索引的作用:
首先索引通俗来讲就像书的目录,通过索引可以快速查找对应数据,但这仅仅是表面上的,索引主要作用有3点,这仅仅算作其中1点。以下是鄙人的理解:
- 通过索引可以减少数据的扫描量(例如上面提到的将全书扫描,变成了根据目录找)
- 索引可以把对硬盘的随机IO变为顺序IO()
- 索引可以在排序、分组等操作时避免创建临时表()
详细展开来:
mysql数据库索引的数据结构是B+树。什么是B+树?
如果不是很了解树的同学可以来到这里可视化构建树,选择对应的数据结构就可以了,我这里的动图也是从这来的。
上面博客中对树的概念讲的比较详细了,下面补充一下关于索引的选择,mysql为什么选择B+树(推荐与上面两个链接一起阅读):
为什么不用简单的二叉树:
二叉树存在着这么样一个弊端:在极端情况,他会成为一个链表,导致性能急剧下降。特制作一动图供大家更好的理解:

从动图中可以看出,如果数据完全顺序插入(比如索引的主键开启了自增)会导致成为一个链表一样的数据结构,查找时候有可能演变为全表扫描,查找动图如下:

于是我们想把它优化一下,调整为平衡一点的二叉树(叶子节点的高度差<=1)
平衡二叉树动图:

为什么不使用平衡二叉树(二路平衡查找树):
我们知道数据库中是存储数据的,数据量经常会达到百万以上的级别,这时候的平衡二叉树虽然解决了二叉树的极限情况,但对于大数据来讲,他的高度可能成百上千高度。
这里补充一下数据库有索引时查找数据的过程:
mspaint画了个简单的图片,如果用平衡二叉树存储,假设主键索引存储如下图

如果要找主键为13的数据,需要把10经过磁盘IO读到内存中,来对比,发现13>10,然后根据10的right值再进行一次IO拿到22,,对比发现13<22,然后根据22的left值再进行一次IO拿到13,发现13==13,则拿到4080,再从硬盘去读。
这是软件的过程,但我们知道,计算机底层是磁盘,磁盘IO是非常耗费时间的,而磁盘读的时候一般是读取4k的数据,我们一次IO读取了4k数据(4k这里大家自行补充硬件知识,玩过固态硬盘的朋友都知道4k应该,不知道的朋友自行百度,点这里可以查看硬盘的底层原理),却只拿到1个索引的值,这是非常不划算的,而且是非常慢的,因此,平衡二叉树满足不了我们对大数据的快速访问。
总结平衡二叉树不能作为索引的两个主要原因:
- 高度太高 导致IO次数太多
- 单节点存储的数据个数太少 导致IO次数变多
解释:不能很好地利用磁盘特性(一次读4k ),也没有利用到磁盘的预读(关于磁盘IO点这里)
如果我们一次磁盘IO可以获得多个索引的值,那效率就大大提高了,于是来到了B树(多路平衡查找树)的概念。
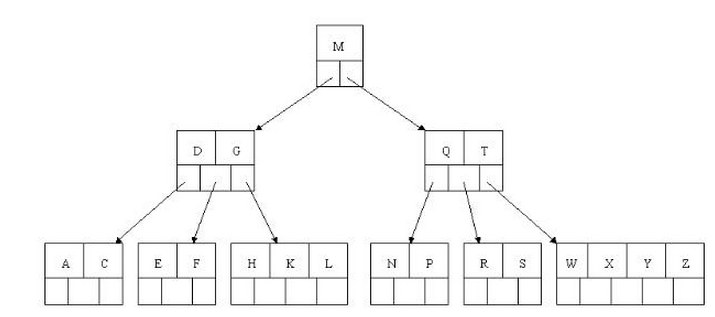
(图片来自博客,图仅供参考)
如果用B树存储A-Z则只需要3层即可,而平衡二叉树则需要6层,这样就减少了一般的IO次数,查找效率翻倍
为什么不用B树(多路平衡查找树)
B树相比平衡二叉树大大减少了高度,也增加了单个节点上的数量,看起来已经非常不错了,是的,但我们数据库select操作时,很多时候不是select一条数据,而是多条数据,引来了B+树的概念,如下
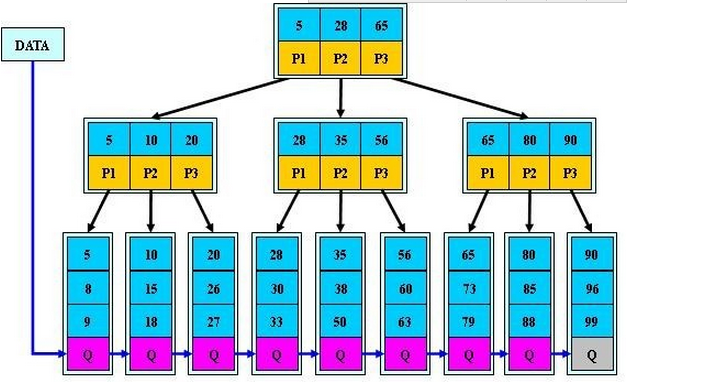
(图片来源博客)
B+树和B树相比,所有的数据只存在于叶子节点中,非叶子节点不存储数据,且所有叶子节点为顺序链表,以便扫描。
B树的节点中存放了一定数据,B+树的查找区间为左闭右开区间,如上图中查找索引值为5的数据时,在根节点有三个区间:[5,28)[28,65)[65,∞),第一个区间包含5,但是非叶子节点不存储数据地址,继续往左找,来到[5,10)[10,20)[20,∞),继续往左找来到叶子节点,发现有5,则找到。
B+树对比B树的优势有:
- 拥有B树的优势
- 由于叶子节点的链表,扫表能力更强
- 节点的结构不同,磁盘读写能力更强
- 每次查询都会来到叶子节点,磁盘IO时间固定,查询效率稳定,准确统计和排查系统问题
- 排序能力更好
当然这些好处不是白来的,而是牺牲了不稳定的快速查找(比如上述查找5的例子提到的,B树在根节点就返回了,而B+树无论什么索引值,都一定要到叶子节点才返回),但同样因为这儿,也会能够更准确统计和排查系统问题 。