netCDF全称是network Common Data Format(网络通用数据格式),是由美国大学大气研究协会(University Corporation for Atmospheric Research,UCAR)的Unidata项目科学家针对科学数据的特点开发的,是一种面向数组型并适于网络共享的数据的描述和编码标准。目前,NetCDF广泛应用于大气科学、水文、海洋学、环境模拟、地球物理等诸多领域。
我们使用python对数据进行分析处理,首先我们需要下载安装netCDF4包,可使用pip一键安装。

此外我们还要用到python中numpy这个数据处理包,安装完成之后我们就可以着手处理数据。这里导入os包是为了处理当前目录下的NC文件。
netCDF文件的数据格式

(图摘自百度百科)
我们重点看第一个特点:自描述性。为什么NC文件具有自描述性?不像一般的数据集,里面只装有纯数据值,NC文件主要用于气象,天文,海洋学等方面,它含有的值都对应着现实世界中的某个变量,结构较为复杂,所以它内部所含有的数据不仅仅是值的集合,它还需要告诉读取它的人自己包含什么样的数据(变量Variable),这些数据在现实世界中代表什么(属性Attribute),以及数据的值依赖于什么(维度Dimension)。
举个例子,假如我们要表示某海洋内部的水压(Pressure)和温度(Temperature),这时Pressure就是变量Variable,为了得到它的值,我们需要提供如下信息:海洋坐标对应的经纬度(Longitude,Latitude),水深(Depth),若更确切的话可能还有时间(Time),这些就是数据Pressure的维度,即Pressure = f(longitude, latitude, Depth, Time),是个四维的变量。Pressure的属性即是"Pa"(压力单位,Pressure:unit = "Pa")。而它的维度值从何处得来呢?实际上,每个维度在NC文件中也是一个变量,例如Depth,它是个一维的变量,相当于一个数组,通过索引可以提取它的值。同样它也有自己的属性——Depth:unit="m"(米)。
实际上NC文件它本身还含有关于自己的属性,例如该文件各变量的取值范围,文件的来源,文件的历史信息,文件的版权声明等等,都可以写进去,所以我们说,NC文件具有自解释性。搞清楚了NC文件的结构格式,我们可以开始进行数据的提取。
关于如何获取NC文件的内部信息,我们使用到了python中的netCDF4包来读取:

Dataset即是netCDF4包中提供的读取NC文件的接口,此时我们就拥有了一个数据集,进而查看数据集中的各种信息。

通过调用Dataset提供的各种API可以查看数据集的各种信息,这里输出了NC文件的属性信息:

查看NC文件中变量以及它们的属性:

输出(节选为salinity的输出):
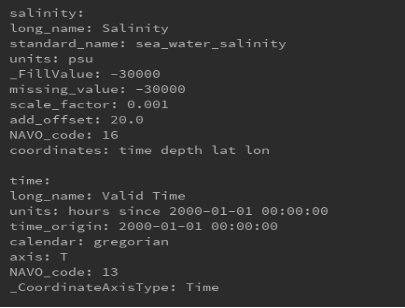
可见NC对于变量解释的还是十分详细的。
我们需要提取变量salinity的值,我们可以看到它的最后一个属性coordinates有四个值——(time, depth, lat, lon), 即四维属性。随后我们需要查看这四个变量的信息。
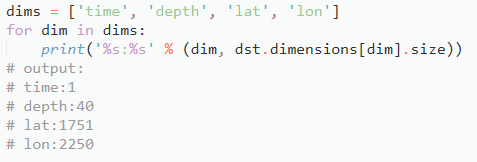
这里输出的是这四个变量的域,可见time只有一个值,类似于标量。
然后输出维度所对应变量的值域,这里只显示了前五个值(实际上depth是40大小,应该有40个值):
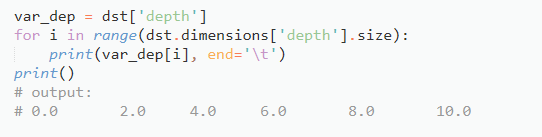
这里需要重点解释一下—,如何通过维度取到变量的值。例如我们看到变量depth是个一维的变量,我们就可以把它看成一维数组,即Depth[0:5] = [0.0, 2.0, 4.0, 6.0, 8.0, 10.0],以变量salinity这个四维变量为例,我们已经知道salinity = f(time, depth, longitude, latitude)。现在假设其它三个变量的取值范围如下:
- time = [t1]
- longitude[0:5] = [long1, long2, long3, long4, long5]
- latitude[0:5] = [lat1, lat2, lat3, lat4, lat5]
为了提取变量salinity对应的值,我们需要这样:
- dst["salinity"][0][0][0][0]; # 提取时间t1,深度0.0m,经度long1,纬度lat1的盐度值
- dst["salinity"][0][2][3][4]; # 提取时间t1, 深度4.0m,经度Long4,纬度lat5的盐度值
注意这里数组的索引并不就代表了其所表示维度的值,它们表示的是——该维度取值范围的第N个值(N为索引),所以我们需要查看每个维度的取值范围,并取得他们的索引范围,然后才能利用这个索引范围提取所需数据。
综上所述,处理数据的大致过程是:
- 查看NC文件信息,获取要提取的数据范围
- 通过各个维度的信息,得到索引范围
- 利用for循环读取数据
csv文件的转化
我们还需要一个python包来完成任务,就是pandas包(不是熊猫的意思,是python data analysis 的缩写),它内部有个DataFrame结构,可以很方便的将读取后的数据转化为csv文件结构:

这里的arr就是经过循环处理后得到的numpy数组(Numpy.asarray(...)可以将普通数组转换为pandas能接受的数组),column是csv文件的列名信息。事实上也可以很方便的转化为json文件,如图所示。
展示一下结果:
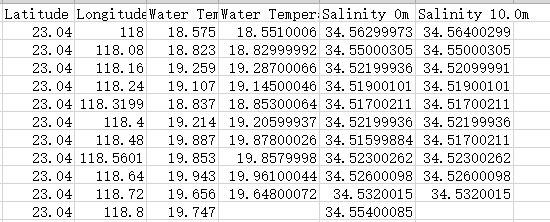
列名为自行规定的,空值是由于数据文件缺失值,属正常现象,可以自己采用插值方法来填补空白。