参考
匈牙利算法可以用来解决在二分图中最大匹配的问题。这里参考了几位大佬的博客。代码主要是参考Renfei Song大佬的。
Renfei Song’s Blog – 二分图的最大匹配、完美匹配和匈牙利算法
zxfx100 – Hungary
willinglive –【hall定理】一个关于二分图的问题
神犇(shenben) – 匈牙利算法(二分图)
DarkScope从这里开始 – 趣写算法系列之–匈牙利算法7
二分图中的匹配
这里有几个概念先要列一下, 当然我这里就是通俗的解释一下,精确的定义可以看Renfei Song DA LAO’s Blog
- 二分图–大概就是一个图里面节点分成两个部分V1和V2,且只存在V1与V2之间的边。
- 二分图匹配–通俗一点理解就是,V1,V2的点,配成一对对的。
- 最大匹配–就是最大的匹配,能配出最多对。
- 完美匹配–所有的点都可以找到另一半,(当然这个就是可遇不可求了。
- 交替路–假设我们在途中已经找到了一组匹配,那么从一个非匹配点钟出发依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。
- 增广路径–从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。这里直接截的图,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出):
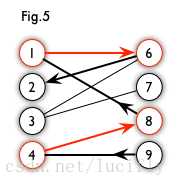
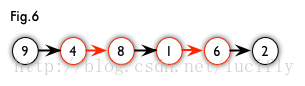
如果在二分图中能找到一条增广路径,那么我们把增广路径中匹配边和非匹配边互换一下就可以增加一个匹配了。这就是匈牙利算法的基本思想。
匈牙利算法
匈牙利算法基本思想就是遍历整个图,然后找出所有的增广路径,找出一条就说明匹配可以加一。找出所有的就可以了。
图的遍历有两种方式,深度优先DFS 和广度优先BFS。复杂度都是O(V*E),DFS用递归比较好实现。
代码还是大佬写的,我加了些注释。觉得看不明白的,可以去原博客看看。
首先定义下,
数据结构
主要是邻接表存的图。
// 顶点、边的编号均从 0 开始
// 邻接表储存
struct Edge
{
int from;
int to;
int weight;
Edge(int f, int t, int w):from(f), to(t),weight(w){}
};
vector<int> G[__maxNodes];
/* G[i] 存储顶点 i 出发的边的编号 */
vector<Edge> edges;
typedef vector<int>::iterator iterator_t;然后是
DFS的算法
int matching[__maxNodes];
/* 存储求解结果 */
int check[__maxNodes];
//存储这个节点在一次查找中有没有被遍历过
bool dfs(int u)
{
for(iterator_t i = G[u].begin(); i != G[u].end(); ++i)
{ // 对 u 的每个邻接点
int v = edges[*i].to;
if (!check[v])
{ // 要求不在交替路中
check[v] = true;
// 放入交替路
if (matching[v] == -1 || dfs(matching[v])) //检查v是不是未配对的,如果v不是,看看v腾一腾能不能腾出来
//v并不会找到和他已经匹配的u,因为如果这么找的话,下一层递归会返回FALSE
//所以最后会形成交替路
{
// 如果是未盖点,说明交替路为增广路,则交换路径,并返回成功
matching[v] = u;
matching[u] = v;
return true;
}
}
}
return false;
// 不存在增广路,返回失败
}
int hungarian()
{
int ans = 0;
memset(matching, -1, sizeof(matching)); //初始化
for (int u=0; u < num_left; ++u) //这个num_left 应该是二分图里面左边点的数量
{
if (matching[u] == -1)
{
memset(check, 0,sizeof(check));
if (dfs(u))//深度遍历 查找加入 u 节点之后能否 再新加一条路径
// 传入u节点之后 一直递归 看能否在现有基础上腾一个 空闲的节点出来
//能的话 配对加一
++ans;
}
}
return ans;
}DFS就是利用增广路径的特性,为每个节点找到配对的点。核心是if (matching[v] == -1 || dfs(matching[v])),如果u可以和v配对,则直接返回;如果v已经有配对了,那么试试看能不能让v的对象另外再找个点配对,将v腾出来。然后一直递归下去。
BFS的算法
BFS遍历可以生成一颗匈牙利树,如下图。

queue<int> Q;
//Q队列,用来进行广度优先遍历
int prev[__maxNodes];
int Hungarian()
{
int ans = 0;
memset(matching, -1, sizeof(matching));
memset(check, -1, sizeof(check));
for (int i=0; i<num_left; ++i)
{
if(matching[i] == -1)
{
while (!Q.empty())
Q.pop();
Q.push(i);
prev[i] = -1; // 设 i 为路径起点
bool flag = false; // 尚未找到增广路
while (!Q.empty() && !flag)
{
int u = Q.front();
for (iterator_t ix = G[u].begin(); ix != G[u].end() && !flag; ++ix)
{
int v = edges[*ix].to;
if (check[v] != i)
{
check[v] = i;
Q.push(matching[v]);
//这里将matching[v]入队,如果matching[v]是-1的话,会直接进入下面的else,即 flag会变成true,到时候循环直接退出,-1也会被弹出。
//当matching[v]有值时,表示这个节点可以出现在树的下一层,所有加入到层序遍历队列中
if (matching[v] >= 0)
//u可以和v配对,但是v已经有对象了,将u作为备胎记录下来
{ // 此点为匹配点
prev[matching[v]] = u;
//prev数组中存对应下标的点的备胎
}
else
{ // 找到未匹配点,交替路变为增广路
flag = true;
int d=u,e=v;
while(d != -1)
{
//u原来是和t配对的,但是现在u甩了t和v配对
//所有t去找备胎配对
//依次循环下去
int t = matching[d];
matching[d] = e;
matching[e] = d;
d = prev[d];
e = t;
}
}
}
}
Q.pop();
}
if (matching[i] != -1)
++ans;
}
}
return ans;
}看每新加入一个节点能不能形成新的增广路径。方法就是,以新加入的节点为根节点,生成匈牙利树,看是否能找到未匹配的叶子结点。如果有就说明加入当前节点后可以形成一条增广路径,及配对数加一。