们要把输入的参数转换成numpy类型的二维矩阵,输入的inputs_list类型是二维列表,它跟二维矩阵不同,如果不转换成numpy支持的二维矩阵,那么numpy导出的很多计算函数就无法使用,例如做矩阵点乘的dot函数,举个例子:
l = [[1,2],[3,4]]
print("origin l is {0}".format(l))
ll = numpy.array(l, ndmin=2)
print(ll)l对应的就是一个二维列表,它调用numpy.array转换格式后,输出如下:

上面代码根据输入数据计算出结果后,我们先要获得计算误差,误差就是用正确结果减去网络的计算结果。在代码中对应的就是(targets - final_outputs).我们前面讲过,在误差回传时,要根据链路的权重来把误差分配给每条链路,然后节点再把由它发出的每条链路分配到的误差加总起来,例如下面网络:
中间层节点1对应的误差是两条链路分配到的误差之后,中间层节点1到最外层节点1链路会分配到一部分误差,中间层节点1和最外层节点2之间的链路会分配到一部分误差,这两部分误差合在一起就是中间层节点1的得到的误差。由此,中间层节点对应的误差就可以通过下面公式计算:

回忆一下Weight(hidden_output)矩阵格式,它是一个二维数组,对应着中间层节点到做外层节点的链路权重所组成的矩阵二维矩阵,对应于上面网络就是:
[w(11), w(21)
W(12), w(22)
]errors(output)对应于上面网络就是:
[e1,
e2
]把上面矩阵做转置后在与errors向量做点乘就是:
[ [
w(11), w(12) e1
w(21), w(22) * e2
] ]
= [w(11)*e1+w(12)*e2 , w(21)*e1 + w(22)*e2]其中w(11)*e1+w(12)*e2就是中间层节点1根据反向传播后得到的误差。当我们要改进中间层到最外层间链路权重时,我们需要output_errors,当我们要修改输入层与中间层的链路权重时,我们需要hidden_errors,相应代码实现如下:
#计算误差
output_errors = targets - final_outputs
hidden_errors = numpy.dot(self.who.T, output_errors)前面我们已经推导出链路权重更新的公式:
上面公式最前面的a对应的就是学习率,sigmoid对应的就是代码中的self.activation_function,其中的’*’表示普通数值乘法,而符号’.’表示向量乘法,计算出上面的权重更新后,原有权重要加上这个更新数值。我们用代码实现如下:
#根据误差计算链路权重的更新量,然后把更新加到原来链路权重上
self.who += self.lr * numpy.dot((output_errors * final_outputs *(1 - final_outputs)),
numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1 - hidden_outputs)),
numpy.transpose(inputs))上面代码不好理解,可以把上面代码对应到下面公式:
上图是我们以前讲过的内容,后面横着的(O1,O2…)对应代码中的numpy.transpose(hidden_outputs),其中的E1, E2 …对应的就是output_errors,而S1*(1-S1), S2*(1-S2)….对应final_outputs*(1-final_outputs)。至此网络自我训练的代码就完成了,train函数的整体代码如下:
def train(self, inputs_list, targets_list):
#根据输入的训练数据更新节点链路权重
'''
把inputs_list, targets_list转换成numpy支持的二维矩阵
.T表示做矩阵的转置
'''
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, nmin=2).T
#计算信号经过输入层后产生的信号量
hidden_inputs = numpy.dot(self.wih, inputs)
#中间层神经元对输入的信号做激活函数后得到输出信号
hidden_outputs = self.activation_function(hidden_inputs)
#输出层接收来自中间层的信号量
final_inputs = numpy.dot(self.who, hidden_outputs)
#输出层对信号量进行激活函数后得到最终输出信号
final_outputs = self.activation_function(final_inputs)
#计算误差
output_errors = targets - final_outputs
hidden_errors = numpy.dot(self.who.T, output_errors)
#根据误差计算链路权重的更新量,然后把更新加到原来链路权重上
self.who += self.lr * numpy.dot((output_errors * final_outputs *(1 - final_outputs)),
numpy.transpose(hidden_outputs))
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1 - hidden_outputs)),
numpy.transpose(inputs))
pass接下来我们就得拿实际数据来训练我们的神经网络了,在最开始时,我们曾经用MNIST数字图片来进行识别,现在我们使用一种cvs格式的数据来训练,其下载路径如下:
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetw ork/master/mnist_dataset/mnist_test_10.csv上面数据下载后格式如下:

