基于皮尔森相关性的相似度 —— Pearson correlation-based similarity
皮尔森相关系数反应了两个变量之间的线性相关程度,它的取值在[-1, 1]之间。当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
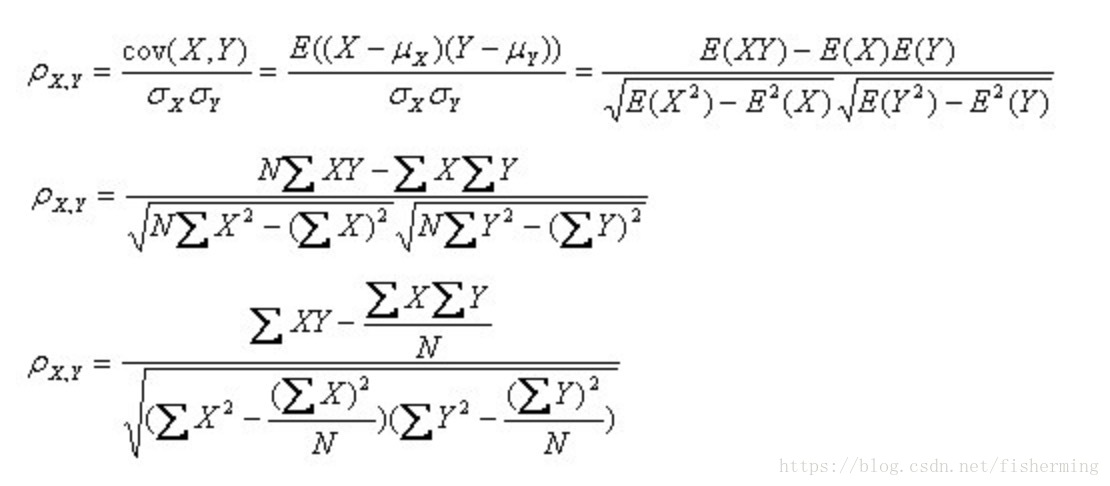
协方差(Covariance):在概率论和统计学中用于衡量两个变量的总体误差。如果两个变量的变化趋于一致,也就是说如果其中一个大于自身的期望值,另一个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,则协方差为负值。
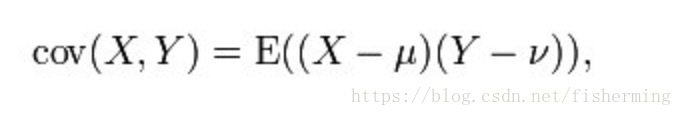
其中u表示X的期望E(X), v表示Y的期望E(Y)
标准差(Standard Deviation):标准差是方差的平方根

方差(Variance):在概率论和统计学中,一个随机变量的方差表述的是它的离散程度,也就是该变量与期望值的距离。
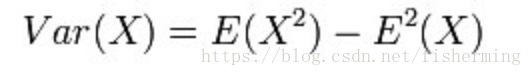
即方差等于误差的平方和的期望
基于皮尔森相关系数的相似度有两个缺点:
(1) 没有考虑(take into account)用户间重叠的评分项数量对相似度的影响;
(2) 如果两个用户之间只有一个共同的评分项,相似度也不能被计算
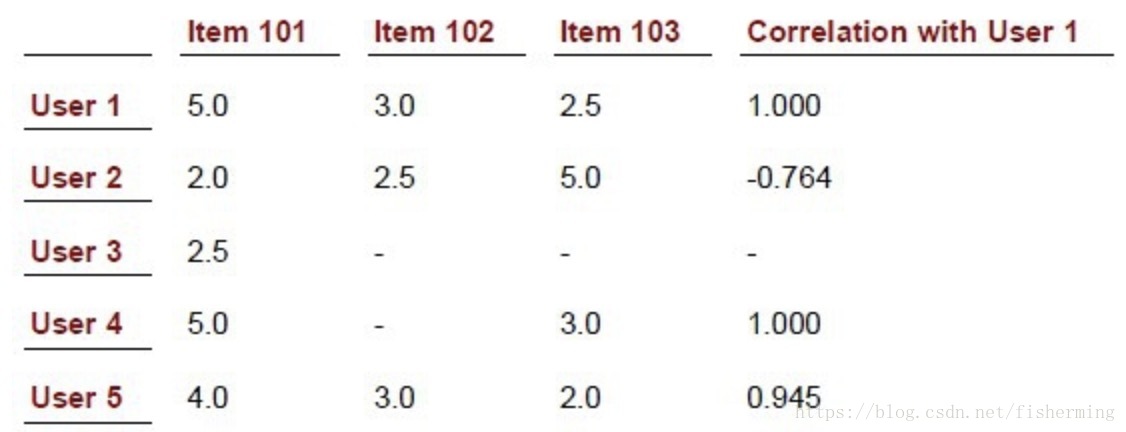
上表中,行表示用户(1~5)对项目(101~103)的一些评分值。直观来看,User1和User5用3个共同的评分项,并且给出的评分走差也不大,按理他们之间的相似度应该比User1和User4之间的相似度要高,可是User1和User4有一个更高的相似度1。
同样的场景在现实生活中也经常发生,比如两个用户共同观看了200部电影,虽然不一定给出相同或完全相近的评分,他们之间的相似度也应该比另一位只观看了2部相同电影的相似度高吧!但事实并不如此,如果对这两部电影,两个用户给出的相似度相同或很相近,通过皮尔森相关性计算出的相似度会明显大于观看了相同的200部电影的用户之间的相似度。