前言
作为一个技术宅,本着为眼睛着想的角度考虑,能少看屏幕就尽量少看屏幕,可是又是一个小说迷,那就开动脑筋爬一下小说转换成语音来听书吧
第一章:爬取小说文件
把目标定在小说存储量比较大的网站:起点中文网 传送门
爬虫本来就是要爬取全部,但是想想那量是有点大啊,所以想想加了两行代码,使得用户可以选择你需要的小说,当然也可以全部爬下来,上代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/12/30 23:20
# @Author : Fang
# @E-mail : [email protected]
# @Site :
# @File : qidian.py
# @Software: PyCharm
import requests
# from lxml import etree
import os
import python_baidu_api #语音转换模块,在后面会讲,请先注释掉,否则报错
## python3.7 有点坑啊,装了lxml模块却没有etree,后来查资料用以下方法即可导入使用
import lxml.html
etree = lxml.html.etree
class Spider(object):
def start_request(self):
response = requests.get("https://www.qidian.com/all")
html = etree.HTML(response.content.decode())
Bigtit_list=html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
Bigsrc_list=html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
# print(Bigsrc_list)
book_name = input("请输入您要爬取的书名(eg:凡人修仙传之仙界篇):")
for Bigsrc,Bigtit in zip(Bigsrc_list,Bigtit_list):
if Bigtit in book_name or book_name in Bigtit:
if os.path.exists(Bigtit) == False:
os.mkdir(Bigtit) ##创建以小说名为名字的文件夹存储小说
print("目标文件夹已创建")
self.xpath_data(Bigsrc,Bigtit)
def xpath_data(self,Bigsrc,Bigtit):
response = requests.get("https:"+Bigsrc)
html = etree.HTML(response.content.decode())
Littit_list = html.xpath('//ul[@class="cf"]/li/a/text()')
Litsrc_list = html.xpath('//ul[@class="cf"]/li/a/@href')
for Litsrc,Littit in zip(Litsrc_list,Littit_list):
self.finally_file(Littit,Litsrc,Bigtit)
def finally_file(self,tit,url,Bigtit):
response = requests.get("http:"+url)
html = etree.HTML(response.content.decode())
content = "\n".join(html.xpath('//div[@class="read-content j_readContent"]/p/text()'))
file_name = Bigtit + "\\" + tit +".txt"
audio_name = Bigtit + "\\" + tit +".mp3" #语音文件名称
print("正在抓取文章:" + file_name)
with open(file_name, "a", encoding="utf-8") as f:
f.write(content)
python_baidu_api.convert(file_name,audio_name) #调用转语音模块进行转换
if __name__ == '__main__':
spider=Spider()
spider.start_request()
如果不需要转语音功能,请注释掉以下两行语音转换的代码即可爬取小说txt文件
import python_baidu_api #语音转换模块,在后面会讲,请先注释掉,否则报错
python_baidu_api.convert(file_name,audio_name) #调用转语音模块进行转换
第二章:文字转语音
这一步需要去百度ai开放平台 语音合成注册使用,可以先免费试用,获得APPID AK SK,填入以下代码的 APPID AK SK 对应位置,我的这里就不公开了,代码里面以xxx代替,请读者申请之后自行替换
在当前文件夹下再创建一个 python_baidu_api.py 文件,即刚刚导入的语音模块。里面的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/12/30 22:53
# @Author : Fang
# @E-mail : [email protected]
# @Site :
# @File : python_baidu_api.py
# @Software: PyCharm
from aip import AipSpeech
import os
#这里的xxx请替换成你自己的 APPID AK SK
APP_ID = 'xxx'
API_KEY = 'xxx'
SECRET_KEY = 'xxx'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def convert(file,audio_name):
with open(file,"r",encoding="utf-8") as file_object:
contents = file_object.read()
print("正在转换{}".format(file))
while len(contents)>=2000:
tmp = contents[:2000]
result = client.synthesis(tmp,"zh",1,{
"vol":5, #音量,取值0-15,默认为5中音量
"spd":4, # 语速,取值0-9,默认为5中语速
"pit":9, # 音调,取值0-9,默认为5中语调
"per":3, # 发音人选择, 0为女声,1为男声,3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女
})
contents = contents[2000:]
# with open("{}.mp3".format("./txtaudio/{}".format(file)),"wb") as f:
try:
with open("{}.mp3".format(audio_name),"ab") as f:
f.write(result)
print("{}转换完成".format(audio_name))
except:
print("error")
if __name__ == '__main__':
convert(file,audio_name)
到这里就可以合成语音了,回到刚才写的第一个py文件里,运行它:
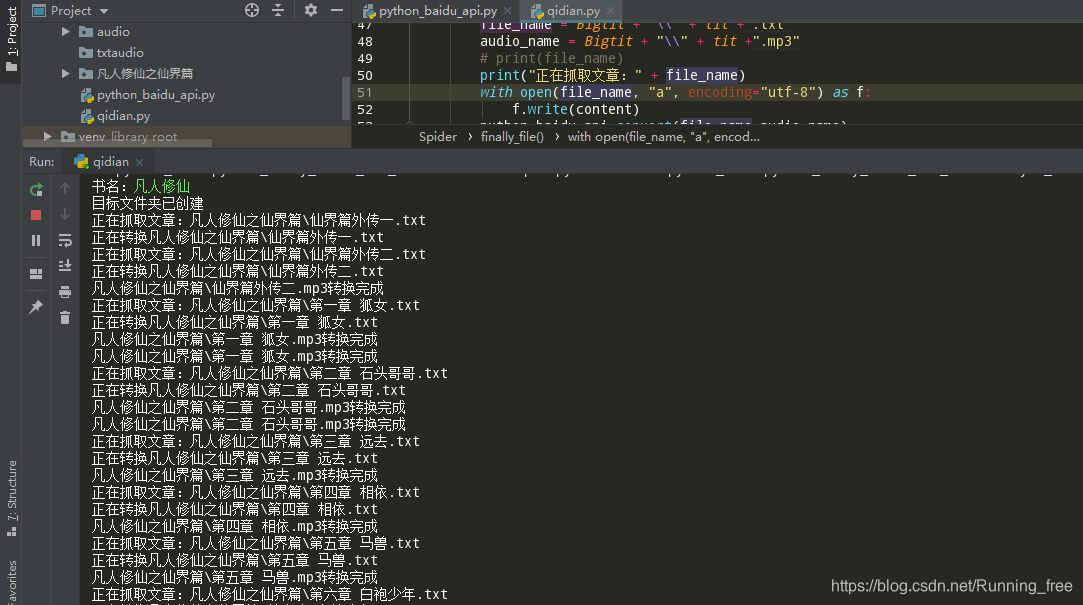
每一个txt对应一个mp3文件
接下来就可以用耳朵享受小说了
