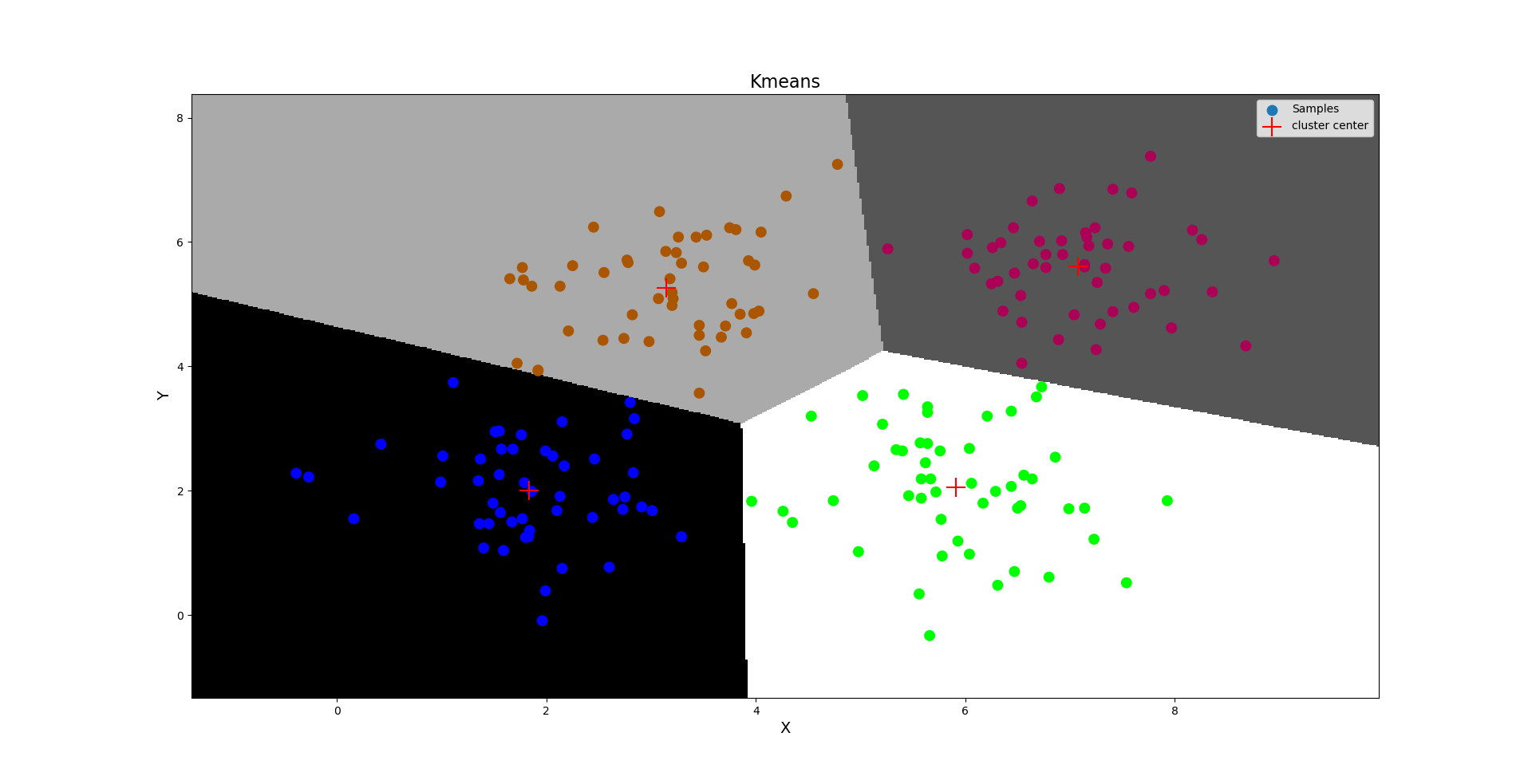
''' 聚类:分类(class)与聚类(cluster)不同,分类是有监督学习模型,聚类属于无监督学习模型。 聚类讲究使用一些算法把样本划分为n个群落。一般情况下,这种算法都需要计算欧氏距离。(用两个样本对应特征值之差的平方和之平方根, 即欧氏距离,来表示这两个样本的相似性) 1.K均值算法: 第一步:随机选择k个样本作为k个聚类的中心,计算每个样本到各个聚类中心的欧氏距离, 将该样本分配到与之距离最近的聚类中心所在的类别中。 第二步:根据第一步所得到的聚类划分,分别计算每个聚类的几何中心,将几何中心作为新的聚类中心, 重复第一步,直到计算所得几何中心与聚类中心重合或接近重合为止。 注意: 聚类数k必须事先已知。借助某些评估指标,优选最好的聚类数。 聚类中心的初始选择会影响到最终聚类划分的结果。初始中心尽量选择距离较远的样本。 K均值算法相关API: import sklearn.cluster as sc # n_clusters: 聚类数 model = sc.KMeans(n_clusters=4) # 不断调整聚类中心,直到最终聚类中心稳定则聚类完成 model.fit(x) # 获取训练结果的聚类中心 centers = model.cluster_centers_ 案例:加载multiple3.txt,基于K均值算法完成样本的聚类。 步骤: 1.读取文件,加载数据,把样本绘制在窗口中 2.基于K均值完成聚类业务,为每个样本设置颜色 3.绘制聚类背景边界线----pcolormesh ''' import numpy as np import matplotlib.pyplot as mp import sklearn.cluster as sc # 读取数据,绘制图像 x = np.loadtxt('./ml_data/multiple3.txt', unpack=False, dtype='f8', delimiter=',') print(x.shape) # 基于Kmeans完成聚类 model = sc.KMeans(n_clusters=4) model.fit(x) # 完成聚类 pred_y = model.predict(x) # 预测点在哪个聚类中 print(pred_y) # 输出每个样本的聚类标签 # 获取聚类中心 centers = model.cluster_centers_ print(centers) # 绘制分类边界线 l, r = x[:, 0].min() - 1, x[:, 0].max() + 1 b, t = x[:, 1].min() - 1, x[:, 1].max() + 1 n = 500 grid_x, grid_y = np.meshgrid(np.linspace(l, r, n), np.linspace(b, t, n)) bg_x = np.column_stack((grid_x.ravel(), grid_y.ravel())) bg_y = model.predict(bg_x) grid_z = bg_y.reshape(grid_x.shape) # 画图显示样本数据 mp.figure('Kmeans', facecolor='lightgray') mp.title('Kmeans', fontsize=16) mp.xlabel('X', fontsize=14) mp.ylabel('Y', fontsize=14) mp.tick_params(labelsize=10) mp.pcolormesh(grid_x, grid_y, grid_z, cmap='gray') mp.scatter(x[:, 