参考文献:
[1] Cheng R , Gen M , Tsujimura Y . A tutorial survey of job-shop scheduling problems using genetic algorithms—I. representation[J]. Computers and Industrial Engineering, 1996, 30(4):983-997.
最近在看一些启发式算法求解经典问题的论文,发现几篇比较新的文献中对于合法解和可行解的定义有一些区别,想起来之前研究JSP时在文献[1]中看到了对于这两个名词的详细解释,又回头去翻了一遍。以免自己忘记,把自己的一些理解写下来,由于刚开始这一方面的学习,理解不一定准确。
文中对合法解与可行解的定义是围绕GA进行的,但我认为这一定义适用于所有启发式算法求解优化问题,因为在计算机实现算法的过程中,对于所有问题,都需要考虑解的编码与解码。编码指的是将问题中的解表现为一个数据结构(或者一个类),解码是指将前面那个数据结构(类)中保存的相关信息还原为一个解。因此对于解组成的解空间,会有一个对应的,由解空间中每个解的编码组成的编码空间。
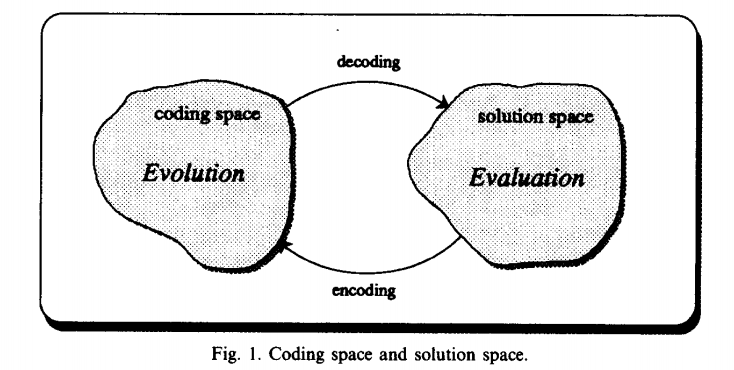
放一张论文中的图,论文中的原话大概是“遗传算法的一个基本特征是它交替作用于编码空间和解空间:进化作用于编码空间(染色体),而评价作用于解空间,自然选择则联系了染色体与其解码解的性能” 。将这一思想从GA扩展到启发式算法,我的理解是:各类启发式算法(如局部搜索,禁忌,模拟退火,群体算法)在生成初始解,对初始解改进的过程中就是在编码空间中操作,具体这一改进好不好,则要转回解空间中进行评价,因此启发式算法也是交替作用于编码空间和解空间的。
论文中接着提到GA的一个关键问题是如何将解编码成染色体,这涉及到染色体的可行性,染色体的合法性,映射的唯一性。此处我们不考虑映射的唯一性,前两条对应到启发式算法中就是:编码的可行性,以及编码的合法性。
可行性是指这段编码所解码出的解是否位于给定问题的可行域。合法性是指一个编码是否代表一个给定问题的解决方案。这两句话比较抽象,根据论文中的一些描述我的理解如下。
以这篇论文中探讨的JSP的解为例:
编码的不可行性来源于约束优化问题的性质。比如对于一个有3道工序,按顺序在机器1,2,3上执行的工件来说,产生的编码给它安排为3,2,1的顺序,此时得到的解不满足约束,但通过修改约束中工件的加工顺序(由原来的1,2,3改为3,2,1)可以解决不满足约束的问题,此时编码的冲突来源于约束优化问题的性质,是不可行的。
编码的非法性来源于编码技术的本质,非法编码无法解码为解。比如一个3工件,3机器,3工序的问题,在对解采取基于工序的编码方式时,每个工件的3道工序分别依次在3台机器上进行,此时启发式算法在搜索过程中(不论是GA的杂交变异或LS算法),如果产生一个编码形如1,2,3,2,2,2,3,1,1,工件2出现4道工序,则这个编码无法解码为一个合理的策略,此时认为这个编码是非法的。
根据论文中的观点,下图中展示了它们的关系。
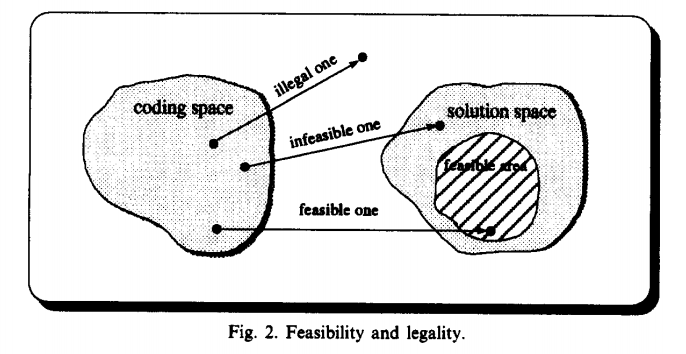
可以看到,编码空间中的编码,包含非法,不可行与可行三种情况。非法编码根本无法解码为一个解,因此它解码后的内容不包含在解空间中。解空间中包含不可行解和可行解,它们的区别主要是不可行解在一定程度上不满足问题的约束条件,而可行解一定是满足约束条件的。
以上是我自己对于合法解与可行解这两个概念的理解,不一定对。