第一个数字表示的是图片对应的数字,根据上面例子,第一个数字是7,接下来有28*28 = 768个数字,对应的其实是一张黑白图片的像素点,经过第一节的同学能看过这样的数字图片。根据链接把数据下载后,我们用代码将其读入程序中:
#open函数里的路径根据数据存储的路径来设定
data_file = open("/Users/chenyi/Documents/人工智能/mnist_test_10.csv")
data_list = data_file.readlines()
data_file.close()
len(data_list)
data_list[0]上面代码运行后结果如下:
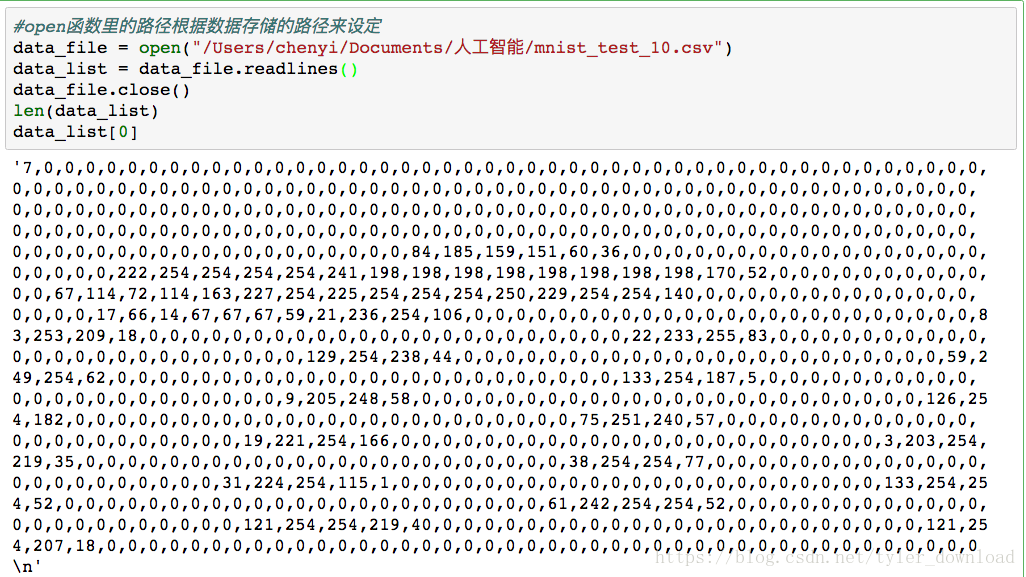
注意看,后面28*28个数值中,每个数字都不超过256,也就是数字表示的是像素点的灰度,值越大,颜色就越倾向于黑色。我们用代码把数字画出来,看看其是否真的对应一个数子:
import numpy
import matplotlib.pyplot
%matplotlib inline
#把数据依靠','区分,并分别读入
all_values = data_list[0].split(',')
#第一个值对应的是图片的表示的数字,所以我们读取图片数据时要去掉第一个数值
image_array = numpy.asfarray(all_values[1:]).reshape((28, 28))
matplotlib.pyplot.imshow(image_array, cmap='Greys', interpolation='None')数据读入时,每个数字其实都是字符,asfarray把all_values里面的数字字符全部转换成浮点数,reshape((28,28)),把含有768个元素的all_values列表转换成28行28列的二维数组,上面代码运行后结果如下:
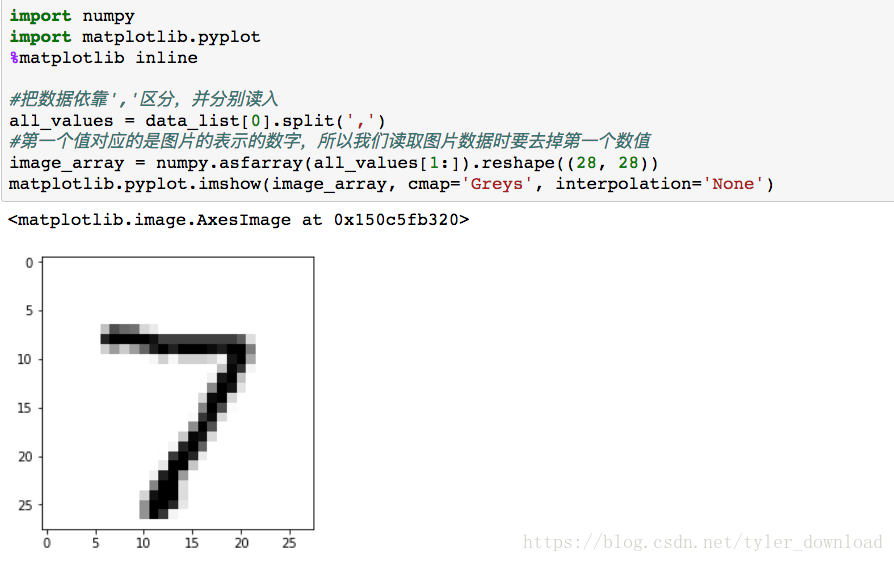
从绘制的结果看,数据代表的确实是一个黑白图片的手写数字。数据读取完毕后,我们再对数据格式做些调整,以便输入到神经网络中进行分析。我们需要做的是将数据“正规化”,也就是把所有数值全部转换到0.01到1.0之间,由于表示图片的二维数组中,每个数大小不超过255,由此我们只要把所有数组除以255,就能让数据全部落入到0和1之间,有些数值虽然很小,除以255后会变为0,这样会导致链路权重更新出问题,所以我们需要把除以255后的结果先乘以0.99,然后再加上0.01,这样所有数据就处于0.01到1之间。代码实现为:
scaled_input = image_array / 255.0 * 0.99 + 0.01
print(scaled_input)上面代码运行后结果如下:
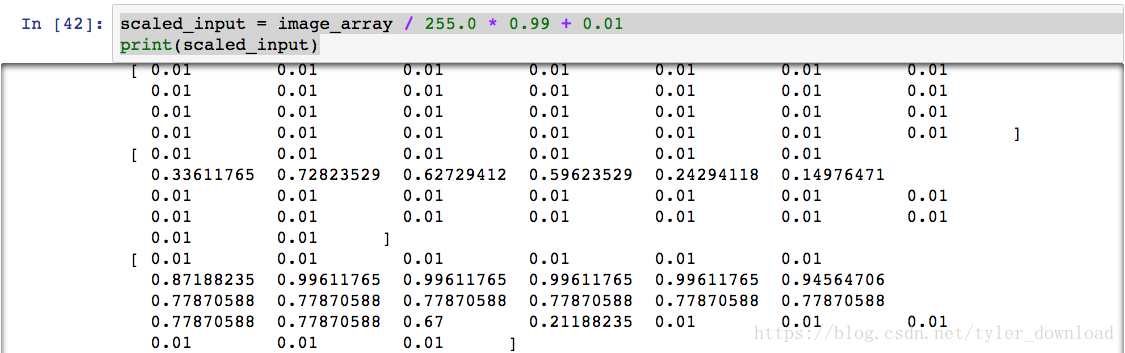
从下节开始,我们把处理好的数据传入网络,看看它是怎么从数据中学习,最终能练就识别手写数字图片的能力的。