0], x[:, 1], s=80, c=pred_y, cmap='brg', label='Samples') mp.scatter(centers[:, 0], centers[:, 1], s=300, color='red', marker='+', label='cluster center') mp.legend() mp.show() 输出结果: (200, 2) [0 0 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 2 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 3 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 0 3 1 0 2 3 1 0 2 3 2 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1 0 2 3 1] [[1.831 1.9998 ] [7.07326531 5.61061224] [3.1428 5.2616 ] [5.91196078 2.04980392]]
''' Kmeans使用场景----图像量化:KMeans聚类算法可以应用于图像量化领域。通过KMeans算法可以把一张图像所包含的颜色值进行聚类划分, 求每一类别的平均值后再重新生成新的图像。可以达到图像降维的目的。这个过程称为图像量化。 图像量化可以更好的保留图像的轮廓,降低机器识别图像轮廓的难度。 n_clusters=2类似于二值化 将百合花图片进行图像量化: 步骤: 1.读取图片的亮度矩阵 2.基于KMeans算法完成聚类,获取4个聚类中心的值 3.修改图片,将每个像素亮度值都改为相应类别的均值(即聚类中心值) 4.绘制图像 ''' import numpy as np import matplotlib.pyplot as mp import sklearn.cluster as sc import scipy.ndimage as sn import scipy.misc as sm import warnings warnings.filterwarnings('ignore') img = sm.imread('./ml_data/lily.jpg', True) print(img.shape) # 基于KMeans完成聚类 model = sc.KMeans(n_clusters=2) x = img.reshape(-1, 1) # n行1列 print(x.shape) model.fit(x) # 同model.predict(x) 返回每个样本的类别标签 y = model.labels_ print(y.shape) centers = model.cluster_centers_ print(centers.shape) img2 = centers[y].reshape(img.shape) print(img2.shape) # 绘图 mp.subplot(121) mp.imshow(img, cmap='gray') mp.axis('off') # mp.subplot(122) mp.imshow(img2, cmap='gray') mp.axis('off') # 关闭坐标轴 mp.show() 输出结果: (512, 512) (262144, 1) (262144,) (2, 1) (512, 512)
